为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:5.7.25-TiDB-v4.0.4
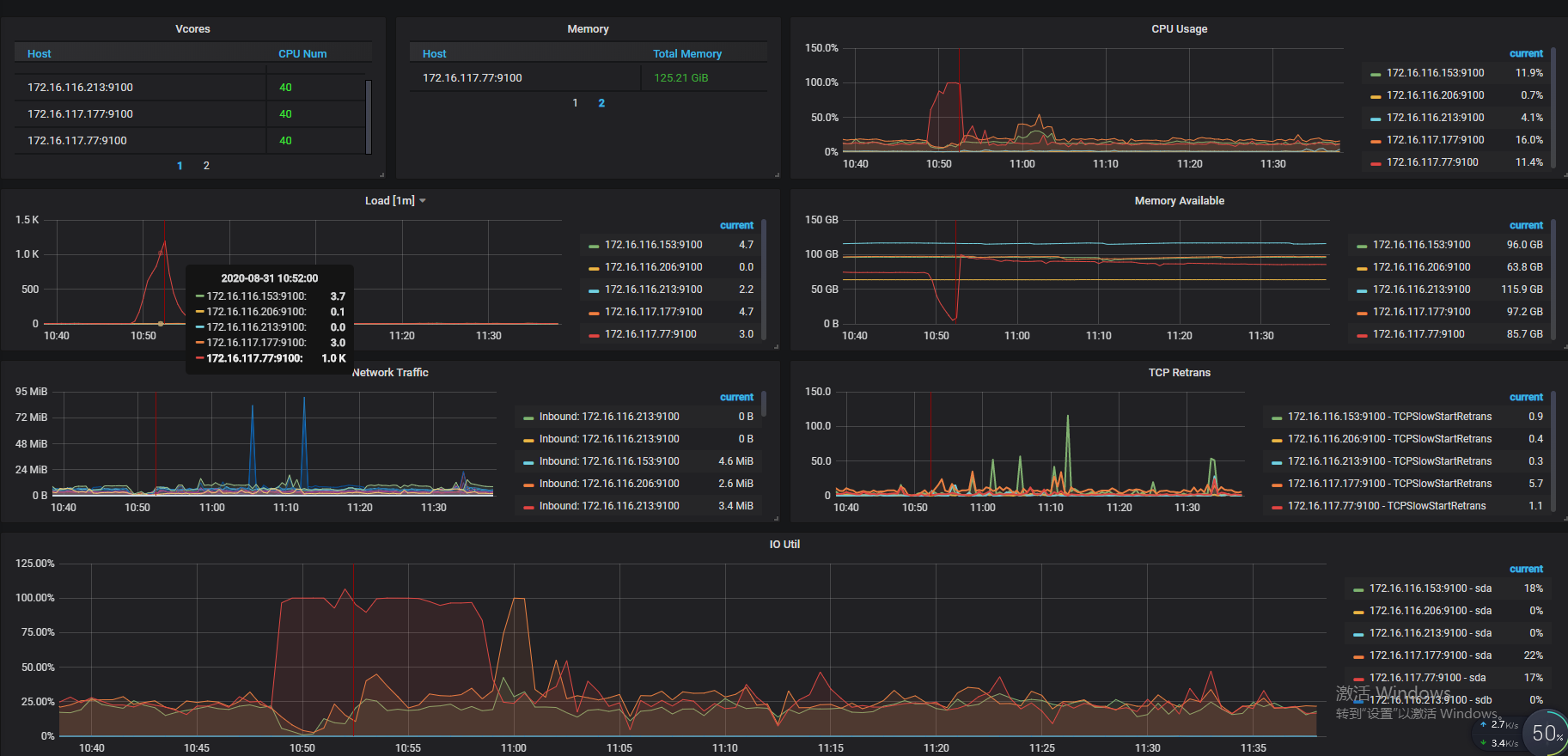
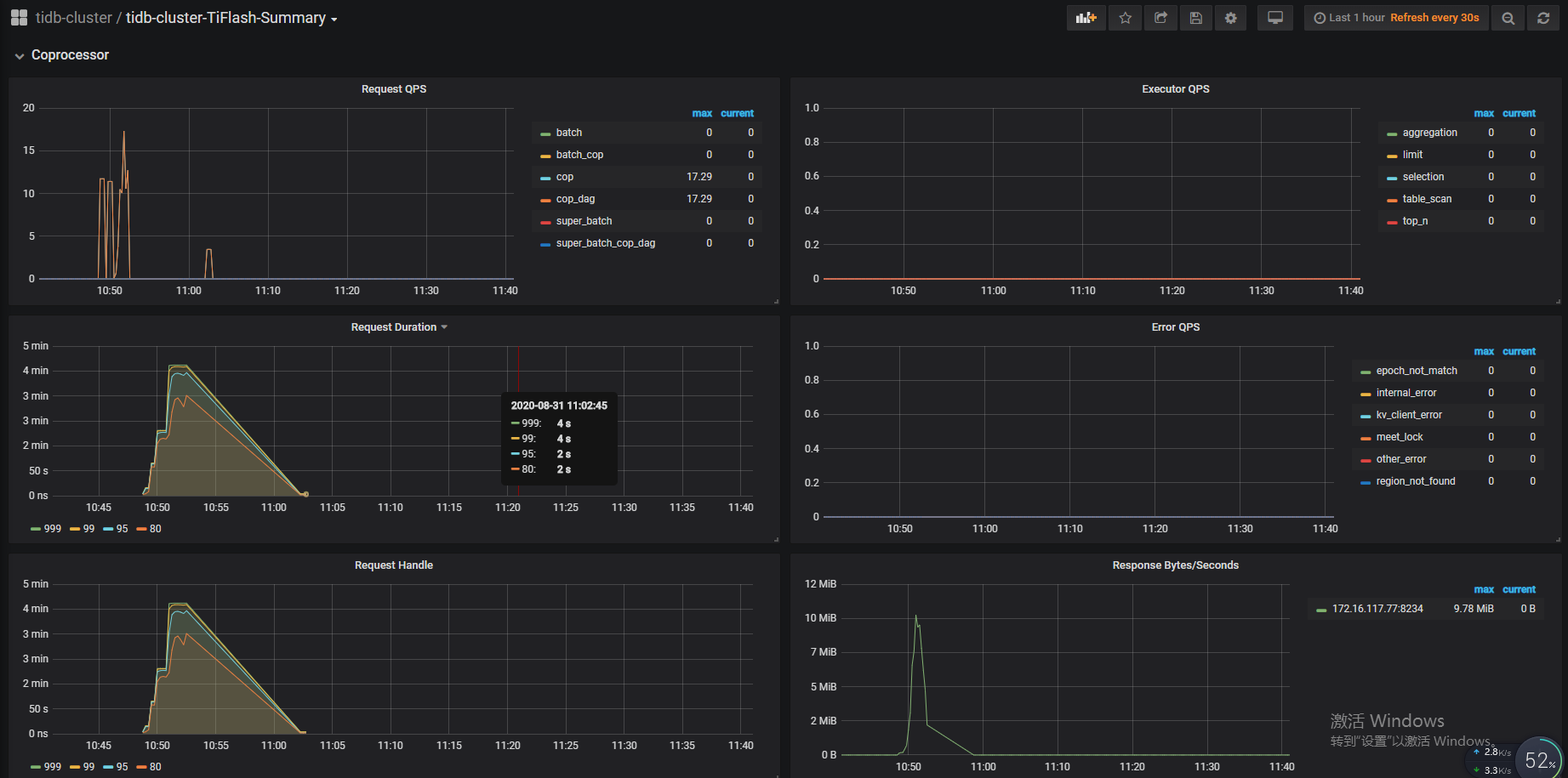
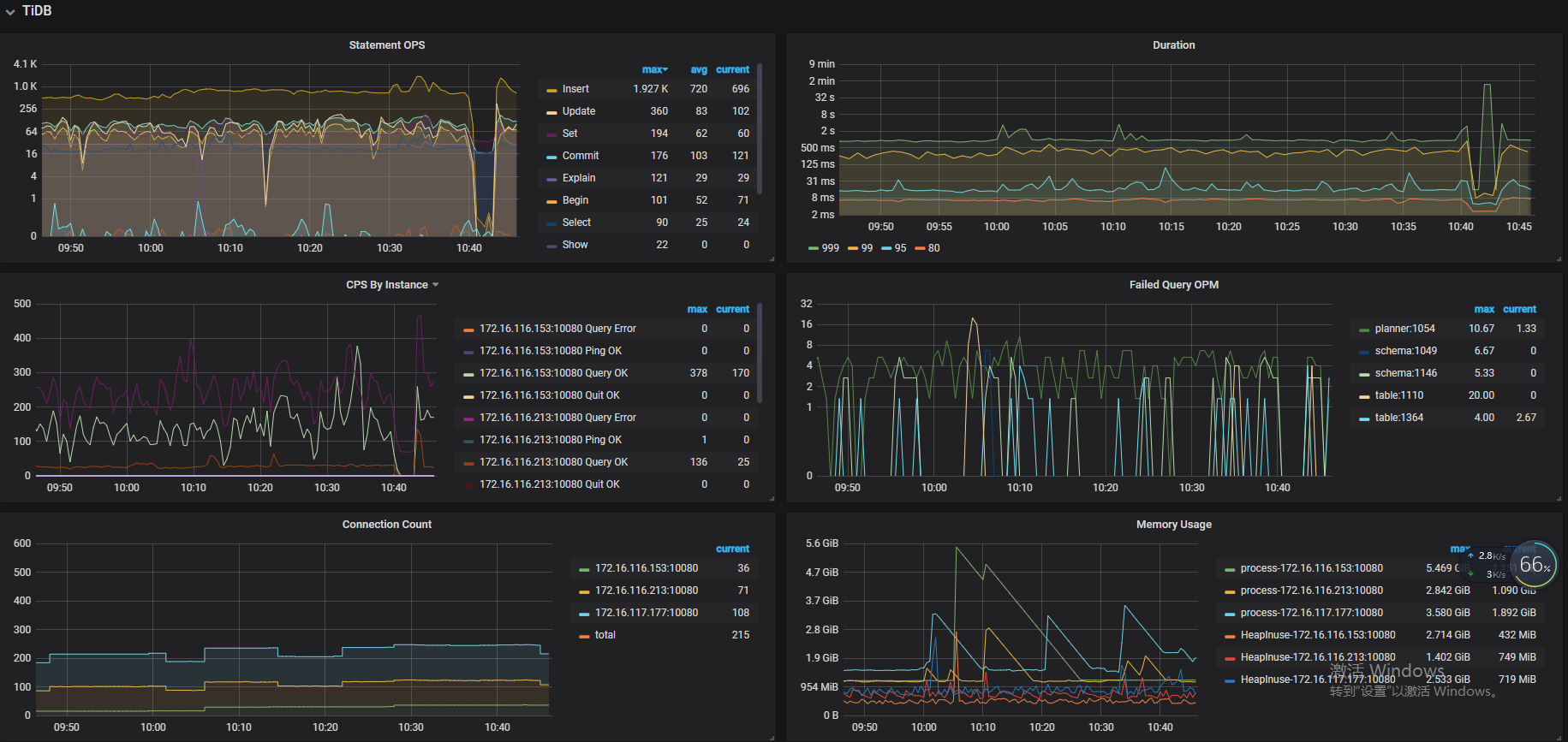
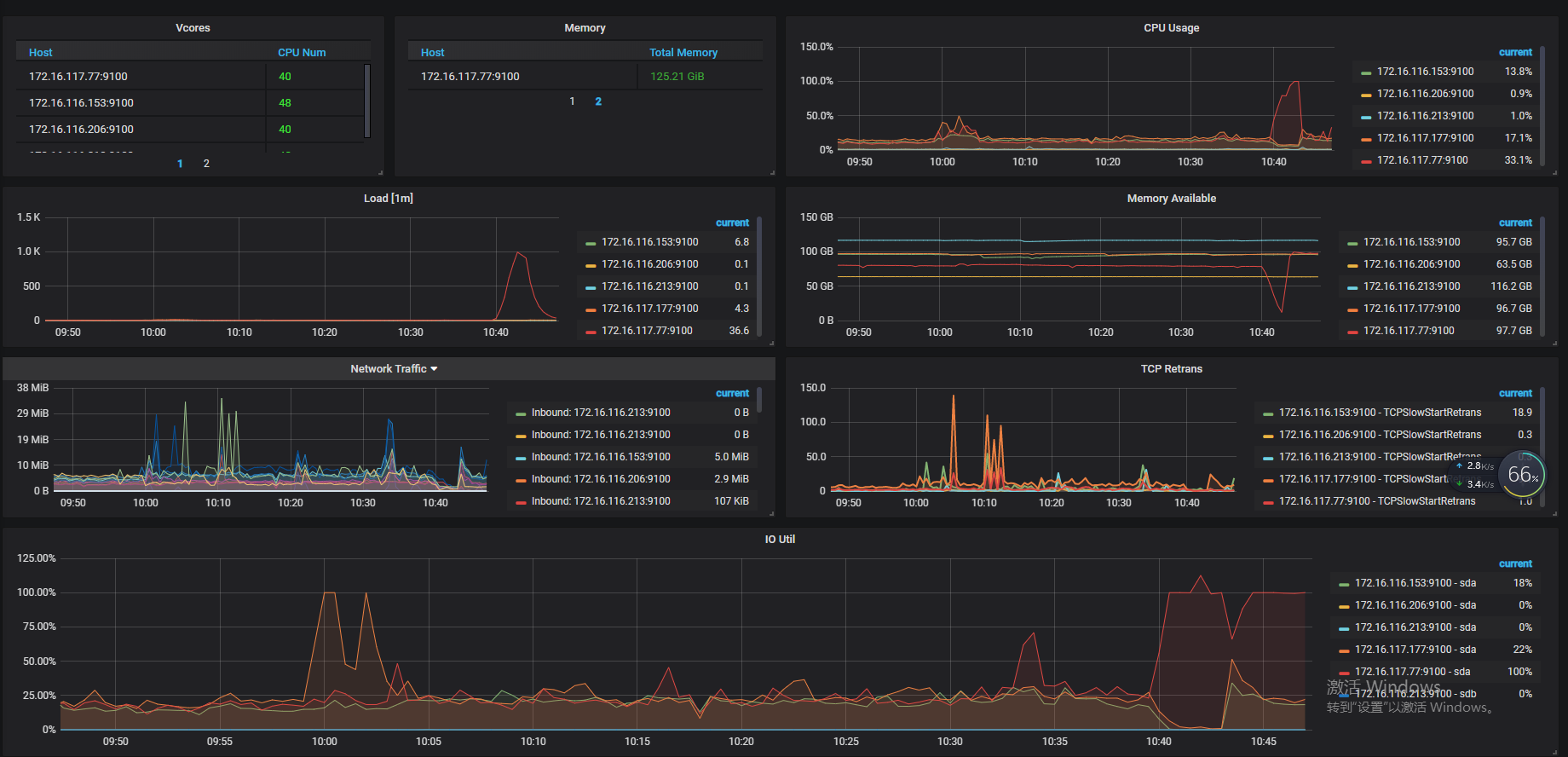
- 【问题描述】:集群时延忽然猛增,tiflash出现重启。77节点IO打满,load上千,77节点部署了tikv和tiflash。现象如下
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
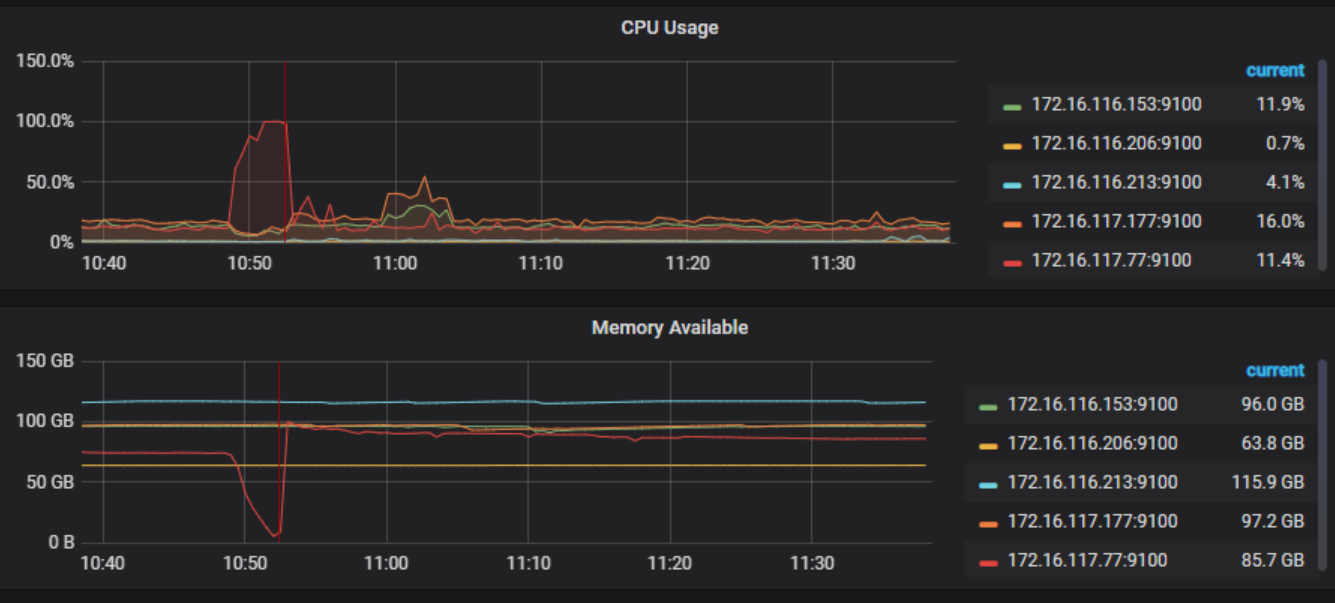
1.从监控看 77 的 cpu 到达 100%, 内存使用也几乎耗尽
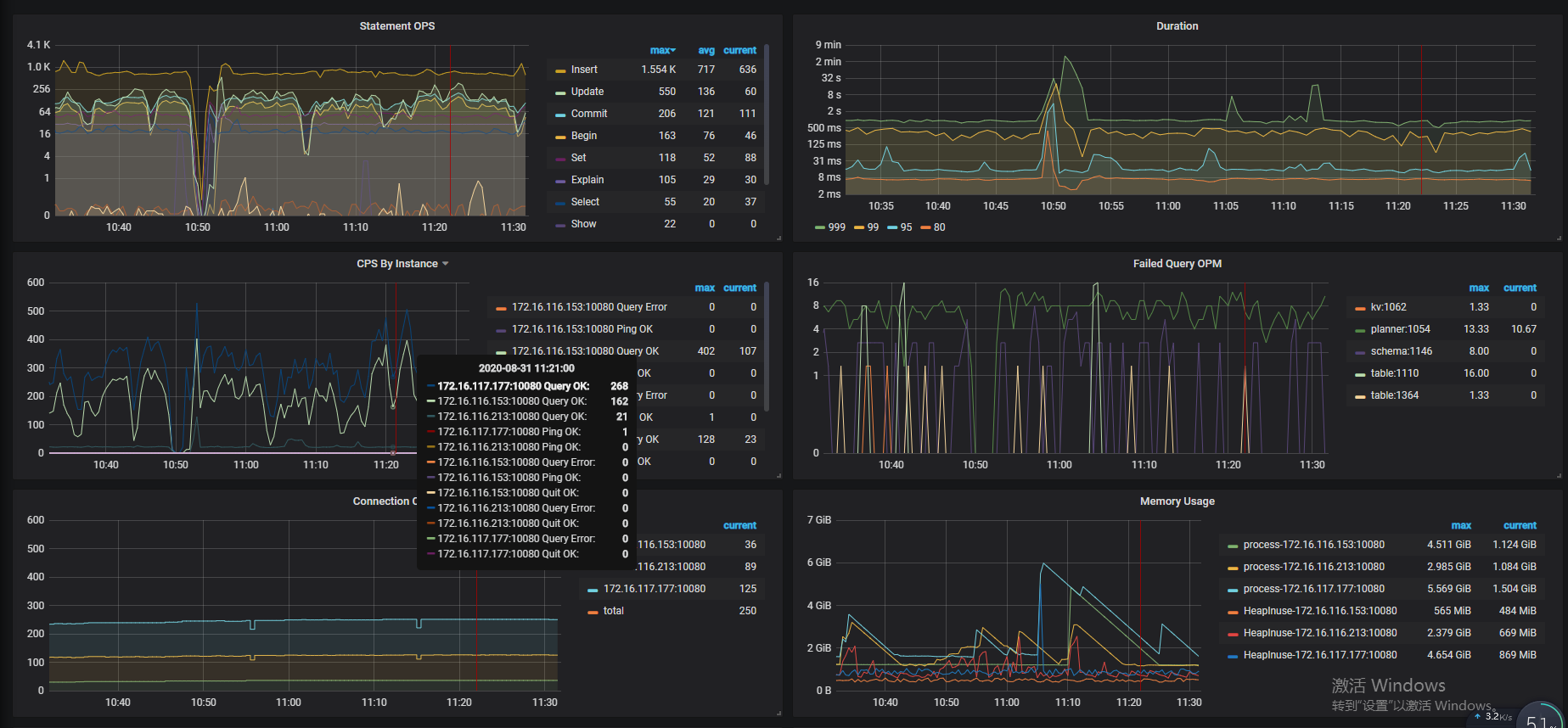
1.看了下三个tidb的慢查询日志,都是一些插入或者更新,没有大查询。
2.mem-quota-query是默认值,1073741824
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
oom-action 的值是多少?
不只是slow 日志,正常的 tidb.log 日志,在问题发生时间附近是否有信息,多谢。
荣老师,您好。日志和监控在百度云里面。
oom-action使用的是默认的log。
链接:https://pan.baidu.com/s/1JUvrlMdguOoME14j0iCLbA
提取码:sllz
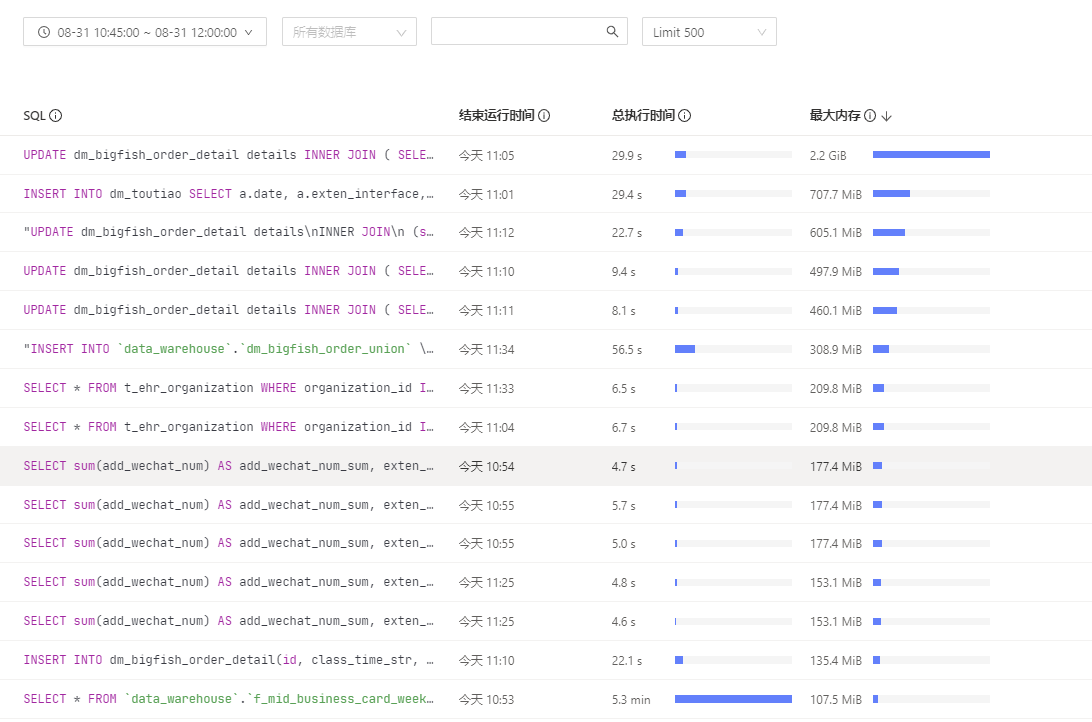
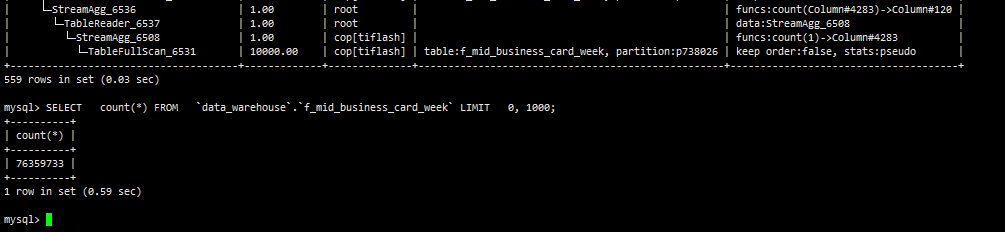
SELECT * from data_warehouse.f_mid_bussiness_card_week 这条 5.3min 的看起来挺可疑的
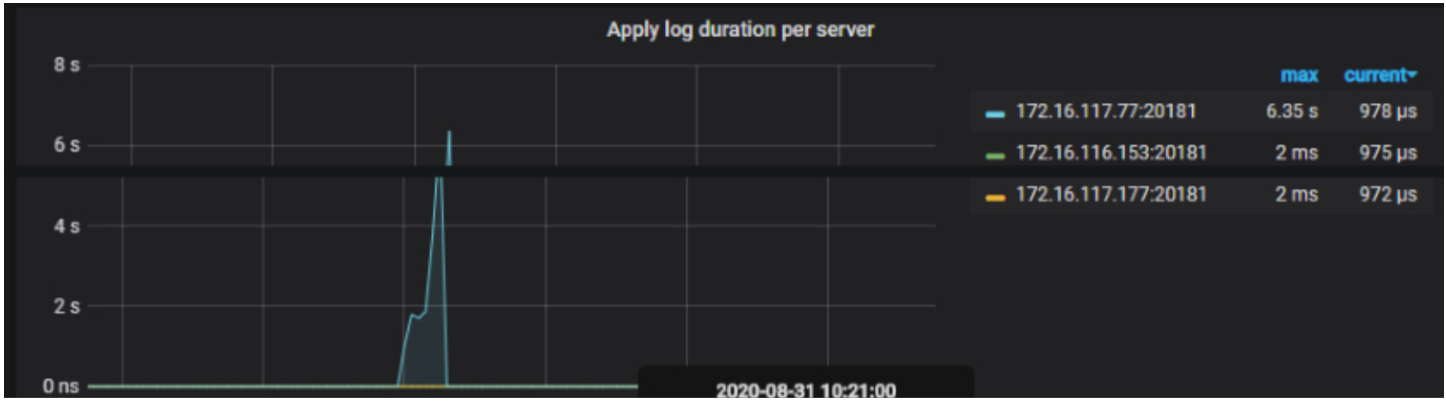
10:53 减 5.3min 差不多 10:48, 跟图上的那个异常出现的时间点差不多,CPU,内存,Coprocessor 在这个时间都有个异常波动
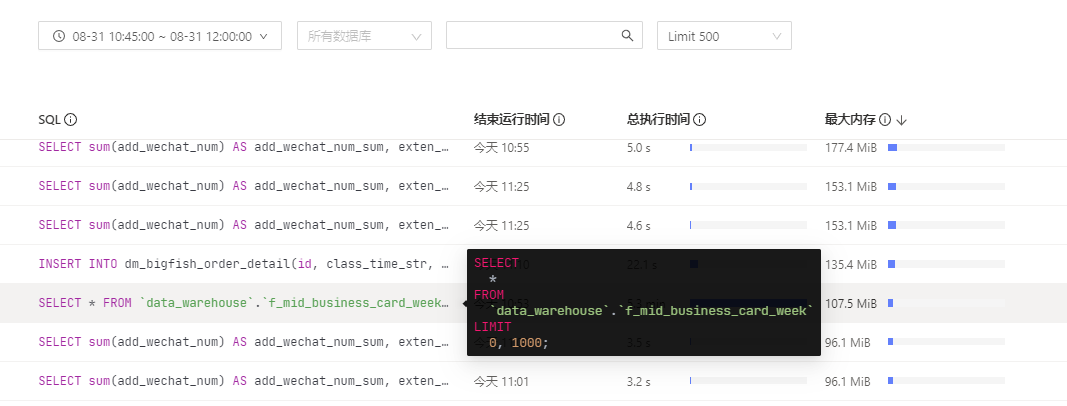
这个是limit了1000条:rofl:
确实是这个的问题,我刚重试了一下,直接执行SELECT * FROM data_warehouse.f_mid_business_card_week LIMIT 0, 1000;的时候,3秒多返回;

这个表是一个周分区表,从2018年1月1号开始,有100多个分区,添加了tiflash存储
日志麻烦取问题发生前后的时间段,太大了,无法下载,到网盘都下不下来。
查看监控,问题发生时 10:50 前后,duration 升高,qps 几乎掉底
查看 store kv cmd 时间很长达到分钟级别,主要是 cop 和batchget
查看 tikv 监控 77 上的写入都很慢,由于 IO 打满,反馈下 77 的 node_expoter 个 disk performance 监控吧
这个应该是tiflash的问题,在分区表进行limit的时候,执行计划会对每个分区进行扫描。
在和您确认下,执行 select * xx 不会导致问题,反而执行 explian sql , 不是 explain analyze sql ,都会导致集群崩溃?
这个 sql 除了您手工执行,当前业务还在执行吗?是否有并发?
1.执行explain会卡死,explain analyze也会卡住,但是没有执行完我就杀掉了
2.没有并发,这个表没有业务在查询
试试 select count(*) 看看表有多大呢?
explain analyze 会卡住正常,不过 explain 不应该呀,可能是前一条已经出问题了,到 explain 这一条语句才在客户端反映出来
跟这里应该是一个问题
在大的分区表上面,limit 不住,导致读内存读到 OOM 了
![]() 这是一个bug,需要避免在分区表中进行大跨度的查询吗?
这是一个bug,需要避免在分区表中进行大跨度的查询吗?
上面同事答复你了,没有 limit 住导致的。