你好,我们在从ansible向tiup进行升级时,遇到了问题:
1)当前版本为3.1.0-beta.1
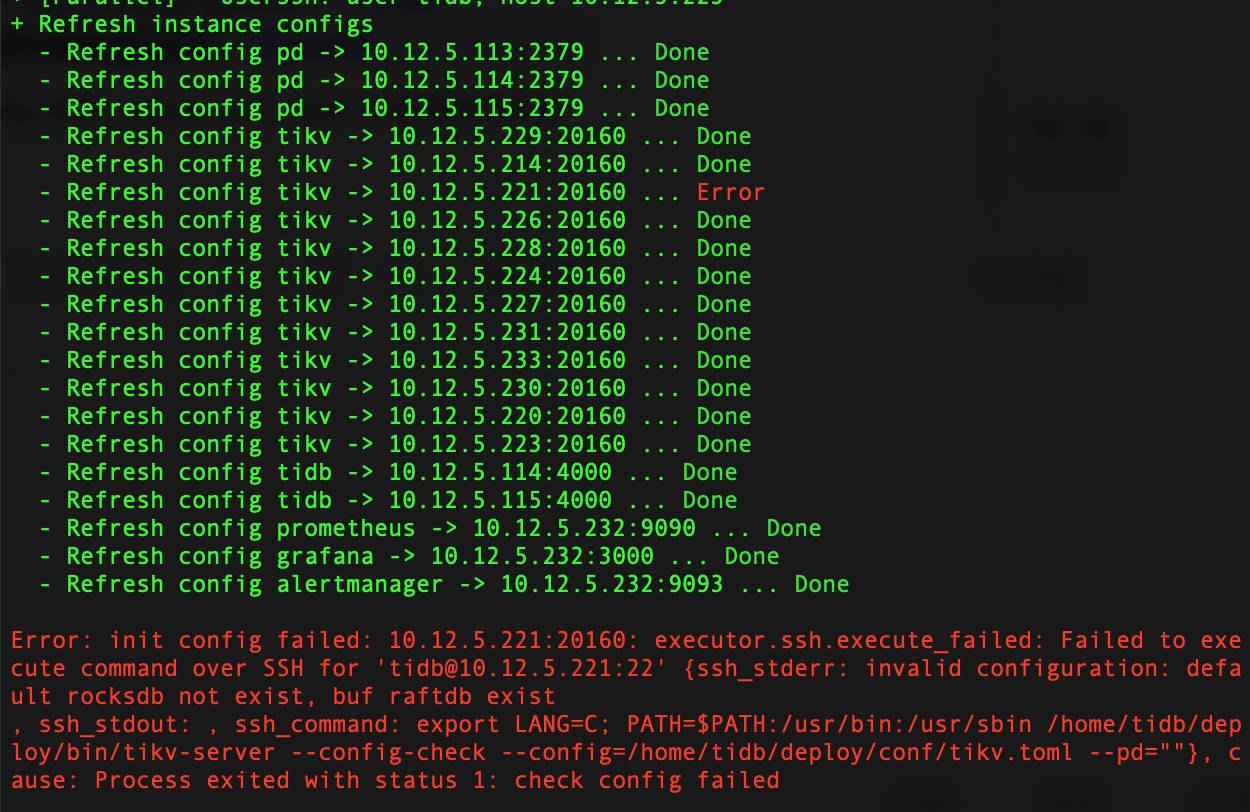
2)在执行 tiup cluster reload test-cluster 时遇到问题,某一tikv节点报错为:
invalid configuration: default rocksdb not exist, buf raftdb exist
请问如何解决,谢谢
你好,我们在从ansible向tiup进行升级时,遇到了问题:
1)当前版本为3.1.0-beta.1
2)在执行 tiup cluster reload test-cluster 时遇到问题,某一tikv节点报错为:
invalid configuration: default rocksdb not exist, buf raftdb exist
请问如何解决,谢谢
查看了下报错信息类似案例都是 “default rocksdb exist, buf raftdb not exist”) 与 你的相反,能否麻烦截图展示下 报错,多谢。
我把全部的配置文件都上传了。其中,出问题的是10.12.5.221这个节点。
ansible-imported-configs.tar.gz (29.2 KB)
另外,我在221这个节点执行:
tidb@nine:~$ /home/tidb/deploy/bin/tikv-server --config-check --config=/home/tidb/deploy/conf/tikv.toml --pd=“”
invalid configuration: default rocksdb not exist, buf raftdb exist
感谢反馈。请问下当前集群的服务器配置可否提供下
请问是否指网络拓扑?
tidb@three:~/.tiup/storage/cluster/clusters/test-cluster/ansible-backup$ cat inventory.ini
## TiDB Cluster Part
[tidb_servers]
10.12.5.114
10.12.5.115
[tikv_servers]
10.12.5.230
10.12.5.220
10.12.5.221
10.12.5.223
10.12.5.224
10.12.5.226
10.12.5.227
10.12.5.228
10.12.5.229
10.12.5.231
10.12.5.233
10.12.5.214
[pd_servers]
10.12.5.113
10.12.5.114
10.12.5.115
[spark_master]
[spark_slaves]
[lightning_server]
[importer_server]
## Monitoring Part
# prometheus and pushgateway servers
[monitoring_servers]
10.12.5.232
[grafana_servers]
10.12.5.232
# node_exporter and blackbox_exporter servers
[monitored_servers]
10.12.5.232
10.12.5.113
10.12.5.114
10.12.5.115
10.12.5.230
10.12.5.220
10.12.5.221
10.12.5.223
10.12.5.226
10.12.5.224
10.12.5.227
10.12.5.228
10.12.5.229
10.12.5.231
10.12.5.233
10.12.5.214
[alertmanager_servers]
10.12.5.232
[kafka_exporter_servers]
## Binlog Part
[pump_servers]
[drainer_servers]
## Group variables
[pd_servers:vars]
# location_labels = ["zone","rack","host"]
location_labels=["host"]
## Global variables
[all:vars]
deploy_dir = /home/tidb/deploy
## Connection
# ssh via normal user
ansible_user = tidb
cluster_name = test-cluster
tidb_version = v3.1.0-beta.1
# process supervision, [systemd, supervise]
process_supervision = systemd
timezone = Asia/Shanghai
enable_firewalld = False
# check NTP service
enable_ntpd = True
set_hostname = False
## binlog trigger
enable_binlog = False
# kafka cluster address for monitoring, example:
# kafka_addrs = "192.168.0.11:9092,192.168.0.12:9092,192.168.0.13:9092"
kafka_addrs = ""
# zookeeper address of kafka cluster for monitoring, example:
# zookeeper_addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181"
zookeeper_addrs = ""
# enable TLS authentication in the TiDB cluster
enable_tls = False
# KV mode
deploy_without_tidb = False
# wait for region replication complete before start tidb-server.
wait_replication = True
# Optional: Set if you already have a alertmanager server.
# Format: alertmanager_host:alertmanager_port
alertmanager_target = ""
grafana_admin_user = "admin"
grafana_admin_password = "****"
### Collect diagnosis
collect_log_recent_hours = 2
enable_bandwidth_limit = True
# default: 10Mb/s, unit: Kbit/s
collect_bandwidth_limit = 10000
tidb@three:~/.tiup/storage/cluster/clusters/test-cluster/ansible-backup$上面 tar 包中上传的 toml 文件都是 ansible backup 目录下的配置文件。
我们需要看下 221 节点下 tikv conf tikv.toml 文件。
和
tiup 生成的新的配置文件元信息(并不建议修改此文件)看下。
~/.tiup/storage/cluster/clusters//meta.yaml
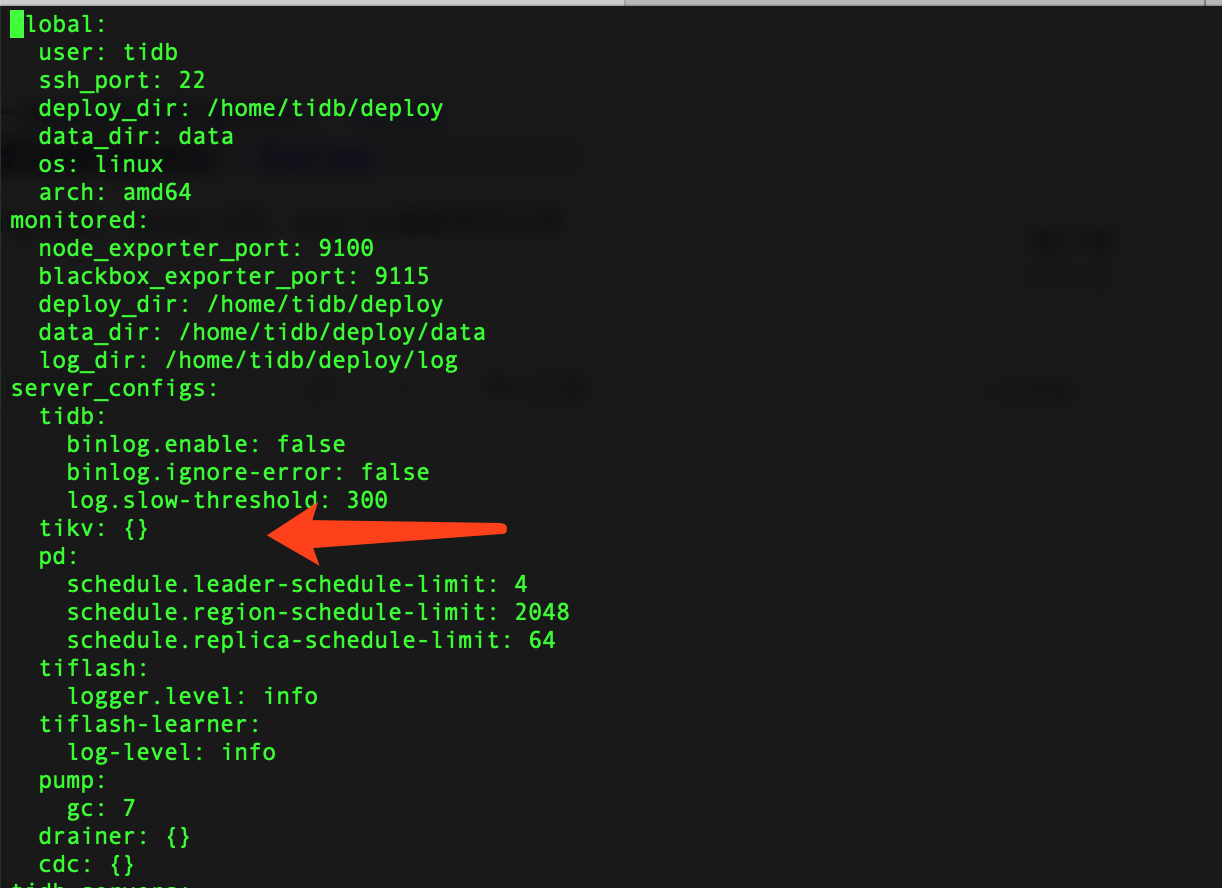
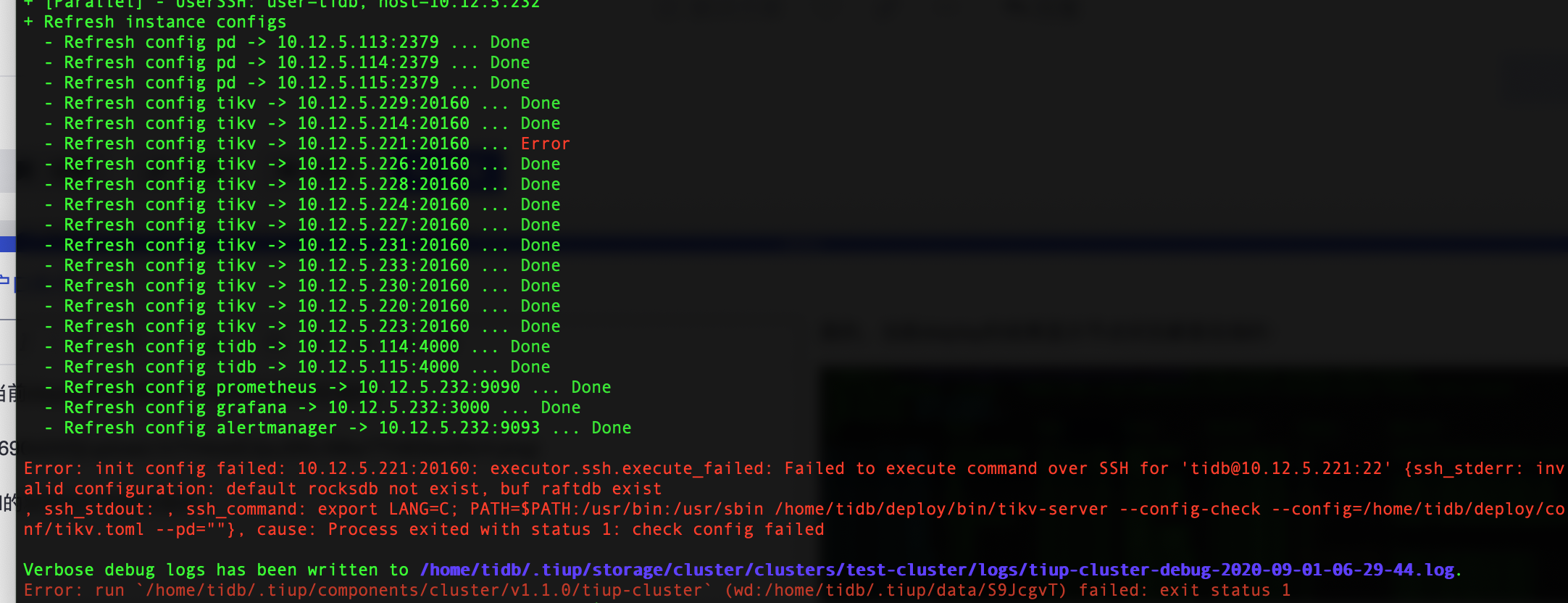
按照提示,将两个参数删除,现在config如下:
reload之后,221仍然显示error,如下图所示:
登录221节点,查看tikv.log日志,显示如下:
[2020/09/01 03:20:44.750 +00:00] [INFO] [raft.rs:924] ["[region 908204] 19861858 [term: 2881] received a MsgRequestVote message with higher term from 20236492 [term: 2882]"]
[2020/09/01 03:20:44.750 +00:00] [INFO] [raft.rs:723] ["[region 908204] 19861858 became follower at term 2882"]
[2020/09/01 03:20:44.750 +00:00] [INFO] [raft.rs:1108] ["[region 908204] 19861858 [logterm: 2880, index: 9508, vote: 0] cast MsgRequestVote for 20236492 [logterm: 2880, index: 9508] at term 2882"]
[2020/09/01 03:20:46.562 +00:00] [INFO] [raft.rs:1108] ["[region 2387464] 20607110 [logterm: 12671, index: 12624, vote: 20607110] cast MsgRequestPreVote for 17509099 [logterm: 12671, index: 12624] at term 12672"]
[2020/09/01 03:20:46.606 +00:00] [INFO] [raft.rs:924] ["[region 2387464] 20607110 [term: 12672] received a MsgRequestVote message with higher term from 17509099 [term: 12673]"]
[2020/09/01 03:20:46.606 +00:00] [INFO] [raft.rs:723] ["[region 2387464] 20607110 became follower at term 12673"]
[2020/09/01 03:20:46.606 +00:00] [INFO] [raft.rs:1108] ["[region 2387464] 20607110 [logterm: 12671, index: 12624, vote: 0] cast MsgRequestVote for 17509099 [logterm: 12671, index: 12624] at term 12673"]
[2020/09/01 03:20:48.658 +00:00] [INFO] [raft.rs:1108] ["[region 7121916] 20293864 [logterm: 12421, index: 15790, vote: 20293864] cast MsgRequestPreVote for 17554487 [logterm: 12421, index: 15790] at term 12422"]
[2020/09/01 03:20:48.660 +00:00] [INFO] [raft.rs:924] ["[region 7121916] 20293864 [term: 12422] received a MsgRequestVote message with higher term from 17554487 [term: 12423]"]
[2020/09/01 03:20:48.660 +00:00] [INFO] [raft.rs:723] ["[region 7121916] 20293864 became follower at term 12423"]
-----------------(省略部分) -----------------
[2020/09/01 03:21:10.254 +00:00] [WARN] [raft_client.rs:132] ["batch_raft/raft RPC finally fail"] [err="RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(\"Connect Failed\") }))"] [to_addr=10.12.5.214:20160]
[2020/09/01 03:21:10.256 +00:00] [WARN] [raft_client.rs:207] ["send to 10.12.5.214:20160 fail, the gRPC connection could be broken"]
[2020/09/01 03:21:10.256 +00:00] [ERROR] [transport.rs:318] ["send raft msg err"] [err="Other(\"[src/server/raft_client.rs:216]: RaftClient send fail\")"]
[2020/09/01 03:21:10.256 +00:00] [INFO] [transport.rs:299] ["resolve store address ok"] [addr=10.12.5.214:20160] [store_id=17388737]
[2020/09/01 03:21:10.256 +00:00] [INFO] [raft_client.rs:50] ["server: new connection with tikv endpoint"] [addr=10.12.5.214:20160]
[2020/09/01 03:21:10.256 +00:00] [INFO] [subchannel.cc:878] ["Connect failed: {\"created\":\"@1598930470.256875206\",\"description\":\"Failed to connect to remote host: OS Error\",\"errno\":111,\"file\":\"/rust/registry/src/github.com-1ecc6299db9ec823/grpcio-sys-0.4.7/grpc/src/core/lib/iomgr/tcp_client_posix.cc\",\"file_line\":207,\"os_error\":\"Connection refused\",\"syscall\":\"connect\",\"target_address\":\"ipv4:10.12.5.214:20160\"}"]
[2020/09/01 03:21:10.257 +00:00] [INFO] [subchannel.cc:760] ["Subchannel 0x7efcc9a51200: Retry in 1000 milliseconds"]
[2020/09/01 03:21:10.257 +00:00] [WARN] [raft_client.rs:118] ["batch_raft RPC finished fail"] [err="RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(\"Connect Failed\") }))"]
[2020/09/01 03:21:10.257 +00:00] [WARN] [raft_client.rs:132] ["batch_raft/raft RPC finally fail"] [err="RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(\"Connect Failed\") }))"] [to_addr=10.12.5.214:20160]
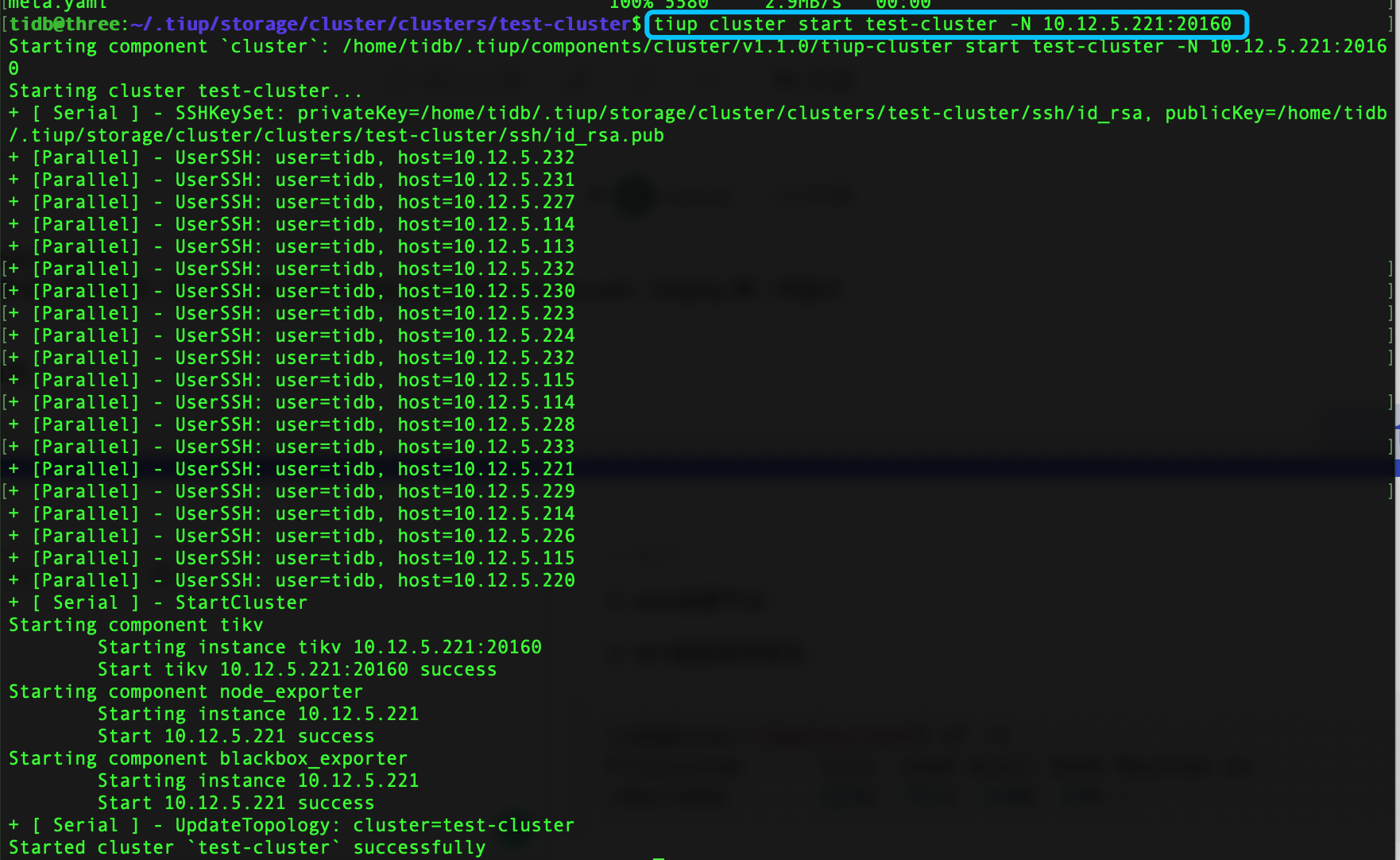
另外,start -N 是如何用?能否说的再详细一些?
上传下 meta 文件和 tikv.toml 文件看下
我的意思是可以 start 故障 tikv 节点即可。tiup cluster start clustername -N tikv-ip:tikv-port(display 第一列显示的内容)
df 看下当前磁盘的使用情况。
tidb@nine:~/deploy/conf$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 885G 701G 140G 84% /
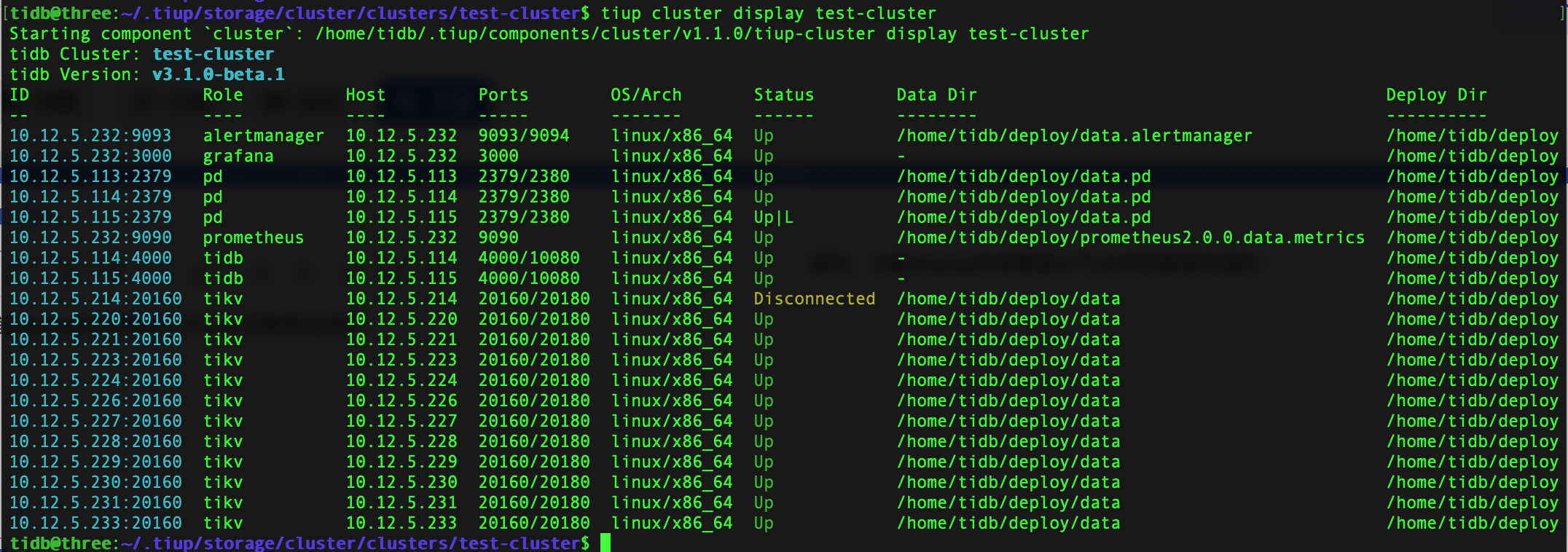
display 看下返回结果,
确认下,reload 没成功,但是 start 可以启动是吧
start 可以成功是因为 start 的时候并不检查配置,reload 可以加上 --ignore-config-check 参数,也会忽略配置检查结果,应该可以成功 reload
出现问题:
Error: 10.12.5.232 failed to restart: timed out waiting for port 9093 to be started after 2m0s: timed out waiting for port 9093 to be started after 2m0s
Verbose debug logs has been written to /home/tidb/tidb-enterprise-tools-latest-linux-amd64/logs/tiup-cluster-debug-2020-09-01-15-19-52.log.
Error: run `/home/tidb/.tiup/components/cluster/v1.1.0/tiup-cluster` (wd:/home/tidb/.tiup/data/S9LXvh5) failed: exit status 1
对应的log:
tiup-cluster-debug-2020-09-01-15-19-52.log (471.0 KB)
您是否使用的是 tiup-cluster v1.1.0? 这个版本有个小问题,昨晚已修复,麻烦执行 tiup update cluster 升级到 v1.1.1,然后再进行操作
你好,我现在是v1.0.9 tiup版本,是否先要升级?
1.0.9 没有问题,能否上 10.12.5.232 这台机器把 alertmanager 的日志拿下来看看?