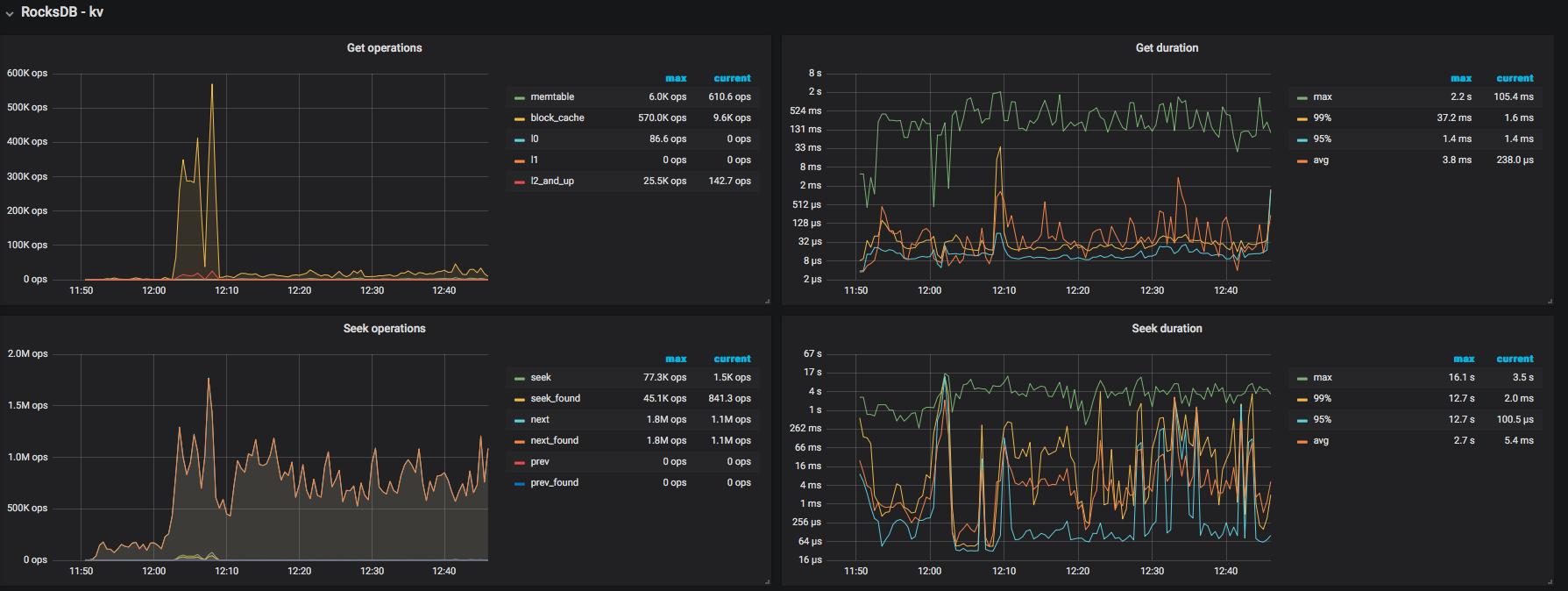
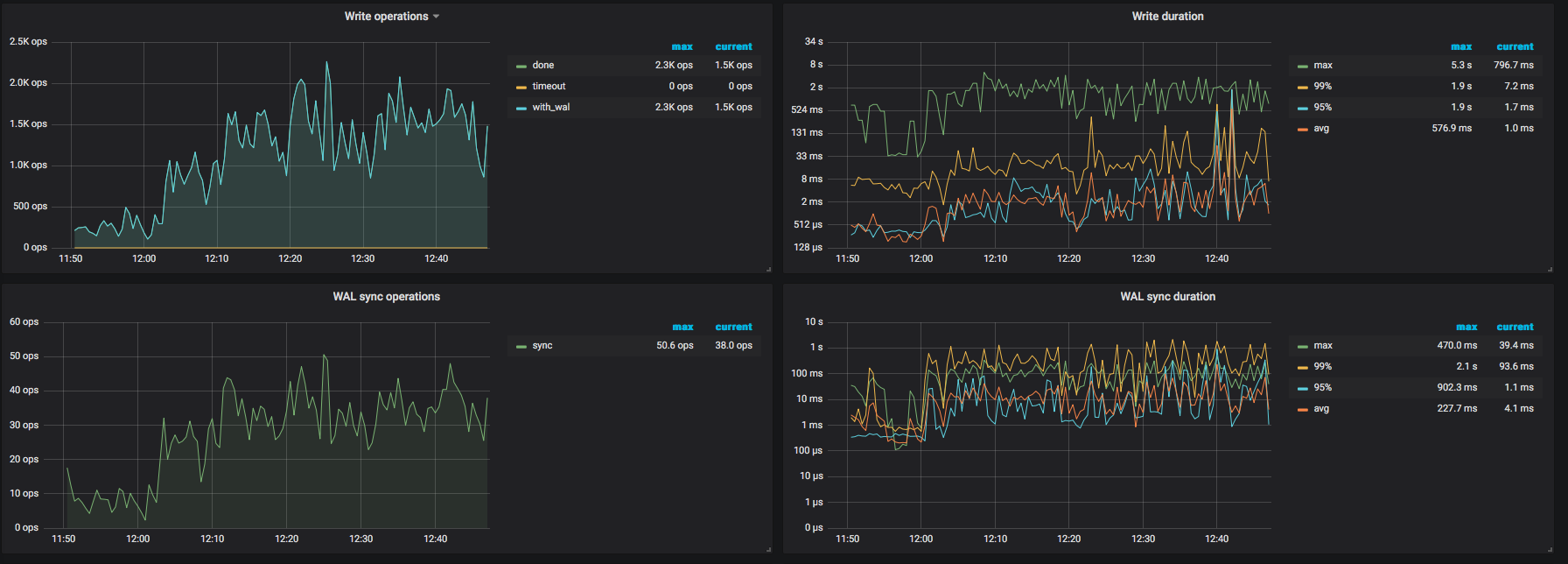
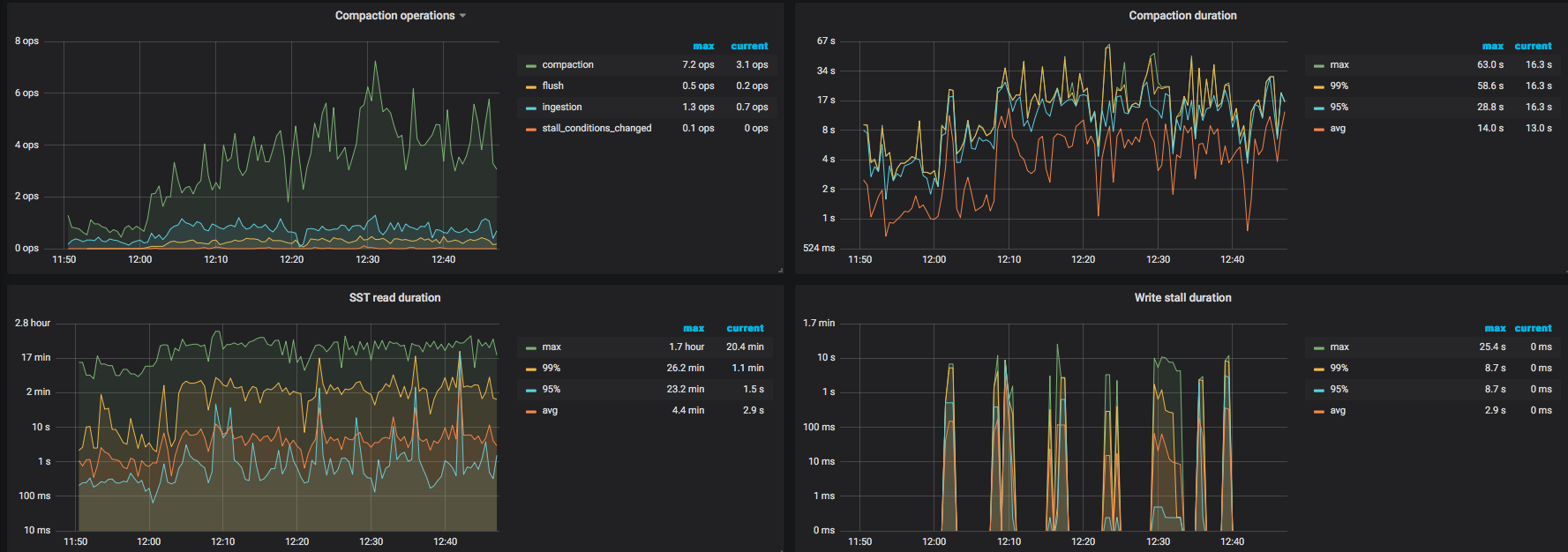
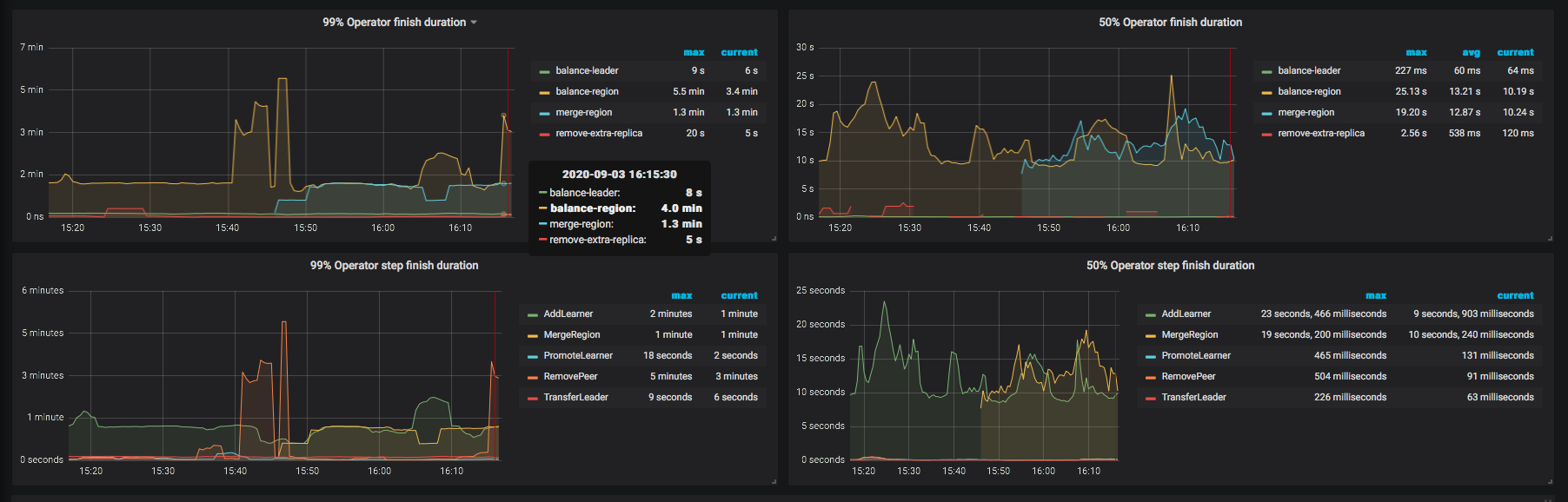
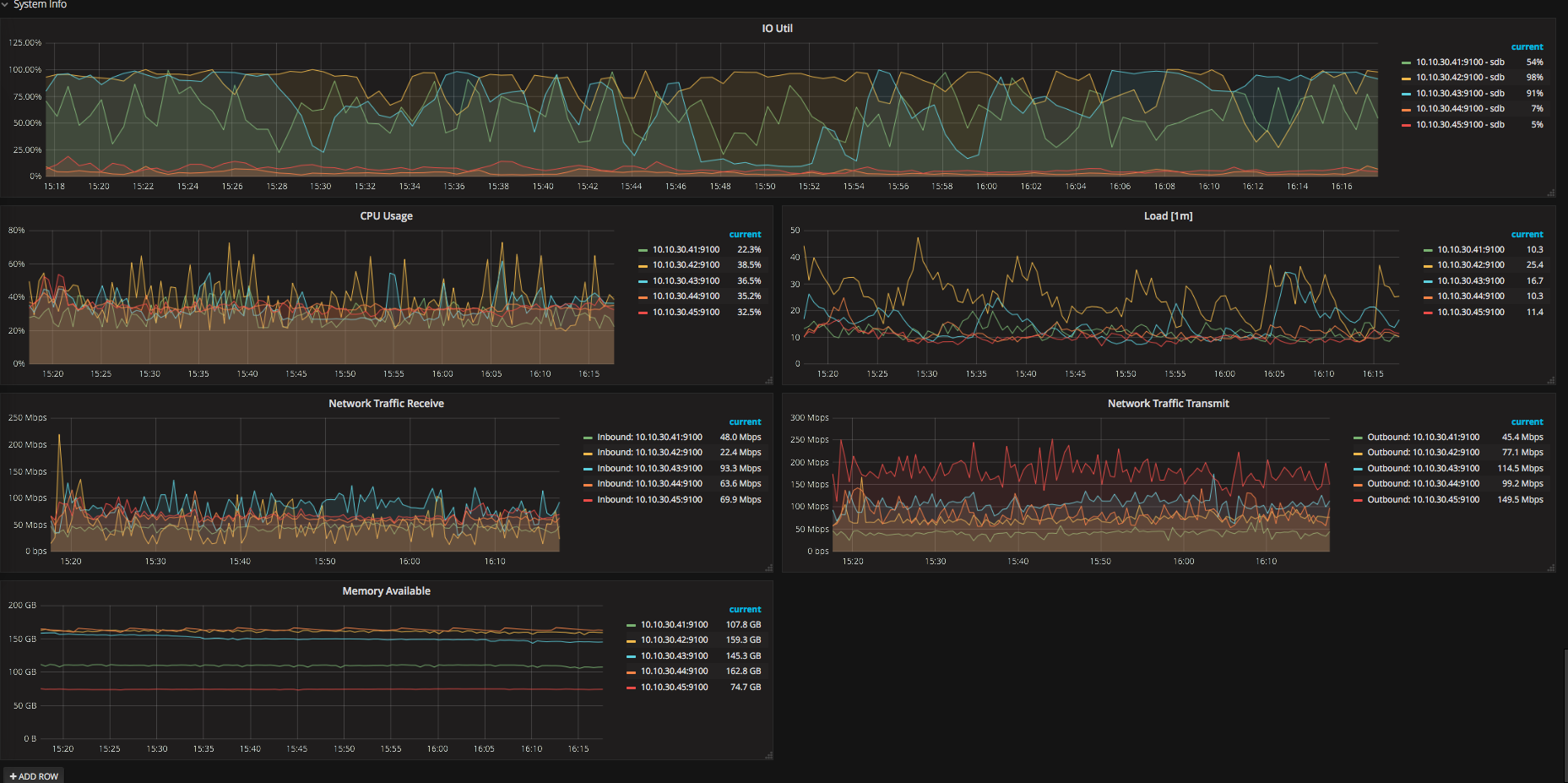
看下 overview 和 tikv trouble shooting 监控界面
打开 grafana 监控,先按 d 再按 shift+e 可以打开所有监控项。
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存


发现问题了?
看下 pd-ctl sotre 的信息。
{
“count”: 5,
“stores”: [
{
“store”: {
“id”: 1,
“address”: “10.10.30.41:6001”,
“version”: “3.0.0-beta.1”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.4 TiB”,
“available”: “442 GiB”,
“leader_count”: 8874,
“leader_weight”: 1,
“leader_score”: 403946,
“leader_size”: 403946,
“region_count”: 35797,
“region_weight”: 1,
“region_score”: 448871319.42258286,
“region_size”: 1599457,
“start_ts”: “2020-09-03T11:49:40+08:00”,
“last_heartbeat_ts”: “2020-09-03T16:12:16.183645932+08:00”,
“uptime”: “4h22m36.183645932s”
}
},
{
“store”: {
“id”: 4,
“address”: “10.10.30.42:6001”,
“version”: “3.0.0-beta.1”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.4 TiB”,
“available”: “876 GiB”,
“leader_count”: 4476,
“leader_weight”: 1,
“leader_score”: 304075,
“leader_size”: 304075,
“region_count”: 28695,
“region_weight”: 1,
“region_score”: 1778808,
“region_size”: 1778808,
“start_ts”: “2020-09-03T12:00:33+08:00”,
“last_heartbeat_ts”: “2020-09-03T16:12:18.994681+08:00”,
“uptime”: “4h11m45.994681s”
}
},
{
“store”: {
“id”: 6,
“address”: “10.10.30.43:6001”,
“version”: “3.0.0-beta.1”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.4 TiB”,
“available”: “470 GiB”,
“leader_count”: 5897,
“leader_weight”: 1,
“leader_score”: 282116,
“leader_size”: 282116,
“region_count”: 72862,
“region_weight”: 1,
“region_score”: 340220389.90897846,
“region_size”: 3544635,
“receiving_snap_count”: 1,
“start_ts”: “2020-09-03T12:02:25+08:00”,
“last_heartbeat_ts”: “2020-09-03T16:12:21.46236885+08:00”,
“uptime”: “4h9m56.46236885s”
}
},
{
“store”: {
“id”: 8,
“address”: “10.10.30.44:6001”,
“version”: “3.0.0-beta.1”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.4 TiB”,
“available”: “448 GiB”,
“leader_count”: 36001,
“leader_weight”: 1,
“leader_score”: 1939089,
“leader_size”: 1939089,
“region_count”: 71303,
“region_weight”: 1,
“region_score”: 425818918.5026283,
“region_size”: 3810446,
“sending_snap_count”: 1,
“start_ts”: “2019-08-16T10:36:44+08:00”,
“last_heartbeat_ts”: “2020-09-03T16:12:21.962615977+08:00”,
“uptime”: “9221h35m37.962615977s”
}
},
{
“store”: {
“id”: 9,
“address”: “10.10.30.45:6001”,
“version”: “3.0.0-beta.1”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.4 TiB”,
“available”: “450 GiB”,
“leader_count”: 40771,
“leader_weight”: 1,
“leader_score”: 1939084,
“leader_size”: 1939084,
“region_count”: 79436,
“region_weight”: 1,
“region_score”: 415874254.0135541,
“region_size”: 3872929,
“start_ts”: “2020-07-03T12:42:57+08:00”,
“last_heartbeat_ts”: “2020-09-03T16:12:19.553340493+08:00”,
“uptime”: “1491h29m22.553340493s”
}
}
]
}

现在tidb集群已经没有写入操作了,各种调度基本上全停了,但是集群仍然在做数据调度,磁盘io一直100%的负载,这点很困惑
pd调度配置:
[schedule]
控制 Region Merge 的 size 上限,当 Region Size 大于指定值时 PD 不会将其与相邻的 Region 合并。
max-merge-region-size = 3
控制 Region Merge 的 key 上限,当 Region key 大于指定值时 PD 不会将其与相邻的 Region 合并
max-merge-region-keys = 200000
控制对同一个 Region 做 split 和 merge 操作的间隔,即对于新 split 的 Region 一段时间内不会被 merge。
split-merge-interval = “1h”
控制单个 store 最多同时接收或发送的 snapshot 数量,调度受制于这个配置来防止抢占正常业务的资源。
max-snapshot-count = 3
控制单个 store 的 pending peer 上限,调度受制于这个配置来防止在部分节点产生大量日志落后的 Region。
max-pending-peer-count = 4
PD 认为失联 store 无法恢复的时间,当超过指定的时间没有收到 store 的心跳后,PD 会在其他节点补充副本。
max-store-down-time = “30m”
同时进行 leader 调度的任务个数
leader-schedule-limit = 0
#同时进行 Region 调度的任务个数
region-schedule-limit = 0
同时进行 replica 调度的任务个数。
replica-schedule-limit = 1
同时进行的 Region Merge 调度的任务,设置为 0 则关闭 Region Merge。
merge-schedule-limit = 0
同时进行 热Region 调度的任务个数
hot-region-schedule-limit = 0
有没有方法彻底关闭数据调度

1、在追数据或者灌入数据的时候能不能把调度功能给停掉,防止磁盘io负载100%
2、目前通过监控发现所有的调度中balance-leader最多,达到几千个,为什么会频繁调度leader
3、通过监控发现,tidb集群一共5台机器,其中三台磁盘io一直100%而其他的两台负载一直很低,是热点数据没有调度到这两台还是有什么因素导致这两台没有资格成为leader节点
4、目前tidb写入速度在kb级别,这么低的写入量为什么磁盘io这么高,tidb里什么操作容易产生大量读写磁盘的情况
max-pending-peer-count这个参数是不是越大表明同时在进行写操作的region越多?现在磁盘io已经100%了,扩大该值是否能加快写入速度?

可以增加同步速度。
不可以,调度反而在一定程度上会加快导入速度
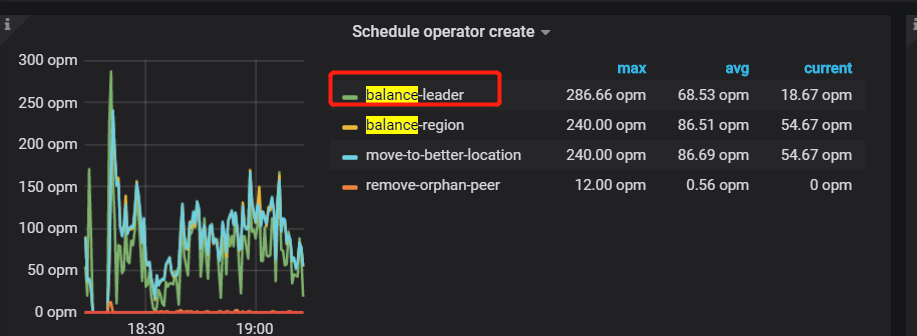
指的是这个?
正常的调度,是应为 pending peer 的原因,导致 leader 调度比较频繁。
解决 pending peer 问题,此问题会有所缓解,目前不好判断为热点问题。
确认下磁盘是否为本地 ssd 盘
都是本地ssd盘,5块盘做的raid5,日常写入速度在150M-200M之间
看一下 TiKV 监控的 gPRC 的 count 是否有大量的请求操作,如果 TiDB 没有读写请求的情况,还是有其他的场景会导致磁盘读写,比如 TiKV 后台的 flush 或者 compaction 操作。