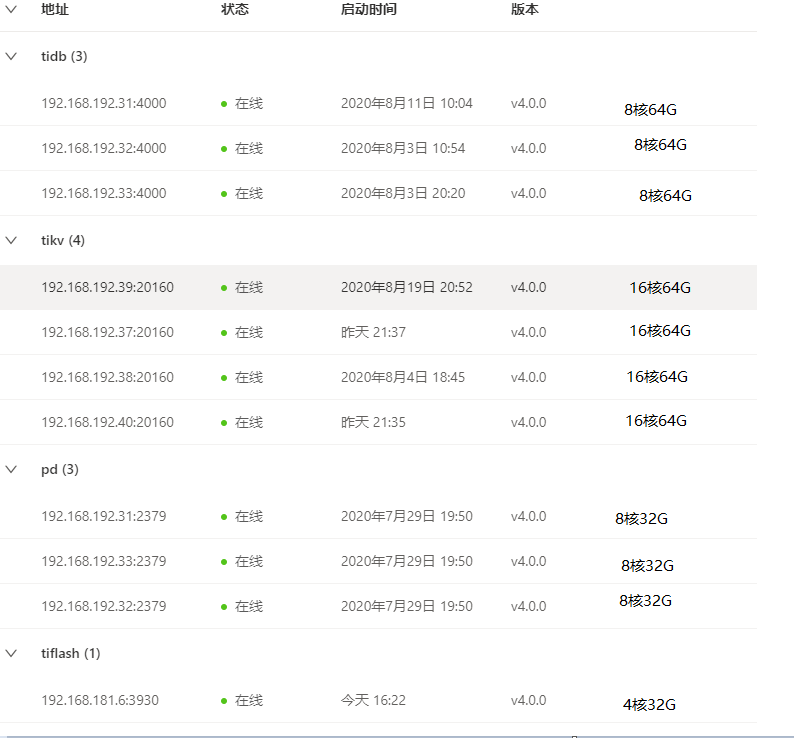
前提:
- TIDB版本4.0.0 使用Tiup管理集群
- 操作系统centos7
集群服务器配置
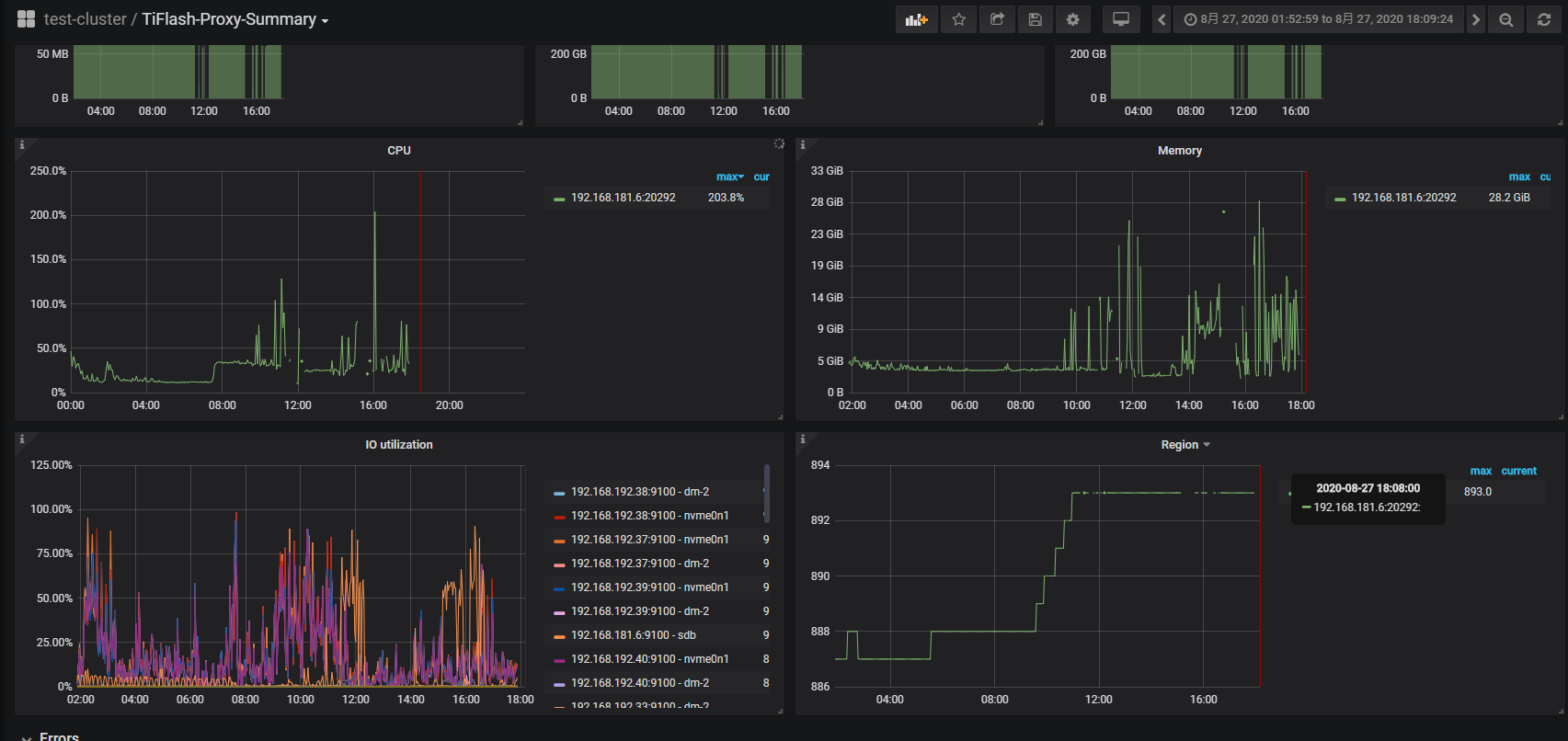
问题:
1、扩容的tiflash虽然是4核32G的,但是只复制了一张表的一个副本。
2、查看tiflash、所在服务器发现一直Out of memory,不断的重启tiflash,该如何排查定位问题?
3、有没有什么办法可以优化tiflash?
dmesg -T
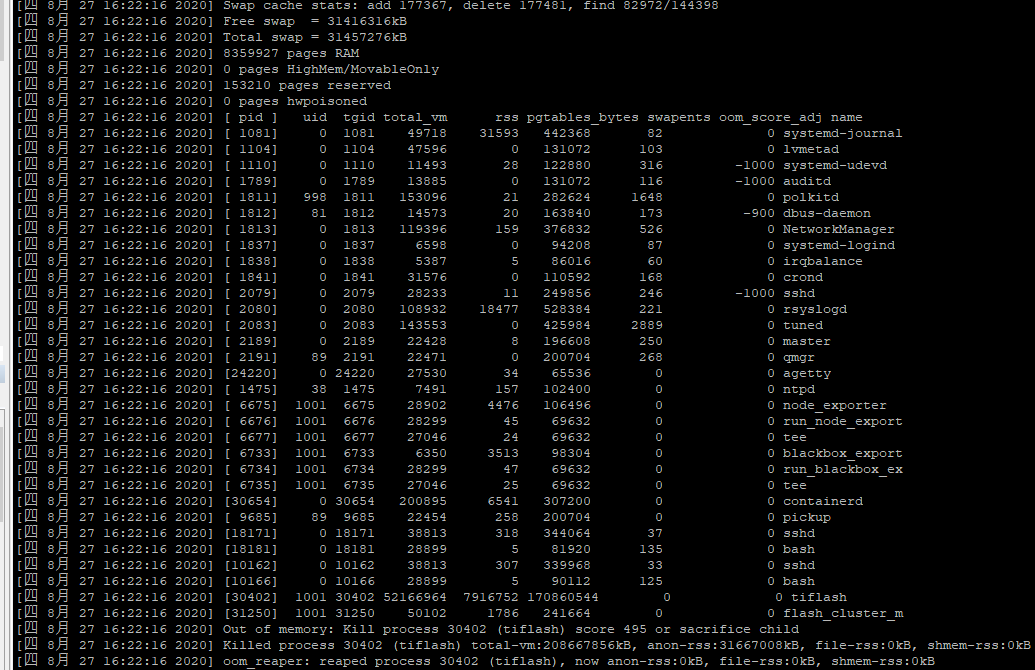
dmesg -T | grep Out

监控参考:
集群服务器配置
1、扩容的tiflash虽然是4核32G的,但是只复制了一张表的一个副本。
2、查看tiflash、所在服务器发现一直Out of memory,不断的重启tiflash,该如何排查定位问题?
3、有没有什么办法可以优化tiflash?
dmesg -T
dmesg -T | grep Out
监控参考:
请问下是表同步完成之后执行查询出现 OOM 还是在同步过程中不断 OOM ?
同步完成之后,执行查询的时候不断oom
可以调整下 mark_cache_size & minmax_index_cache_size 这两个参数试试,参考文档
https://docs.pingcap.com/zh/tidb/stable/tiflash-configuration#配置文件-tiflashtoml
配置文件部分,默认是 5G,可以调成 1G 试下。另外建议升级至 4.0.4 或者即将发布的 4.0.5 版本,对内存占用这块有优化。
[tidb@master bin]$ tiup cluster edit-config test-cluster
修改配置文件:
server_configs:
tiflash:
mark_cache_size : 1073741824
minmax_index_cache_size : 1073741824
执行生效:
[tidb@master bin]$ tiup cluster reload test-cluster -R tiflash
我理解以上这两个参数把数据缓存调小,只是起到缓解的作用,遇到大量的查询tiflash该oom还是oom是吧![]()
2、下面这个参数需要限制下么,这个参数没有太理解什么意思,可以帮忙解释下么?
max_memory_usage_for_all_queries = 0 # 所有查询过程中,对中间数据的内存限制
3、4.0.5 版本什么时候发布,有哪些比价关键的升级么,可以透露下么。![]()
1、我理解以上这两个参数把数据缓存调小,只是起到缓解的作用,遇到大量的查询tiflash该oom还是oom是吧
→ 是的,正式的生产环境部署 TiFlash 对内存要求是 128G+ ,部署的环境机器内存本身就比较小(32G),所以出现 OOM 问题也能理解。
https://docs.pingcap.com/zh/tidb/stable/hardware-and-software-requirements
2、max_memory_usage_for_all_queries 参数要跟 max_memory_usage 配合来看, max_memory_usage_for_all_queries 参数意思是对所有查询的中间数据缓存没有限制,而 max_memory_usage 则限制了单条查询的中间数据缓存大小,当一条查询的中间数据缓存超过设置的大小,语句的执行会被终止。
3、4.0.5 今天会发布(如果没有就是下周), 参考官网 《版本发布历史》 会具体介绍每个小版本的优化和修复的问题。
![]() 多谢解惑!
多谢解惑!
1、对于以下这两个参数还不是太理解,烦请给解释下呗。
mark_cache_size # 数据块元信息的内存 cache 大小限制,通常不需要修改
minmax_index_cache_size # 数据块 min-max 索引的内存 cache 大小限制,通常不需要修改
2、修改这两个参数限制是否会对查询有影响,哪方面影响。
3、如果在一次大查询中,执行计划中调用的tiflash服务器重启了,是否对此次查询有影响。
mark_cache_size, minmax_index_cache_size 均用于配置 TiFlash 存储引擎一些数据索引信息在内存中缓存的大小。用于对磁盘上数据块的初步过滤,优化读取过程中 I/O 操作。如果所有 TiFlash 节点都发生异常,目前并不会重新路由到 TiKV 节点进行重试。一点是性能可能会有较大的变化,对业务也有风险,另外是整个执行计划会需要重新生成。
在所有 TiFlash 节点一段时间内不能恢复的情况下,如果能接受查询降级到 TiKV 节点对外服务,需要业务使用 Engine 隔离,调整涉及到 TiFlash 副本数据的 SQL,让 TiDB 仅访问 TiKV 节点。
理解了,非常感谢您做出如此详细解释,多谢![]()
![]() 好的
好的
v4.0.5 版本昨天已经正式发布了。
请问通过升级版本/调整参数,OOM的问题有得到解决吗?
多谢看到了,因为是生产环境这两天是数据交付日,得延一延,有结果我会反馈
多谢。