tikv-detail监控信息:
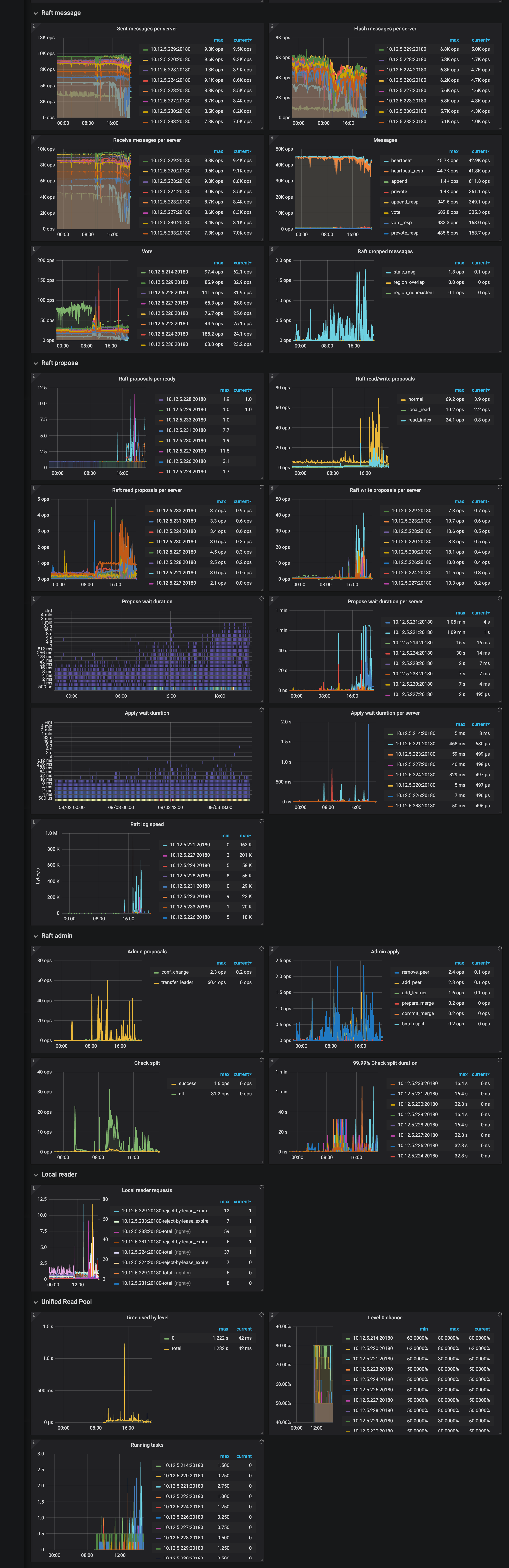




对应的pd log和部分tikv log:
10.12.5.229_kv.log (1.8 MB)
10.12.5.113_pd.log (2.3 MB)
10.12.5.114_pd.log (2.6 MB)
10.12.5.115_pd.log (2.4 MB)
10.12.5.214_kv.log (1.9 MB)
10.12.5.226_kv.log (1.9 MB)
10.12.5.228_kv.log (1.8 MB)
请问是哪个组件出了问题?
- 从监控看花费了不少时间在 balance leader
- 从tikv监控查看IO使用率很高
- leader 一直在变化
- 看起来感觉是机器负责太高,导致leader不断切换,另外集群使用率已经72%。当前集群可能不足以支持目前的负责,可以试试扩容分担压力。

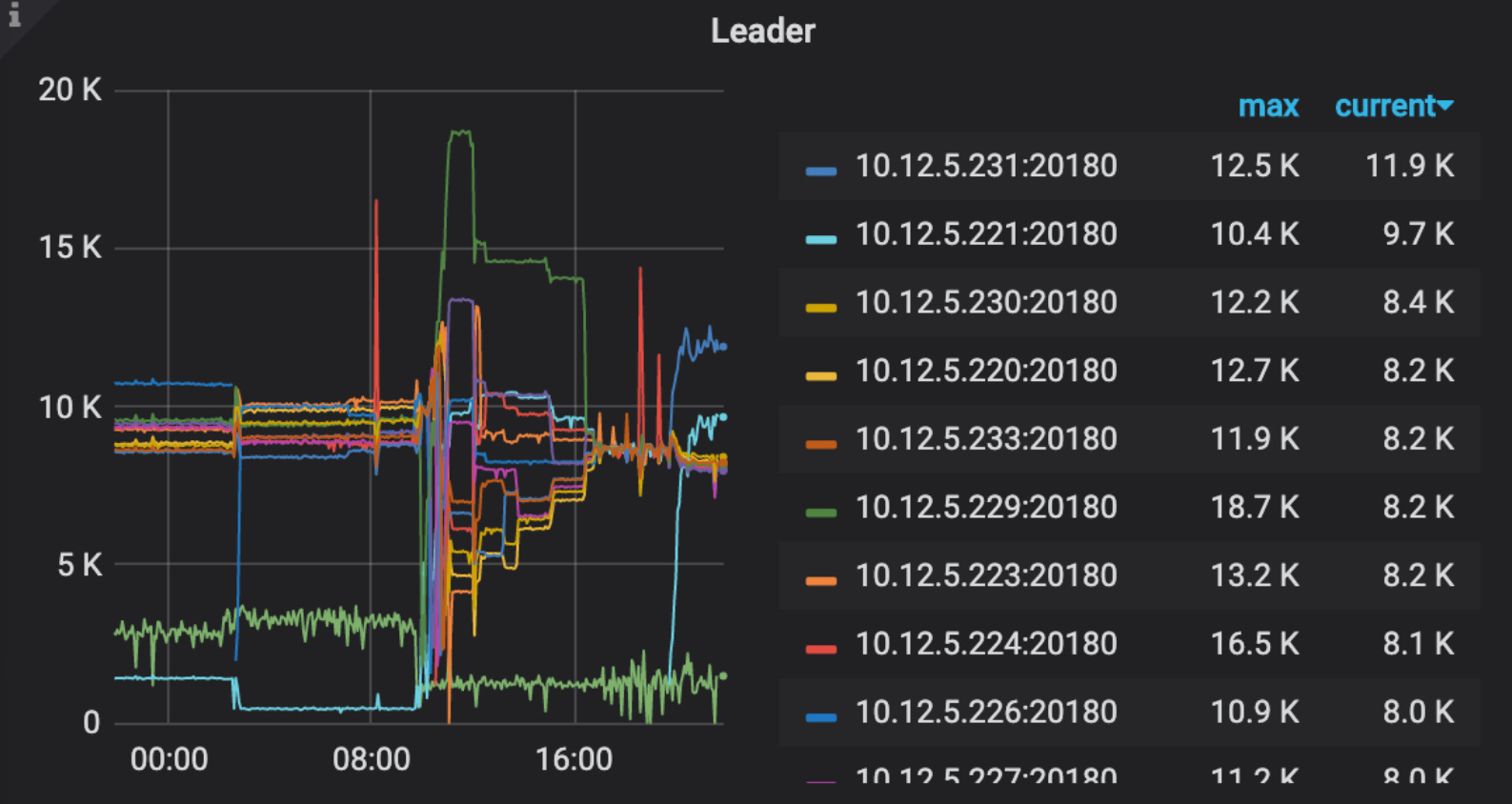
好的,因为现在10个tikv节点本质上是基于三台服务器所创建的虚拟机,确实会存在机器负载不过来的情况。现在计划将10个节点的1T空间的tikv迁移成四台3T的tikv节点(逐一迁移),这样是否可行?
- 那么每台 tikv 中的 region 数量会更多,可能需要开启 静默 region
- 如果逐一迁移,原 tikv 和 新 tikv 的容量相差比较大,可能导致 leader 不均衡。
- 感觉可以先用4台机器测试一下,如果可以支持业务那么可以统一迁移。
- 使用
raftstore.hibernate-regions开启静默状态?此时是否不能进行业务操作? - 用4台机器测试一下是怎么做呢?
1)是否还能用当前tidb和pd组件,还是需要重新创建?
2)统一迁移是指一次性添加四个tikv组件进行扩容?
3)迁移过程中怎么去加速迁移?是否根据https://asktug.com/t/topic/1669一文,修改一下参数?
-
leader-schedule-limit:控制 Transfer Leader 调度的并发数 -
region-schedule-limit:控制增删 Peer 调度的并发数
-
开启静默 region 不影响业务,这里是猜测因为如果从 10 个 tikv 导入 3 个 tikv,那么每个 tikv 中的 region 数量会增加很多,可能导致 raft store cpu 增高,这时可以考虑开启静默 region
[FAQ] 如何开启 静默 region or hibernate region -
业务上需要你们最好测试下,毕竟集群配置都改变了,不是说单纯的增加,是数量减少,只增加了磁盘容量,不好评估。 可以按照你的方案先扩容一台试试,
-
可以参考文档增加均衡速度。