为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:V4.0.2
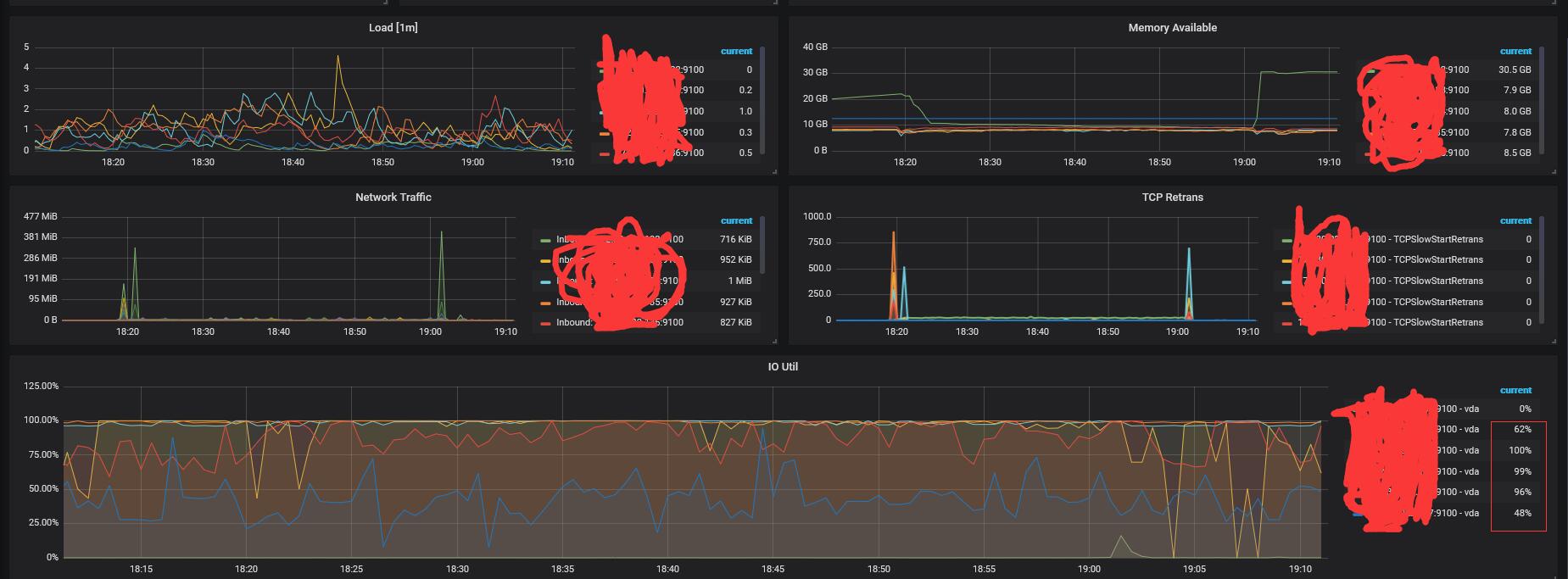
- 【问题描述】:监控IO Util较高,当前集群并无业务请求。
IO监控图,右下角显示IO占用较高,依次为4台TiKV,1台Tiflash。
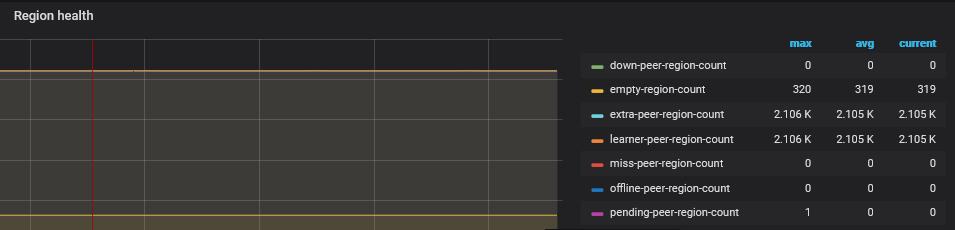
extra-peer-region-count和learner-peer-region-count 持续几天保持在2000多个。
似乎是在上周新增一台Tiflash节点后出现的。
请教一下,如何排查IO的问题。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
IO监控图,右下角显示IO占用较高,依次为4台TiKV,1台Tiflash。
extra-peer-region-count和learner-peer-region-count 持续几天保持在2000多个。
似乎是在上周新增一台Tiflash节点后出现的。
请教一下,如何排查IO的问题。
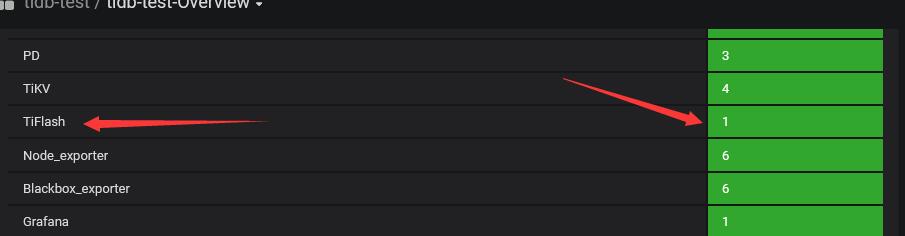
集群拓扑发出来看下,可以看出集群节点分布,pdctl store 看下
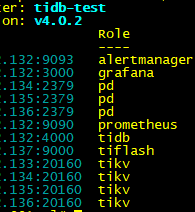
IO高的是所有kv节点(3,4,5,6)
以及Tiflash节点(7)
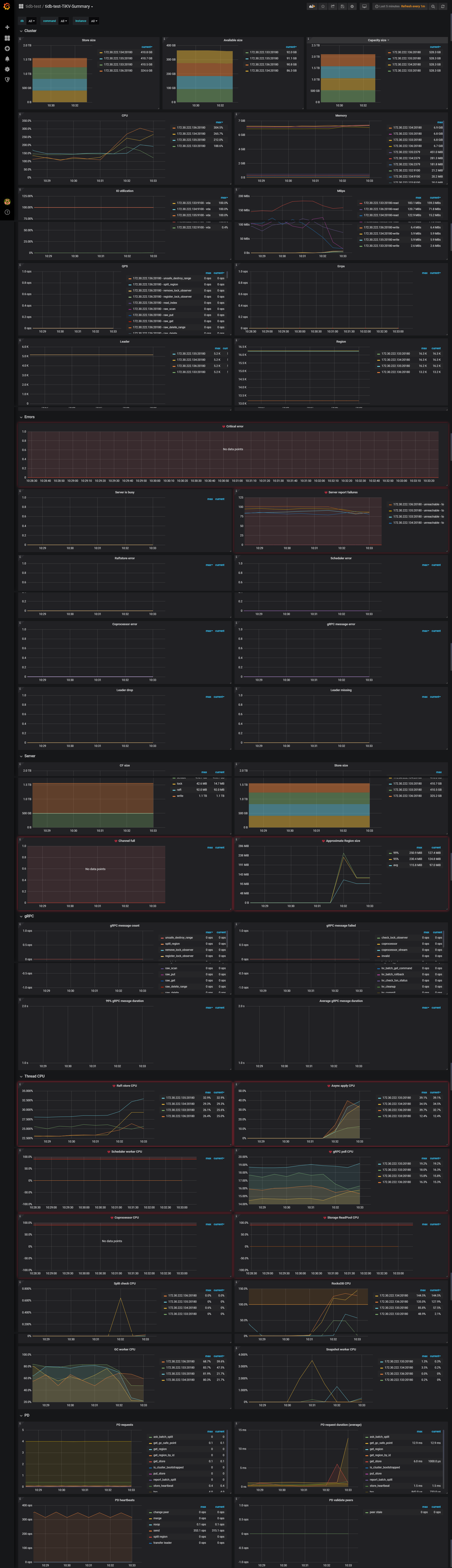
感谢反馈,辛苦上传下 tikv-detail、pd 的完整监控
打开 grafana 监控,先按 d 再按 shift+e 可以打开所有监控项。
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
当前所有4个TiKV节点(一共4个)磁盘使用率都达到了 87%,我怀疑是不是触发了kv的机制在调度region?
所以TiDB和TiFlash都停用的情况下 依旧有大量IO
我重新将TiDB和TiFlash启动,同时移除所有Tiflash上的副本
alter table db-name.table-name set tiflash replica 0;
IO Util TiKV节点依然100%
iotop查看如下
读写主要来自以下TiKV进程:
–status-add~0 --config conf/tikv.toml --log-file /tidb-deploy/tikv-20160/log/tikv.log [rocksdb:low2]
–status-add~0160 --config conf/tikv.toml --log-file /tidb-deploy/tikv-20160/log/tikv.log [gc-worker]
tikv 磁盘使用率超过 80%,建议扩容处理下,否则 pd 调度 region 会比较频繁,造成磁盘 io 比较高,如果非 ssd 可能情况更明显
tiup cluster scale-in <cluster-name> --node 10.0.1.4:9000
pd-ctl store
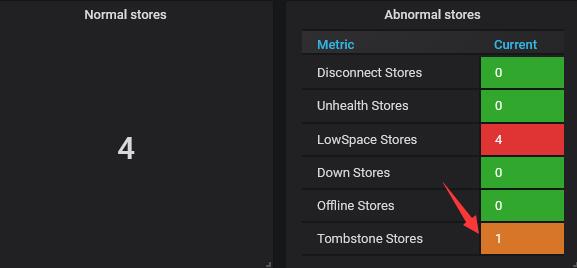
如何删除此已缩容节点?
正常显示,看下 pd-ctl store 应该已经没有 tiflash 节点了,如果需要删除这个,需要对 pd etcd 进行操作可以在 asktug 搜索下。