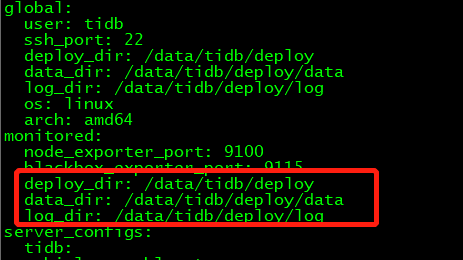
[ Serial ] - SSHKeySet: privateKey=/home/tidb/.tiup/storage/cluster/clusters/preprod-tidb-cluster/ssh/id_rsa, publicKey=/home/tidb/.tiup/storage/cluster/clusters/preprod-tidb-cluster/ssh/id_rsa.pub
[Parallel] - UserSSH: user=tidb, host=10.x.x.145
[Parallel] - UserSSH: user=tidb, host=10.x.x.118
[Parallel] - UserSSH: user=tidb, host=10.x.x.119
[Parallel] - UserSSH: user=tidb, host=10.x.x.120
[Parallel] - UserSSH: user=tidb, host=10.x.x.119
[Parallel] - UserSSH: user=tidb, host=10.x.x.121
[Parallel] - UserSSH: user=tidb, host=10.x.x.122
[Parallel] - UserSSH: user=tidb, host=10.x.x.116
[Parallel] - UserSSH: user=tidb, host=10.x.x.118
[Parallel] - UserSSH: user=tidb, host=10.x.x.118
[Parallel] - UserSSH: user=tidb, host=10.x.x.121
[Parallel] - UserSSH: user=tidb, host=10.x.x.117
[Parallel] - UserSSH: user=tidb, host=10.x.x.123
[Parallel] - UserSSH: user=tidb, host=10.x.x.116
[Parallel] - UserSSH: user=tidb, host=10.x.x.145
[Parallel] - UserSSH: user=tidb, host=10.x.x.145
[ Serial ] - StartCluster
Starting component pd
Starting instance pd 10.x.x.119:2379
Starting instance pd 10.x.x.120:2379
Starting instance pd 10.x.x.118:2379
Start pd 10.x.x.120:2379 success
Start pd 10.x.x.119:2379 success
Start pd 10.x.x.118:2379 success
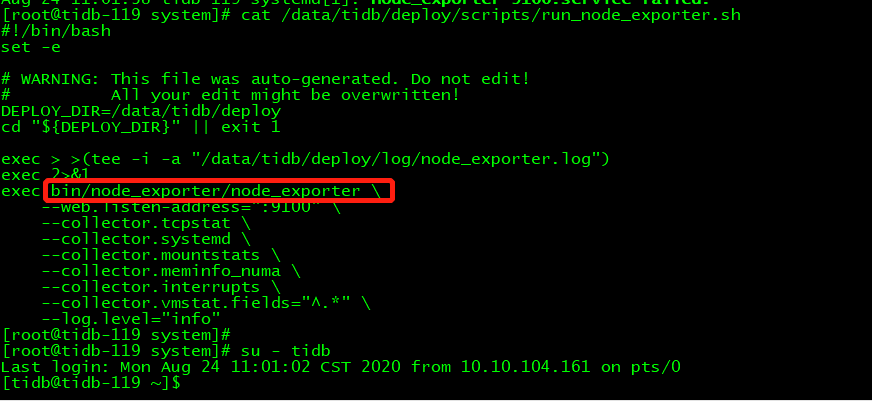
Starting component node_exporter
Starting instance 10.x.x.119
retry error: operation timed out after 2m0s
10.x.x.119 failed to start: timed out waiting for port 9100 to be started after 2m0s
Error: 10.x.x.119 failed to start: timed out waiting for port 9100 to be started after 2m0s: timed out waiting for port 9100 to be started after 2m0s
Verbose debug logs has been written to /home/tidb/logs/tiup-cluster-debug-2020-08-23-13-57-03.log.
Error: run /home/tidb/.tiup/components/cluster/v1.0.9/tiup-cluster (wd:/home/tidb/.tiup/data/S8SrFDy) failed: exit status 1
看报错是 TaskFinish {“task”: “StartCluster”, “error”: “\t10.10.104.119 failed to start: timed out waiting for port 9100 to be started after 2m0s: timed out waiting for port 9100 to be started after 2m0s”, “errorVerbose”: "timed out waiting for port 9100 to be started after
[tidb@k8s-work-161 preprod-tidb-cluster]$ tiup cluster display preprod-tidb-cluster
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.0.9/tiup-cluster display preprod-tidb-cluster
tidb Cluster: preprod-tidb-cluster
tidb Version: v4.0.2
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
10.10.104.145:9093 alertmanager 10.10.104.145 9093/9094 linux/x86_64 inactive /data/tidb/deploy/data.alertmanager /data/tidb/deploy
10.10.104.116:8249 drainer 10.10.104.116 8249 linux/x86_64 Down /data/tidb/deploy/data/drainer-8249 /data/tidb/deploy/drainer-8249
10.10.104.145:3000 grafana 10.10.104.145 3000 linux/x86_64 inactive - /data/tidb/deploy
10.10.104.118:2379 pd 10.10.104.118 2379/2380 linux/x86_64 Down /data/tidb/deploy/data.pd /data/tidb/deploy
10.10.104.119:2379 pd 10.10.104.119 2379/2380 linux/x86_64 Down /data/tidb/deploy/data.pd /data/tidb/deploy
10.10.104.120:2379 pd 10.10.104.120 2379/2380 linux/x86_64 Down /data/tidb/deploy/data.pd /data/tidb/deploy
10.10.104.145:9090 prometheus 10.10.104.145 9090 linux/x86_64 inactive /data/tidb/deploy/prometheus2.0.0.data.metrics /data/tidb/deploy
10.10.104.118:8250 pump 10.10.104.118 8250 linux/x86_64 Down /data/tidb/deploy/data/pump-8250 /data/tidb/deploy/pump-8250
10.10.104.119:8250 pump 10.10.104.119 8250 linux/x86_64 Down /data/tidb/deploy/data/pump-8250 /data/tidb/deploy/pump-8250
10.10.104.116:4000 tidb 10.10.104.116 4000/10080 linux/x86_64 Down - /data/tidb/deploy
10.10.104.117:4000 tidb 10.10.104.117 4000/10080 linux/x86_64 Down - /data/tidb/deploy
10.10.104.118:4000 tidb 10.10.104.118 4000/10080 linux/x86_64 Down - /data/tidb/deploy
10.10.104.121:9000 tiflash 10.10.104.121 9000/8123/3930/20170/20292/8234 linux/x86_64 Down /data/tidb/deploy-tiflash/data-tiflash-9000 /data/tidb/deploy-tiflash
10.10.104.121:20160 tikv 10.10.104.121 20160/20180 linux/x86_64 Down /data/tidb/deploy/data /data/tidb/deploy
10.10.104.122:20160 tikv 10.10.104.122 20160/20180 linux/x86_64 Down /data/tidb/deploy/data /data/tidb/deploy
10.10.104.123:20160 tikv 10.10.104.123 20160/20180 linux/x86_64 Down /data/tidb/deploy/data /data/tidb/deploy