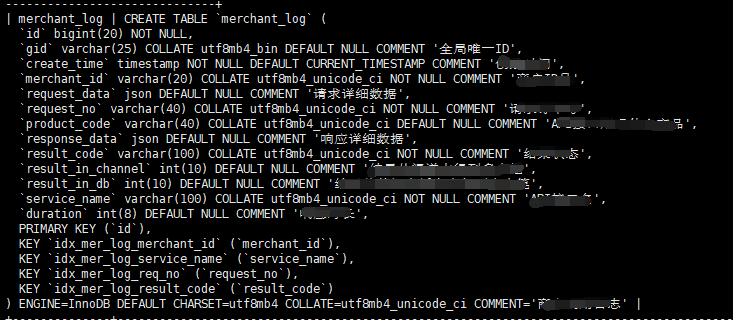
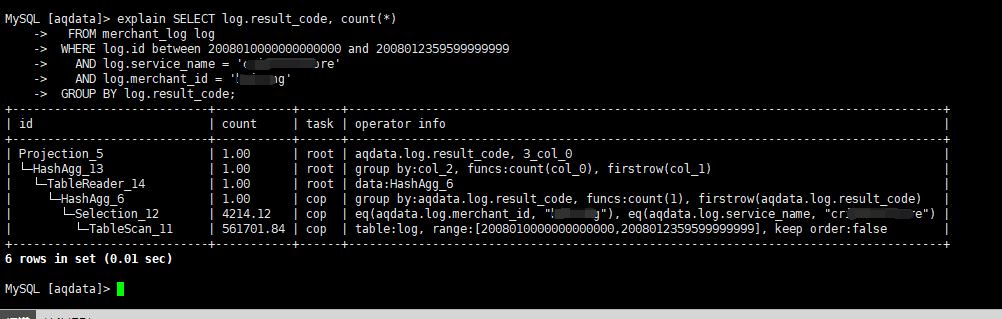
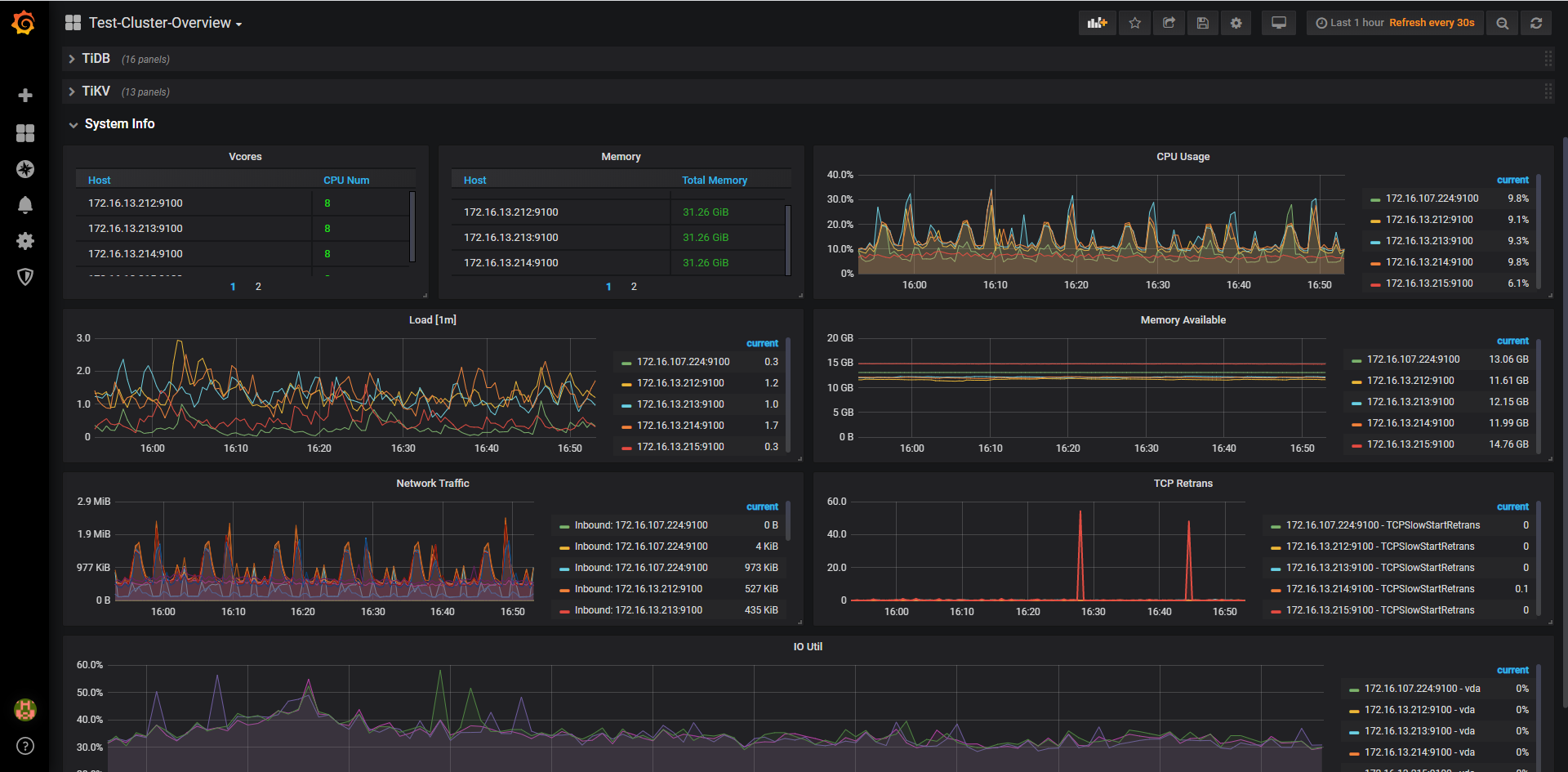
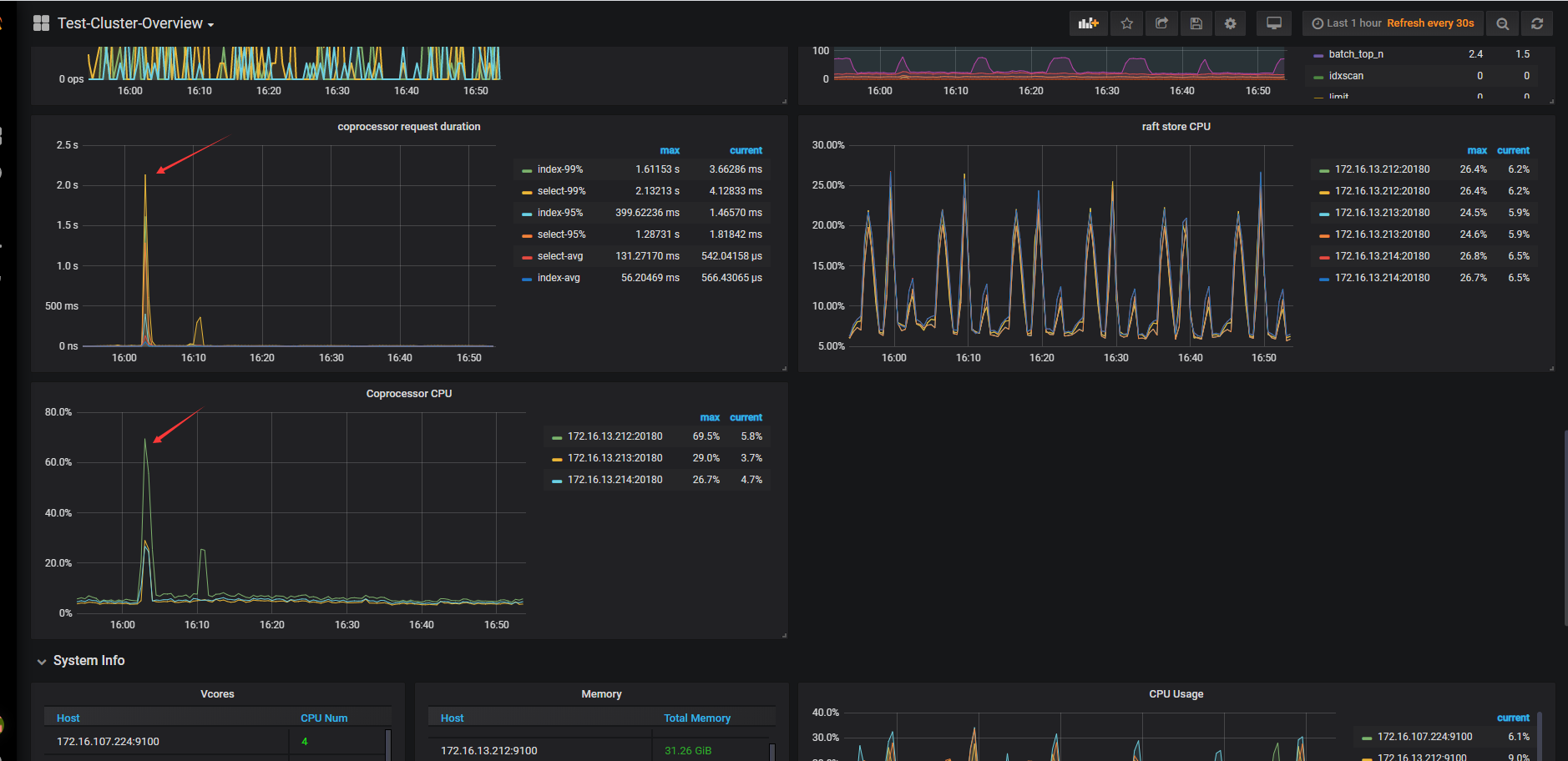
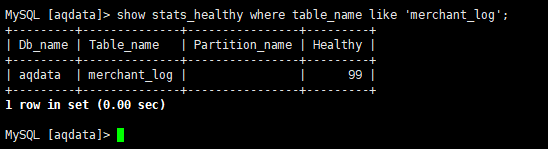
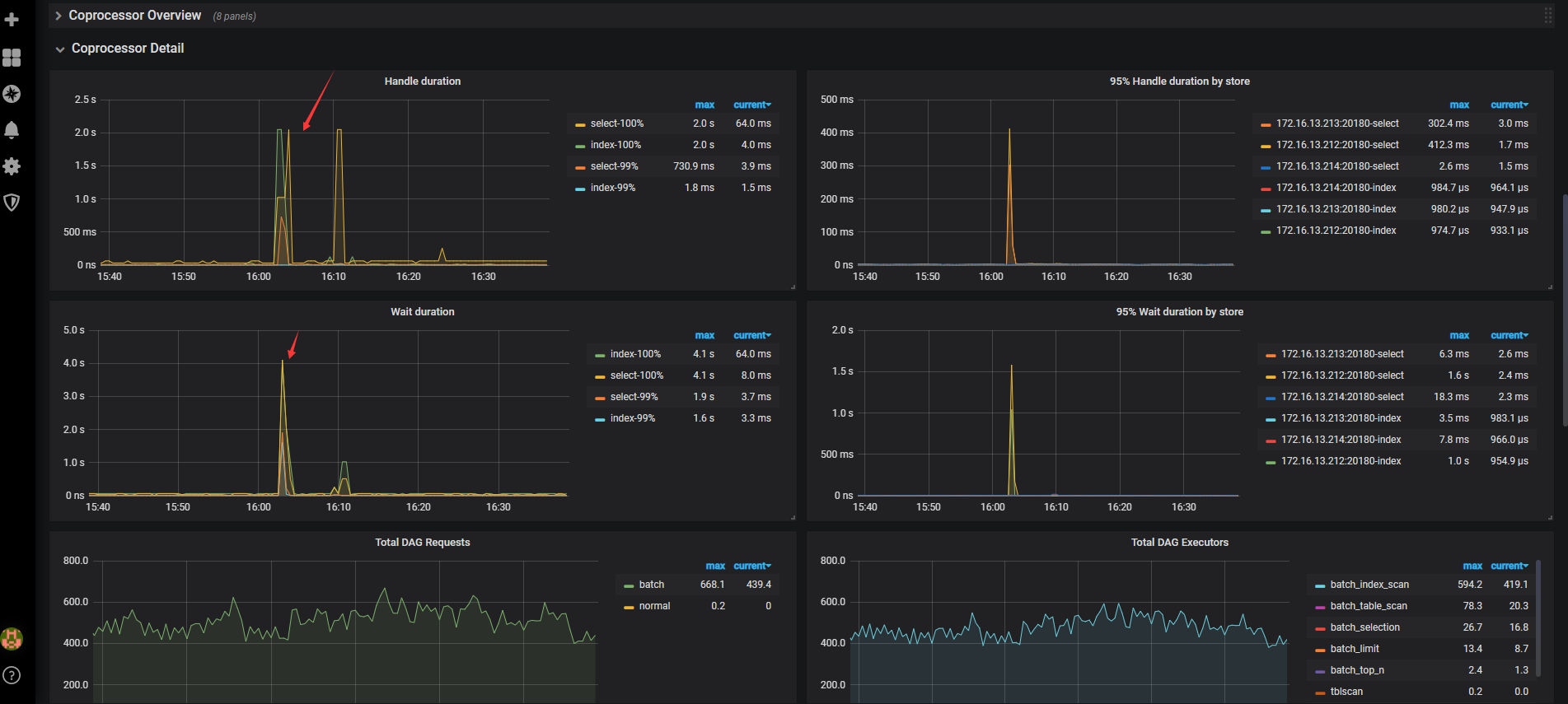
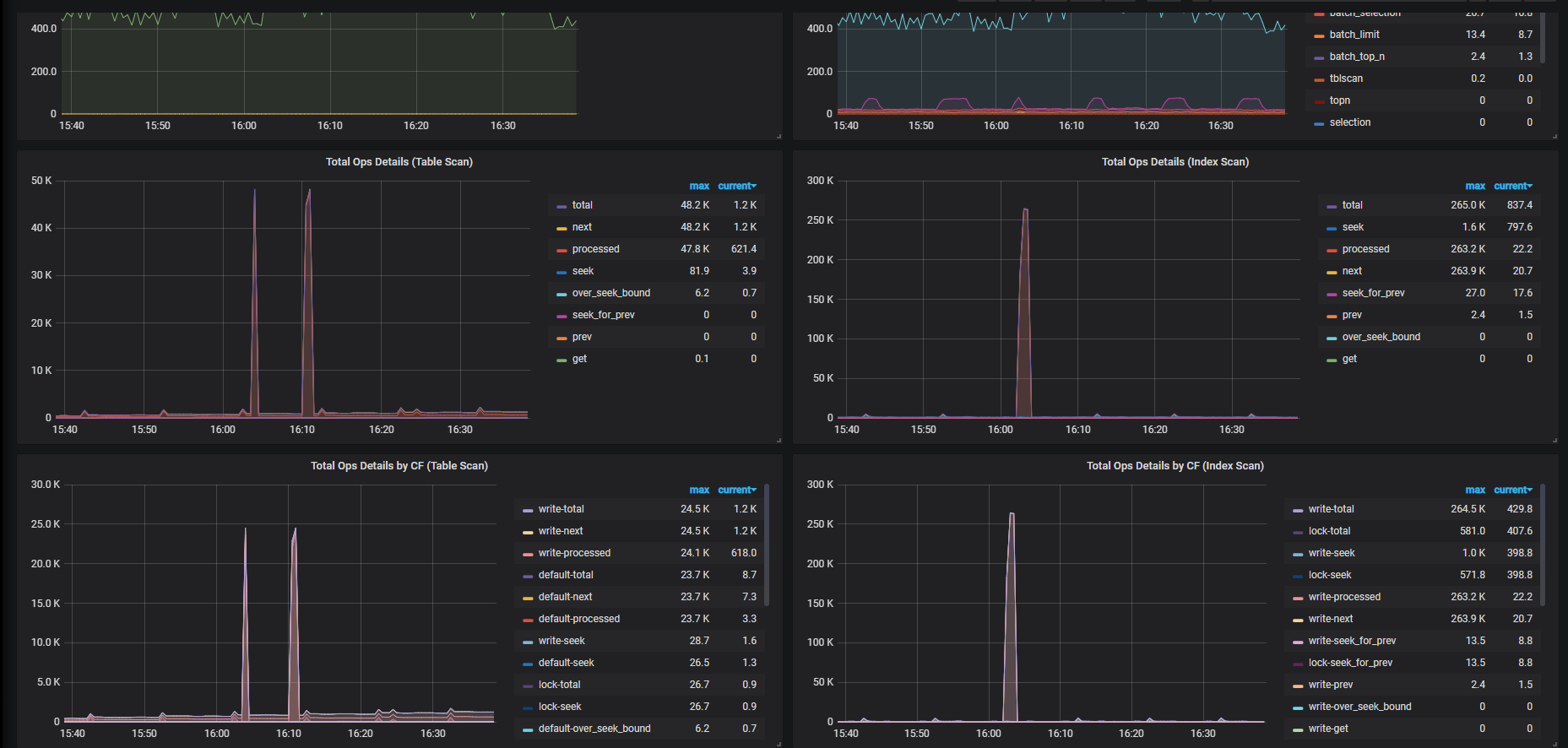
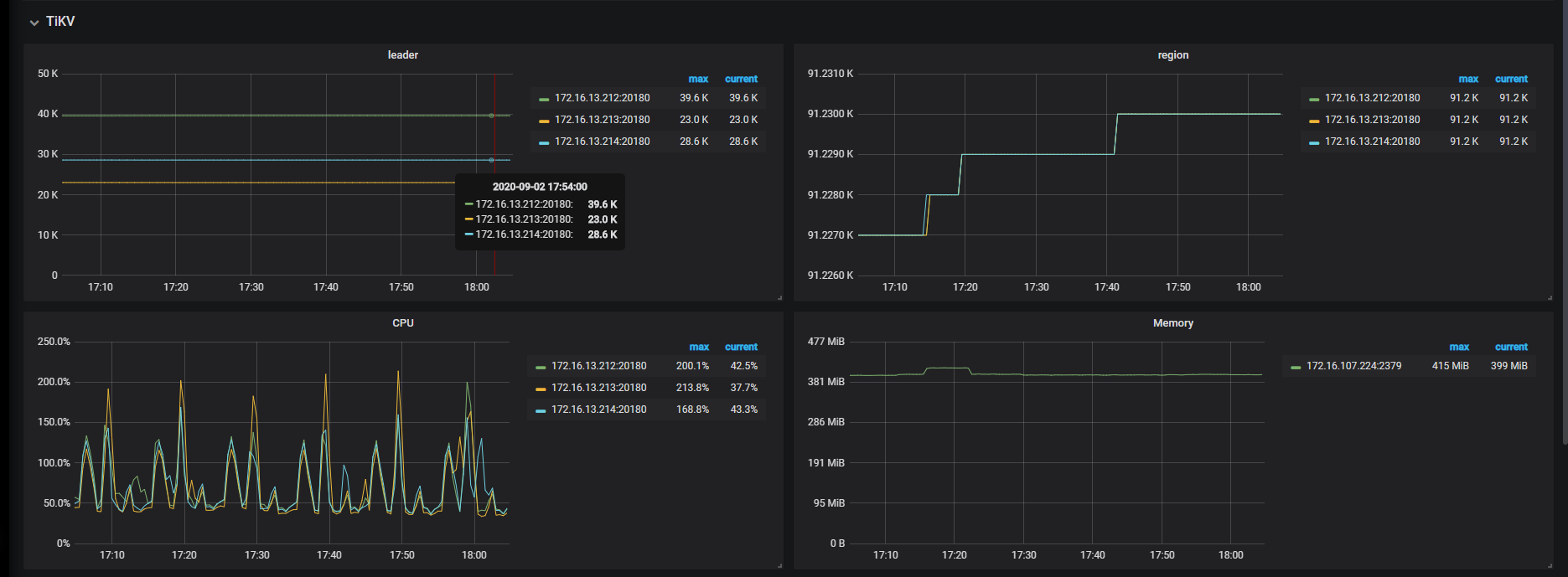
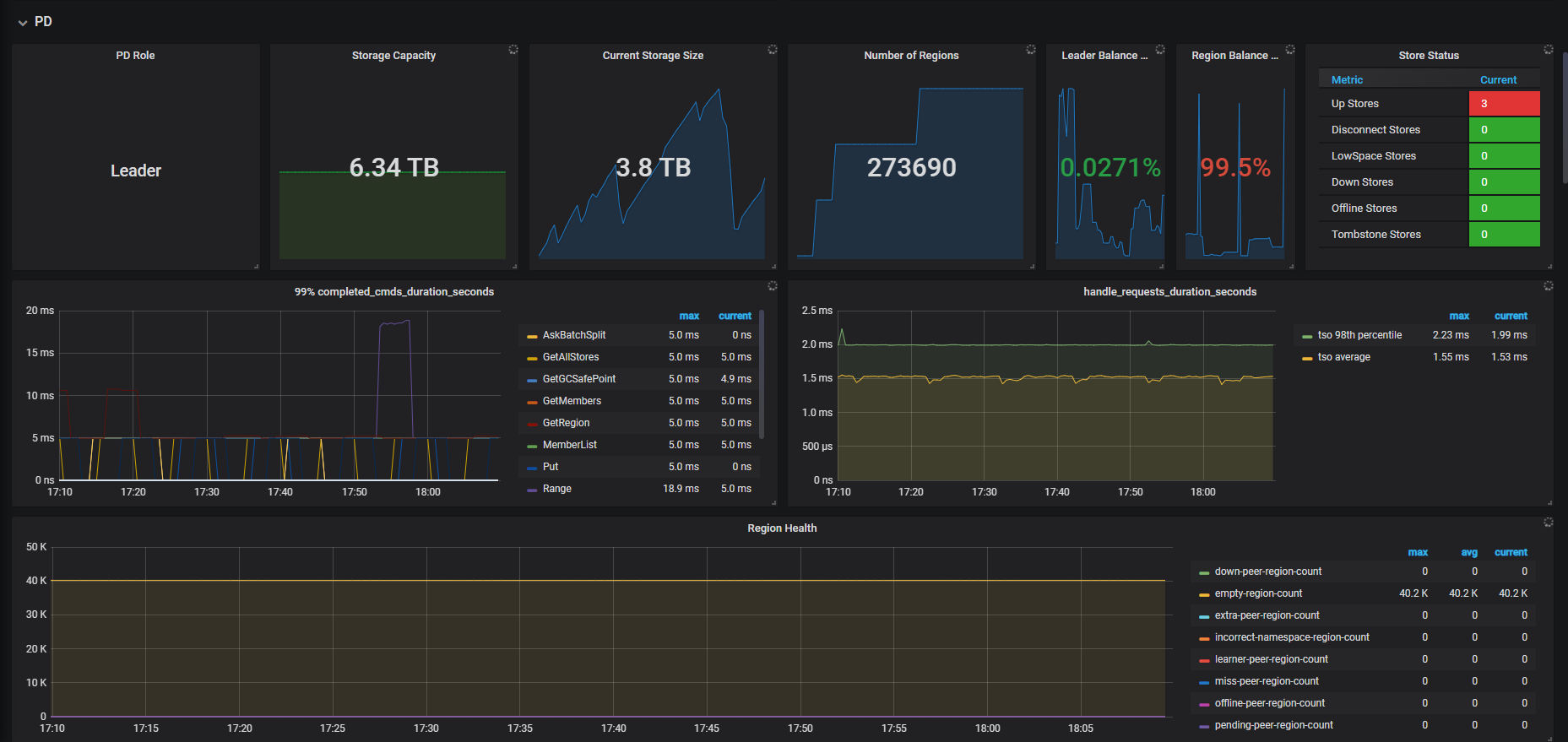
SELECT log.result_code, count(*)
FROM merchant_log log
WHERE log.id between 2008010000000000000 and 2008012359599999999
AND log.service_name = ‘b’
AND log.merchant_id = ‘a’
GROUP BY log.result_code;
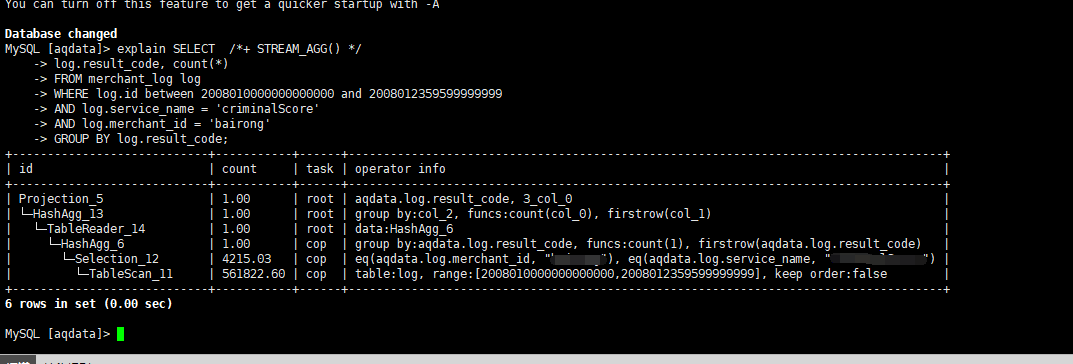
SELECT /*+ STREAM_AGG() */
log.result_code, count(*)
FROM merchant_log log
WHERE log.id between 2008010000000000000 and 2008012359599999999
AND log.service_name = ‘b’
AND log.merchant_id = ‘a’
GROUP BY log.result_code;