如题,这边1亿多条的数据量通过spark jdbc(batch insert)的方式需要一个多小时;看tispark可以加速batch写;所以想问下:
1.加速比大概多少,是否有测评数据?
2.tidb v4.0.3,spark 2.1.1(yarn)是否可以集成tispark?
1 个赞
目前没有类似的测试报告,但是从 tispark 原理上来讲是有很大的提升的。
https://book.tidb.io/session1/chapter11/tispark-architecture.html
可以使用 tispark 1.x 版本与 spark 2.1.1 进行融合,具体看下 pingcap/tispark
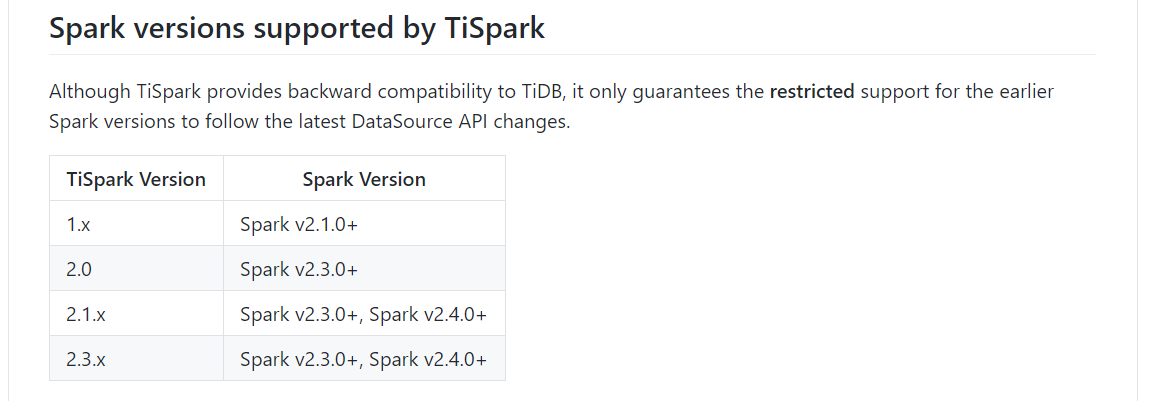
那可以加测试报告吗?
后面会添加报告,可以持续关注下文档和 tidb in action 中的章节。
好的,感谢
感谢关注,有问题欢迎开新帖继续讨论
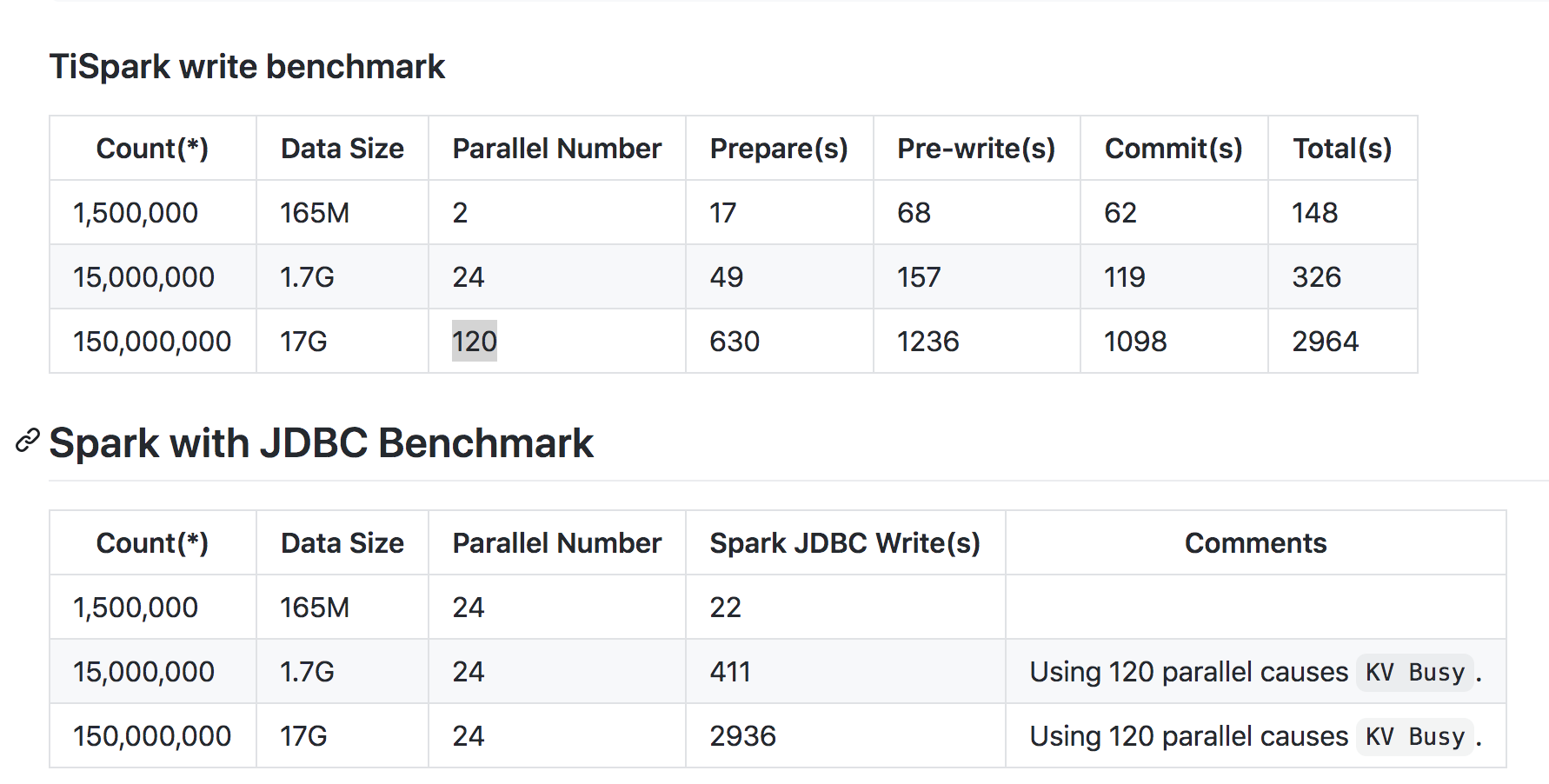
一个大概的数据,对于服务器配置和参数调整没有提及,可以参考。
这个加速比是怎么看的
如有疑问,麻烦发下新帖~旧贴会不再回复~
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。