TUG 于 2019 年 6 月 23 日成立,值此一周年之际,TUG 管理委员会与各区域小组,将联合举办周年庆系列活动,活动连续举办了四周。下面我们来回顾一下,在 8 月 2 日,由 TUG 北京组承办的,主题为《TiDB 上云实践》的华北场 TUG 活动的精彩内容:
近年来,数据库上云的趋势越来越强,实现路径逐渐清晰,众多互联网大厂纷纷试水将数据库搭建在容器环境上。TiDB 作为云原生数据库,从一开始就积极拥抱云,为更好管理云上、容器化上的集群而开发的 TiDB-Operator GA 一年多,已发展到较为成熟的版本,被不少用户选择,开始在生产环境中使用,逐渐将本地部署的 TiDB 向云上迁移。为了方便大家交流,传递相关经验,避免重复踩坑,TUG 周年庆系列活动专门就“ 如何将 TiDB 搬上云 ”这一话题进行深度探讨。
本次活动嘉宾

首先,各位嘉宾简单介绍了一下各自在上云项目上的进度
黄潇:本次活动的发起者,美团已经在边缘的线上业务开始尝试上线 TiDB in K8S 。
朱博帅:目前爱奇艺处在测试环境的大量实践阶段,已经开始准备在线上环境落地。
张允禹:知乎和 PingCAP 已经达成了战略合作,目前有 4.0 的线上集群在 K8S 上运行。
王云鹤:同程很早自研了雷神系统,帮助 TiDB 在云化平台的落地。
李银龙:目前主要负责马上消费的 TiDB 容器云平台相关落地,落地较早,已经全量上线。
随后,大家围绕各个阶段的重点问题,开始一个圆桌讨论
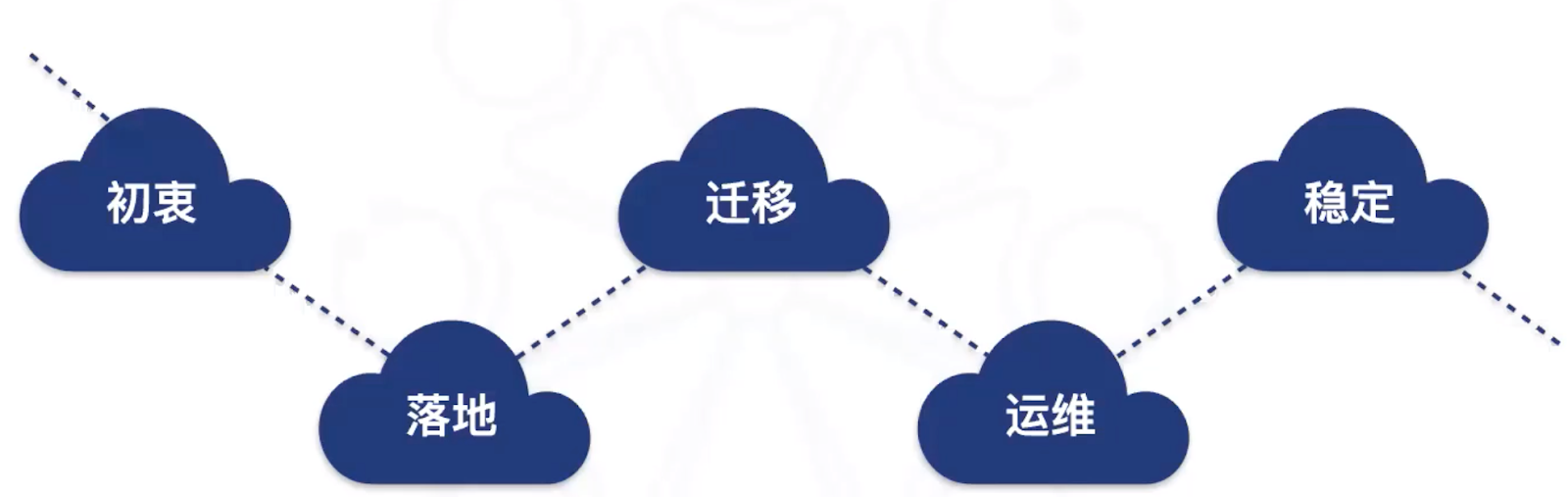
【初衷】上云的初衷/目的,预期收益有哪些?

李银龙:初衷比较朴素,首先认可开源文化,对新型分布式数据库非常认可,但早期 TiDB 对服务器要求非常高,又有三副本,基本一套集群需要 9 台服务器,所以希望通过容器云来提高硬件的资源利用率,降低服务器成本。没有选择直接混合部署,是担心互相影响和运维复杂,而上云可以通过自动化提高运维人效。
王云鹤:TiDB 上云在 MySQL 和 Mongo 之后,之前资源利用率各方面体验很好,所以自然启动 TiDB 上云。自研了雷神容器编排系统,和 K8S 各自有优缺点。目前痛点是需要弥补雷神系统的不足,如升级等运维操作,节省这块的人力成本。
张允禹:由于 DBA、研发人员比较紧张,也有很多内部的集群,对从库的要求没有那么高,MySQL 的维护成本很高,上线 TiDB 也是为了将这些集群集中存储到一个大的 TiDB 集群,可以保障很高的可用性,升级、扩容等运维操作也可以一次性完成,提高人效。
朱博帅:首先的目标是降低成本,在线下很多是独占机器的,业务在预测规模和实际可能不匹配,导致负载和成本降不下来,希望在 K8S 上解决这个问题,提高部署的密度;另外是运维方面,operator 相比 ansible 在扩缩容、部署、升级这些操作变的非常方便。
黄潇:目前线上有 10 套集群上云了,还处在试点阶段。痛点和大家类似,即使用虚拟机资源利用率也不太高,另外对口 TiDB DBA 不好招,希望上云,让 K8S 自动管理自己,将经验沉淀到 operator 中。弹性伸缩目前简单体验了下,还是有提升空间的,也希望官方可以提供合作开发的接口。坚信未来的方向一定是上云的,这点对 TiDB 的思路是非常赞同的。
【落地】对现有硬件体系有哪些调整,如网络、本地存储、宿主参数优化?

朱博帅:在这几方面目前还处在探索阶段。首先网络部分,目前在云上和云下是不通的,在云上通过 nodeport 的方式,将 TiDB 暴露出去,将来会真正把网络在底层打通,主要首先考虑性能,目前在调研方案,在 load balance 这块,因为公有云有比较成熟的方案,私有云也需要完善起来,内部也有 load balance 的方案,需要和 K8S 的网络打通,链路要尽可能短,转发要尽可能快;本地存储这部分,目前使用默认 external storage 方案, 也就是 local volume provisioner 方案,但感觉配置较多,运维不友好,正在调研其他方案,考虑把本地磁盘利用起来,实现云原生的部署方案,既要考虑挂载远程磁盘,也要能挂载本地磁盘,成本降低,运维友好,性能较高;宿主机参数优化,目前参考官方默认的优化方案,结合其他数据库的优化,有一个统一的方案,另外不止宿主机,TiDB 本身的参数和线下是一样的。
张允禹:容器网络方面,跨级群的访问方案,需要打通 cluster ip,比如在金山机房的集群,在 baidu 机房的 K8S 中的业务想访问它,baidu 的 K8S 集群会启动一个 watch 金山机房 api server 的服务,如果金山机房创建了一个 service,会在 baidu 同步创建一个 service,external ip 会是金山机房的 cluster ip,在 baidu 访问金山的 cluster ip 就是 baidu 的 external ip,通过 kub-proxy 转发金山机房,集群内是通过 lb 的访问方式。本地存储,使用大家推荐的 local-pv,有一个小槽点,管理 pv 时信息展示不出 pv 在哪台物理机器。没有考虑联邦,是觉得 K8S 本身不太推荐,看未来新版。
李银龙:主要感谢容器团队的 K8S 专家和网络专家的努力,先说一个结论吧,一般大家会担心从本地上云端性能会不会降低,从我们实践结果来看, 性能和物理 TiDB 从 sysbench 测试结果来看,经过调优是可以消灭肉眼可见的差距。最早从很早的 operator 版本看,性能是比不上物理 TiDB 的,就产生研究优化的想法,反复对比物理 TiDB 上官方提供的优化参数,一个是物理 TiDB 要求设置 CPU 为 max-performance 模式,还有中断模式的设置,而容器环境没有设置,修改后性能就差不多了。本地存储 local-pv 使用官方推荐的方式,保留策略使用 retain 方式,但实际是比较担心操作错误。local volume provisioner 早期使用的 2.3.3 版本,遇到清理 pv 不干净的 bug,这个持续了很久的疑惑,升级到 2.3.4 后解决了。容器网络使用 underlay 方案,没有选择 overlay 的考虑是,overlay 的优势是对网络的限制更少,underlay 的优势是性能更好,基于性能考虑使用 underlay。
黄潇:大家都在使用推荐的 local volume provisioner 方式,我在使用上的感受是比较固化,在初始化宿主机的时候,就需要把磁盘空间预分配出来,但线上扩容 node 的时候,并不一定是需要固定那么大小的,TiKV 和 PD 都需要本地存储,但空间规模是差很多的,这时在初始化宿主机预分配空间,就要提前规划 PD 和 TiKV 的比例,但由于随时上线的集群不同,通常是不能提前知道这个比例的,如果能动态分配会更满足需求,目前每次初始化需要找 K8S 的工程师去调整这个比例,这个是一个痛点。
李银龙:这个问题是比较头疼,TiDB 还稍微好,因为都是比较大的集群,MySQL 也有类似的问题。我们的做法是,通过标签,部分宿主机放了很多的 PD 节点,PD 和 TiKV 使用不同规范,但这种方式有个问题是,单个宿主 PD 太多了,如果机器坏掉了,会影响很多集群。PD 打散还是集中部署,这其实是一个人生选择,我们选择通过内部规划面对这个风险,来清晰的控制风险。
朱博帅:这个问题我们也很痛,必须自己规划,目前每台机器既有 PD 也有 TiKV,两种 storage class,一种是PD 用,一种是 TiKV 用。PD 容量会比较小,TiKV 会比较大,数量比例是固定的,给 PD 比较少,每台宿主都这么分配,磁盘会做分区,每个分区上不同的 local-pv,剩下的交给 operator 。磁盘做分区,利用率方面有优势,可能存在 IO 物理隔离的问题,我们在线下也做了分区的压测,与不分区的性能差不多,所以选择了分区方式。
李银龙:磁盘分区的方式,是否会担心迁移数据初始化数据阶段对已有集群的 IO 影响?
朱博帅:通过内部工具来做迁移,会控制一下 load 的并发速度,降低 IO 影响
王云鹤:我们是使用裸磁盘直接挂在文件系统的方式,存储这里我们使用同一块大盘部署 TiKV,没有使用分区,可以更合理的利用空间,关于编排这里,雷神系统灵活在可以指定 TiKV 迁移到比较空闲的机器上,这是比 K8S 灵活的地方。
话外音:关于 volumn 无法动态的问题,活动后和官方讨论,可以通过动态创建 PV 的目录的方式。也就是说,需要 PV 的时候再创建或者挂载目录即可。
【迁移】现有集群上云做了哪些工作,如迁移怎么做,数据库中间件如何兼容?

王云鹤:雷神系统自研比较早,当时 K8S 还不太成熟,管理的容器有很多灵活方便的地方。比如资源分配,比如可以根据场景灵活指定不同 TiDB pod 节点的 cpu 和内存分配大小,K8S 上只能做到一模一样的,没法单独设置。另外 TiKV 的迁移,雷神系统也是比较方便的,比如可以迁移某些节点到指定空闲的节点,K8S 在指定节点上比较困难。但未来还是计划从雷神转到 K8S 上,主要是考虑公司整体方面策略,随着 K8S 编排的成熟,后续 mysql、mongo、应用也会考虑上 K8S,TiDB 是一个试点。目前已经在 K8S 上线了一套集群,细节问题,比如日志的拉取有些问题。
李银龙:这个时间隔的比较久,当时社区上没有太多可以借鉴的经验,文档也比较少,operator 还没有 1.0。当时第一个环节,就想知道这个是否靠谱,部署了一个环境 sysbench 压测了一个月,发现没有出现大问题,下一个环节,就开始考虑网络和 local-pv,再后来就要考虑物理 TiDB 到容器的迁移,一个很好的契机,容器云的机器配置更好一些,所以我们推动总账这个标杆的业务上了容器,当时只有 200GB 以内,现在就比较大了。迁移过程使用的快照+binlog 的逻辑迁移方式,发现数据对不上的问题,后来发现是容器上的默认时区和物理环境差了 8 个小时。目前的问题是在集群非常大的时候,如何从单机房调整到同城三中心的方式,以及 K8S 的版本还是 1.0.6 的版本,当前已经是改动比较大的 1.1 版本。逻辑迁移性能各方面都比较差,目前在探索物理迁移的方式。数据库中间件倒是没有使用。
黄潇:美团也遇到类似的问题,稍微大一些的 TiDB 集群使用逻辑方式往云上迁移是比较难忍受,目前在想通过物理备份的方式迁移,另外在考虑将一个 PD 节点迁移到云上,通过 raft 本身的复制方式,通过扩缩容逐步往云上迁移,最大的好处是,不用考虑迁移中数据的一致性,不需要数据校验,也不会出现时区、数据类型等各种问题,而且可以实现灰度的平滑迁移,遇到性能下降可以随时回头终止迁移。MySQL 有 pt-checksum 的工具可以做,但 TiDB 数据量较大,没有类似主从同步校验的机制,就很难校验。
张允禹:我们也有 TiUP 部署的集群,要迁移到云上,也在考虑扩缩容的方式来做。但之前先考虑实现不同的 group,指定 PD 的地址,加入现有的集群内,最终实现一个 TiDB 集群跨扩个 K8S 集群,后续也会考虑 TiUP 迁移到云的开发。
李银龙:需求肯定是刚性需求,技术上也是行得通的,关键在怎么实现
朱博帅:目前主要是单 K8S,迁移有内部工具,迁移周期会长一些。也有跨 K8S 集群部署 TiDB 集群的需求,关于中间件兼容,TiDB 没有必要搞 proxy 了,直接通过外部访问即可。迁移时会考虑线下集群,考虑做迁移回滚,所以涉及到一个双向同步的问题,也是通过内部同步工具来实现,具体是通过 pump+drainer 来实现的,后续改为 CDC 的增量方式,目前正在开发升级同步工具
李银龙:是否考虑开源同步工具
朱博帅:已经在考虑开源,目前在和 PingCAP 考虑技术合作这个项目
话外音:关于在线迁移工具,目前有 PR 正在设计和开发:
https://github.com/pingcap/TiDB-operator/issues/2895
https://github.com/pingcap/TiDB-operator/pull/3003
在 TidbCluster 上增加了一个 PDAddress 属性。
从 Ansible 在线迁移到 K8s 的大致思路:在 K8s 上新部署一套 TiDB 集群,新增了一个属性 PDAddress,这个填写 Ansible 集群的 PD 地址。
首先启动 2 个 PD 节点(join 到 Ansible PD 集群里面),启动少量 TiKV 节点,然后逐渐减少 Ansible 部署的 TiKV 节点数量,同时逐渐增加 K8s 内集群的 TiKV 节点数量。最终 Ansible 部署的 TiKV 节点数为 0,利用 Raft 复制能力将 Ansible 部署的集群迁移到 K8s 集群上。PD 迁移的思路类似。
这种操作方式,比较平稳,也不需要担心数据正确性验证,甚至对业务影响也相对较小。
【运维】如何做好云上服务的运维保障,以及日志、监控、告警如何落地?

朱博帅:日志收集目前倾向 sidecar 方式,内部已经有日志收集工具,目前要做的是就是支持云上服务,目前 sidecar 已经可以在线上使用。监控依然使用 operator 提供的 monitor 组件,它已经将 Prometheus 和 grafana 集成到里面。告警方面去掉了一些不需要的报警项,和外部报警系统打通,存在问题是告警使用 local-pv 方式,存在报警策略丢失的风险
黄潇:可以考虑 Prometheus 的 nfs 方式,解决报警策略丢失的问题
朱博帅:是的,如果有可靠的 nfs 服务可以解决这个问题
张允禹:整个知乎拥抱开源,隔壁团队有提供完善的 Prometheus 监控和告警,我们把 Prometheus 指标提供给隔壁团队。
李银龙:我们遇到 operator 给每个集群创建一套监控,发现 Prometheus 太多的问题,希望有统一的 Prometheus 的方式
黄潇:我们使用官方的方式,可以理解每个集群单独 Prometheus ,放在一起会压力非常大。我们把 Prometheus 存储从 local-pv 挪到 nfs 上解决自身存储上的问题,另外通过内部 operator 的方式,如果 Prometheus 挂掉可以感知到 ip 变化,将地址同步到 cmdb。grafana 可以放在一起是更好的,统一 web 入口。同时不用太关心 nfs 慢的问题,监控慢一点问题不大
王云鹤:雷神上部署的 TiDB 集群,最大的问题是 OOM 的问题,自己做了容器存活检测,会立刻自动拉起故障的组件,而 K8S 大约在 1 分钟左右自动拉起。另外需要注意设置容器的内存分配。日志这一块在每台机器上做一个容器,4.0 上由于有了 Dashboard,可以查看慢日志,会方便许多,其他日志需要设置一个容器日志存储的位置。监控上是专门用 2 台服务器来部署。另外发现一个 bug 是 部署了 tiflash 的日志是抓取不上来的。
【稳定】云上错误注入、故障演练如何实践?

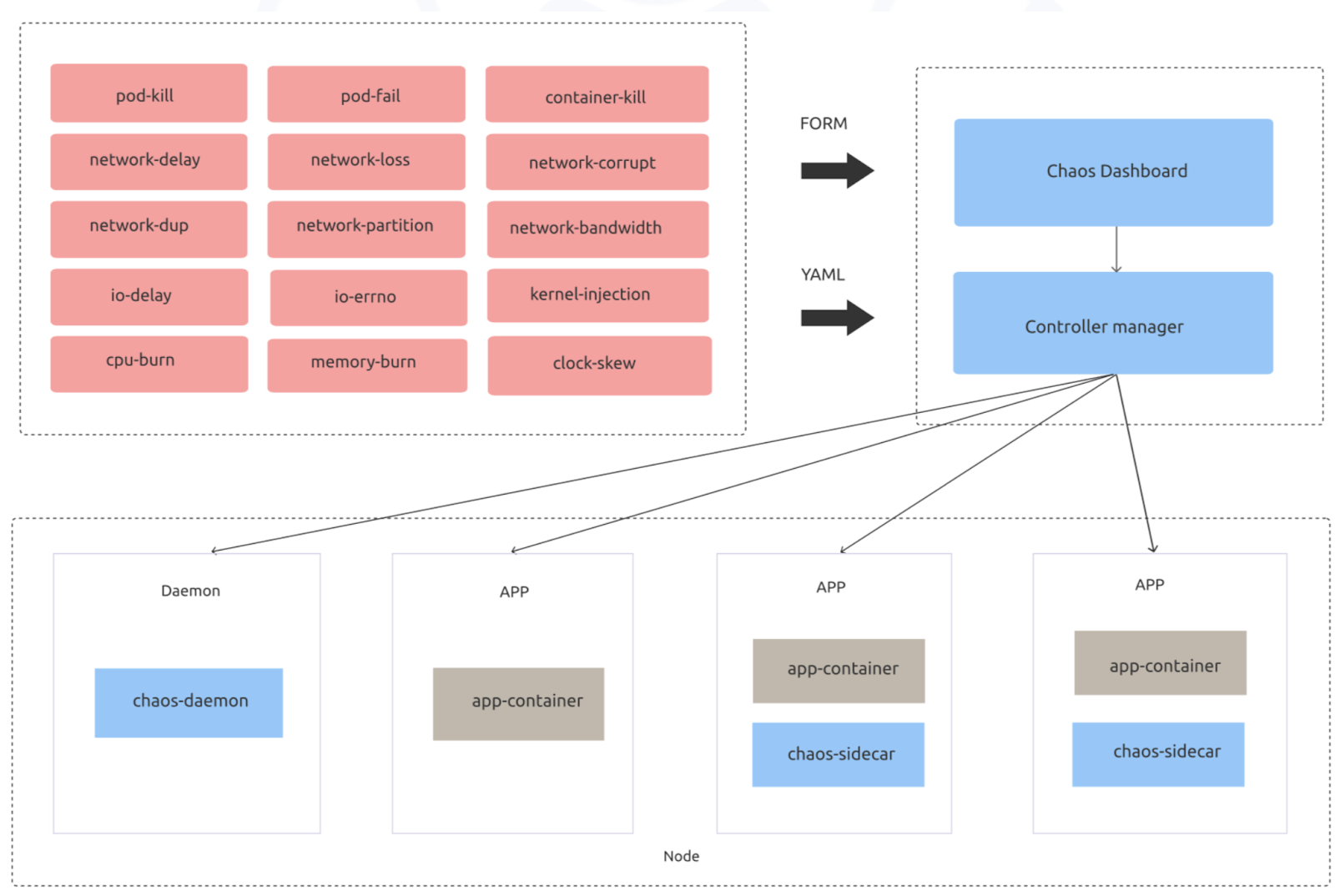
黄潇:还有很重要的一环是故障演练,上云的组件会比本身 TiDB 的组件多很多,美团调研了 chaos monkey、chaos blade、chaos mesh 三种方案,目前打算采用 PingCAP 的开源 chaos mesh,目前在手动使用,将来希望自动测试,反复测试
李银龙:目前也在沟通 chaos mesh 的实践情况,目前还没有大规模使用,当前模拟了同城三中心,以及关闭 TiDB、TiKV 服务器的表现
王云鹤:目前还处于被动故障演练阶段,但雷神系统有自动拉起功能,所以这部分还好,而且可以看出演练后的 TiDB 集群可以自动拉起,也能看到本身高可用还是蛮好,业务没有产生任何影响。TiKV 由于 OOM 故障拉不起来也遇到过,但集群访问是没问题的,挂一台机器业务会报几个错误,对服务基本没有任何影响。K8S 上需要自身对机制特别了解,提前做好储备。
张允禹:知乎倾向用大集群,TiKV 节点会很多,实际上挂掉一台机器影响会非常小,现实情况是,机器挂掉后几乎没什么感觉。
黄潇:大集群 region 数量比较多,甚至上百万的数量,这时 PD 故障会不会影响比较大?
张允禹:重点业务会独立集群,目前还没遇到这种问题
朱博帅:内部正在做 chaos mesh 的整合,结合和 chaos blade 的各自优点。这两者的对比,chaos mesh 做的更细致些,比如内核级别的故障注入,还有 pod 短暂无效的场景,chaos mesh 覆盖的更广一些
黄潇:chaos mesh 还是很香的,官网上推荐的场景都测试了一下,用起来挺不错的,打算后续组合这些场景在线上跑,推荐大家试试看