- 【TiDB 版本】:v3.0.7
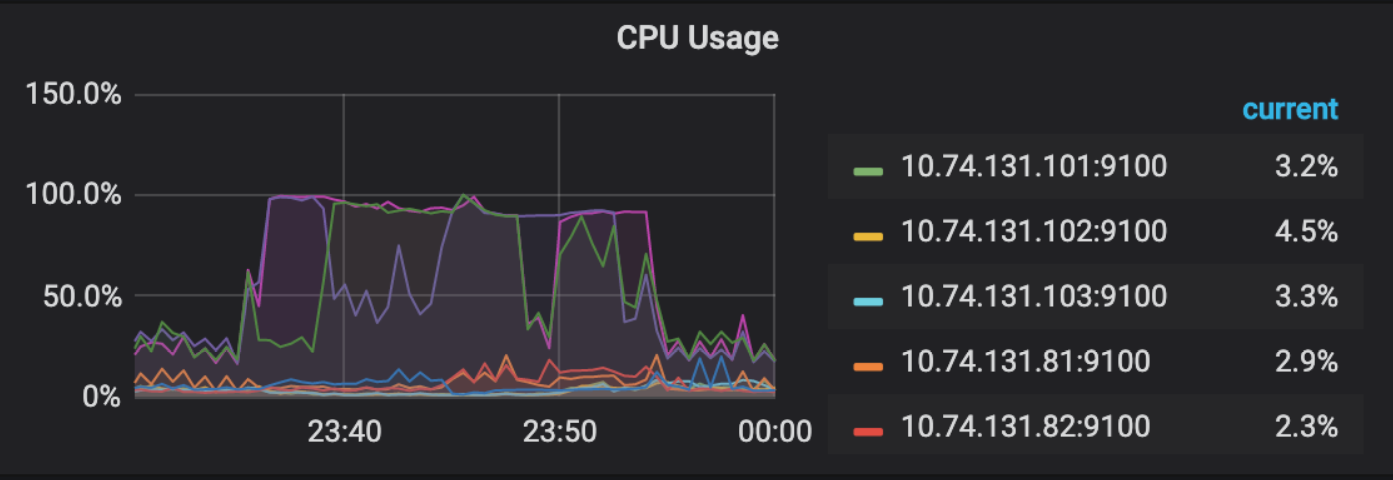
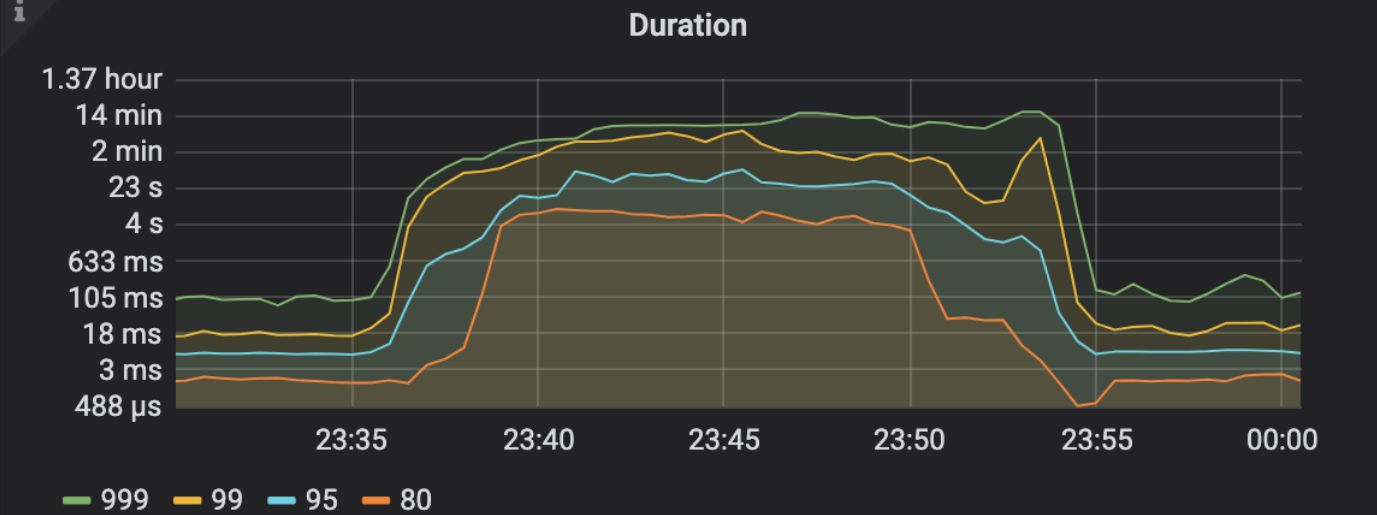
- 【问题描述】:手工收集一个近两亿大表时,集群慢查询飙升,query监控如下
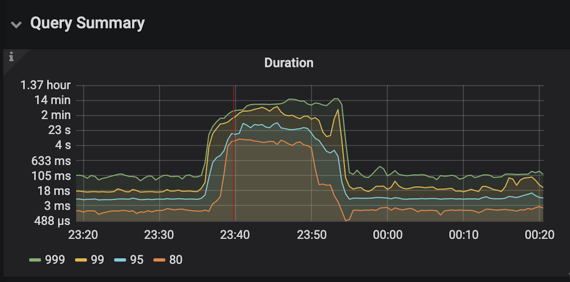
当时第一反应是有慢查询导致性能降低,于是每个节点看了下日志,搜索expensive_query关键词,日志如下
[root@host-tidb-pdtidb001 log]# grep ‘2020/09/02 23:3’ tidb-2020-09-02T23-50-50.494.log|grep expensive_query|more
[2020/09/02 23:36:01.294 +08:00] [WARN] [expensivequery.go:160] [expensive_query] [cost_time=60.012666892s] [conn_id=574
59702] [user=root] [database=user_collect] [txn_start_ts=0] [mem_max="0 Bytes"] [sql="analyze table collect"]
[2020/09/02 23:36:50.195 +08:00] [WARN] [expensivequery.go:160] [expensive_query] [cost_time=60.051810188s] [process_tim
e=2.287s] [wait_time=2.287s] [request_count=62] [total_keys=1352301] [process_keys=1352236] [num_cop_tasks=62] [process_
avg_time=0.036887096s] [process_p90_time=0.038s] [process_max_time=0.548s] [process_max_addr=10.74.131.85:20160] [wait_a
vg_time=4.304677419s] [wait_p90_time=14.318s] [wait_max_time=27.412s] [wait_max_addr=10.74.131.84:20160] [stats=collect:
419184232880668679] [conn_id=57456355] [user=user] [database=user_collect] [table_ids="[5036]"] [index_ids="[co
llect:created_time]"] [txn_start_ts=419184233706422303] [mem_max="76.95711612701416 MB"] [sql="SELECT COUNT(*) AS `numro
ws`\
FROM collect
WHERE key = ‘8290068’
AND type = ‘gzuser’
AND status = 1
AND created_time > ‘1598706113’
"]
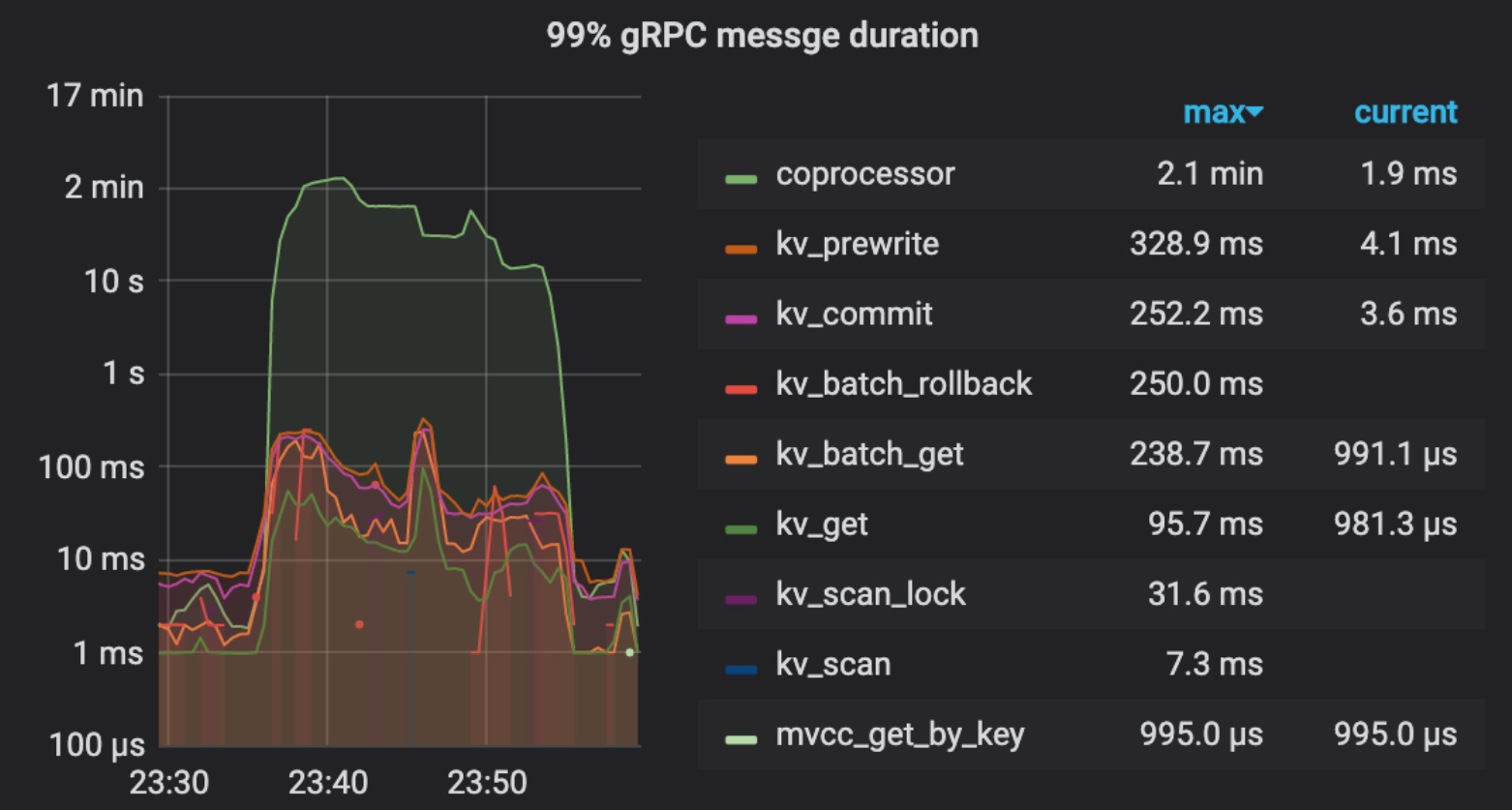
发现23:36:01触发analyze table,23:36:50时三个tidb节点同一秒开始堆积大量慢查询,都是wait_time比较久,且sql语句都是同一类型,只是value不同,问题时段我有确认过
SELECT COUNT(*) AS numrowsFROMcollectWHEREkey= '8290068' ANDtype= 'gzuser' ANDstatus= 1 ANDcreated_time > '1598706113'的执行计划是没有问题的
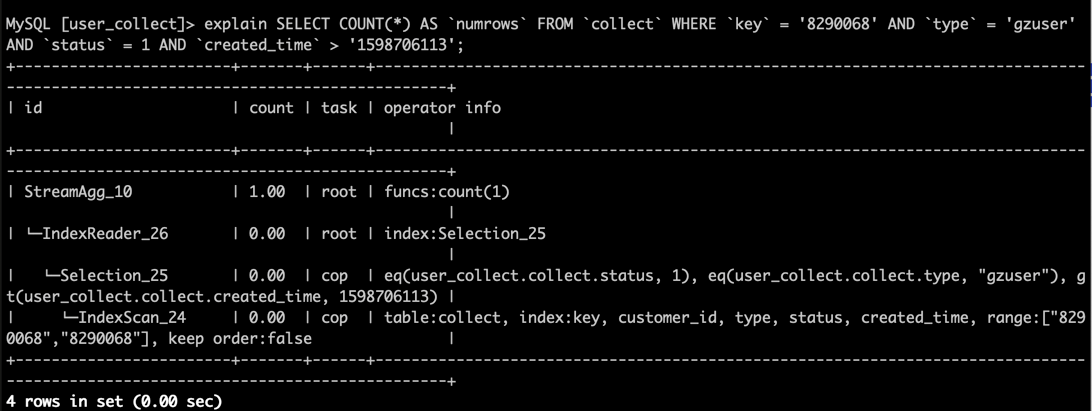
因此排除了业务sql大量扫表导致集群性能降低
那么对于这种大表的统计信息收集,有什么方案可以避免再出现类似情况呢