errnil
(Hacker 8l1k Vr J6)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:V4.0.2
- 【问题描述】:
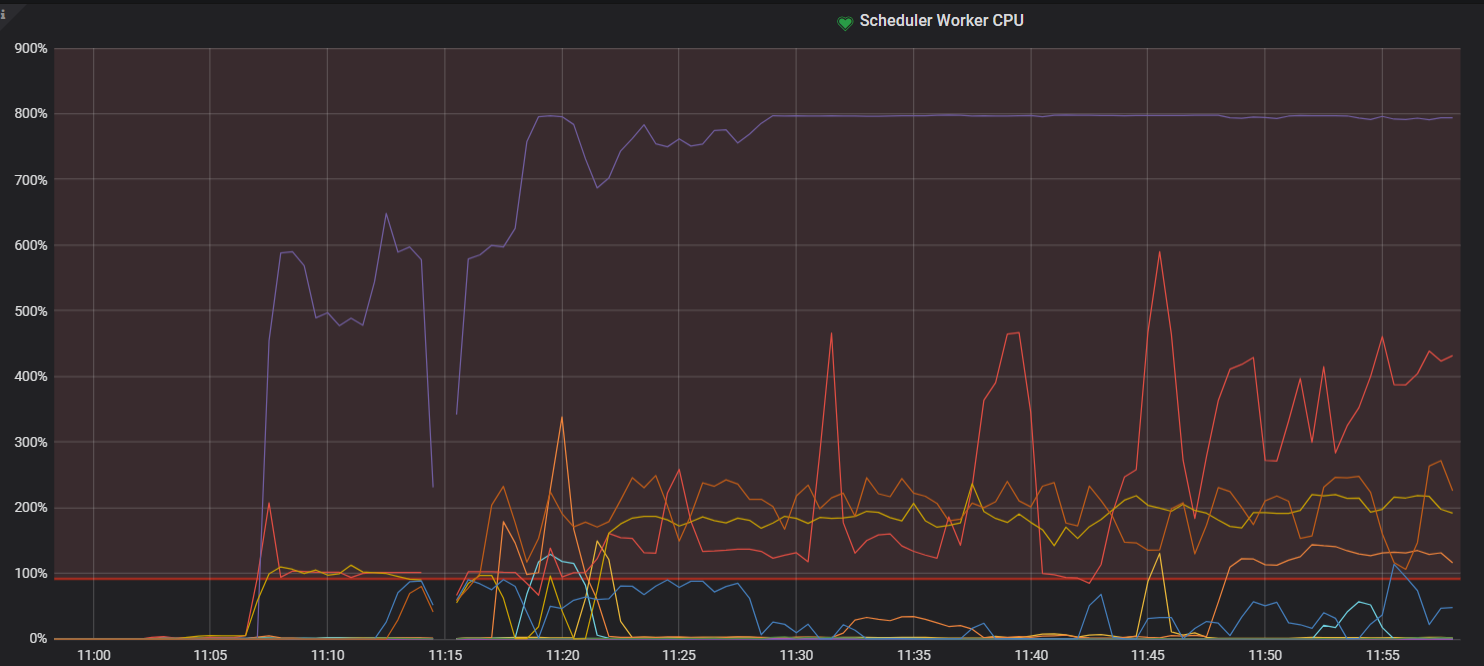
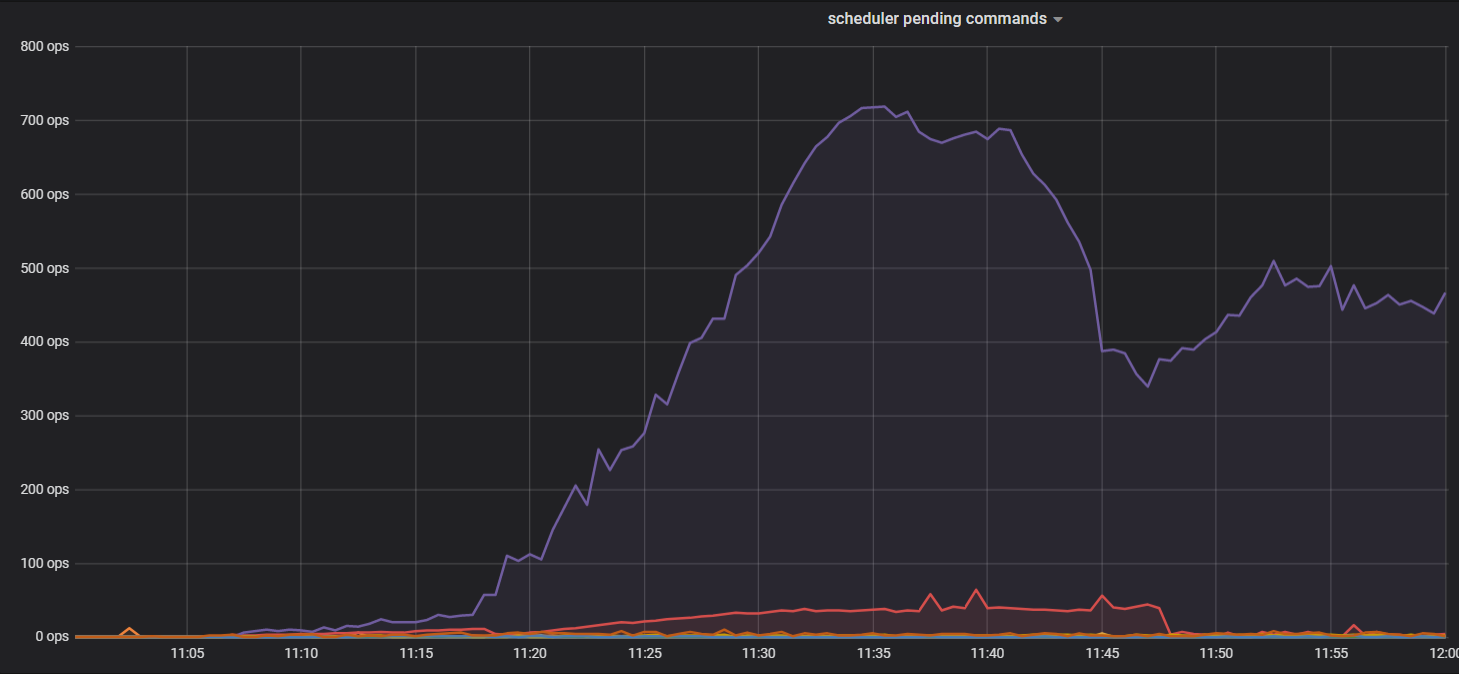
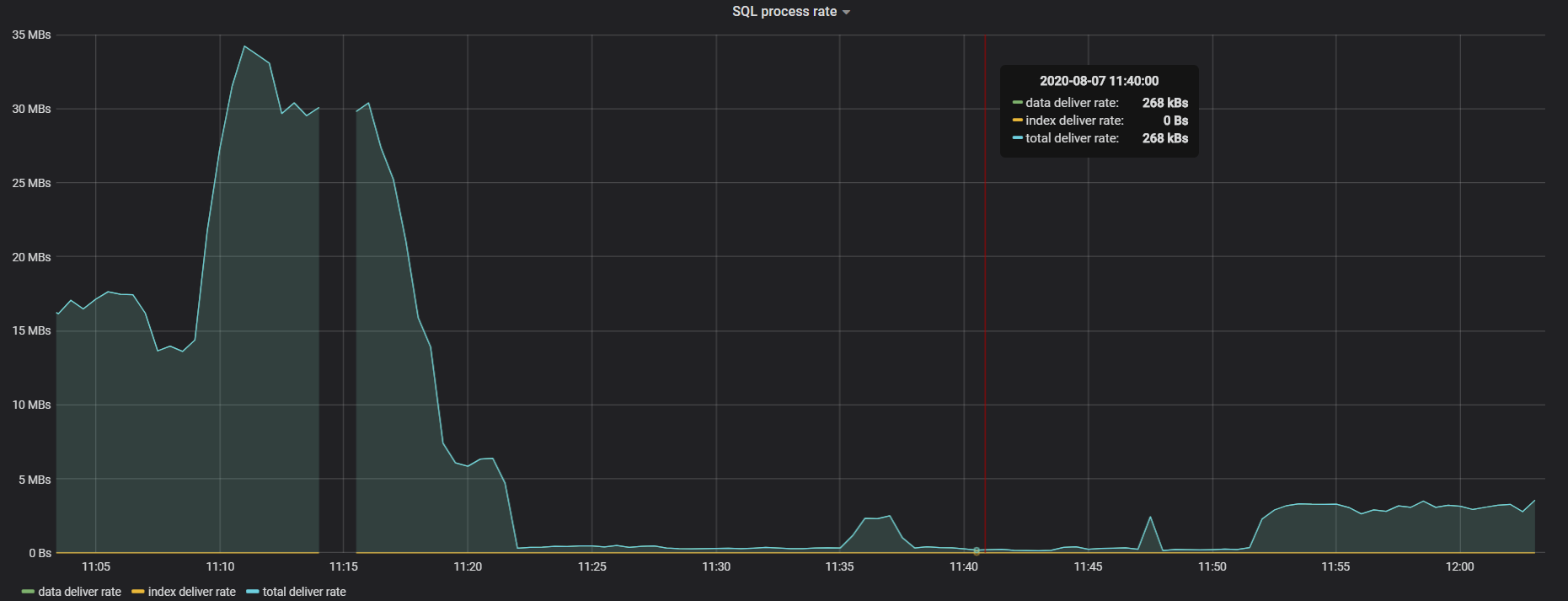
ligthing导入数据, 开始正常,但几分钟后,性能急剧下降,lightning导入速度降到几乎为0。 可以看到某个tikv的CPU很高, storage.scheduler-worker-pool-size: 8, scheduler的CPU为800%, scheduler pending command大幅上升
其它线程CPU看起来正常, 也不高, SSD硬盘, IO也不高。 重启该CPU高的节点后, 会转移到其它节点CPU高。目标表已经有不少数据,lightning导入后端为tidb。
若提问为
性能优化、故障排查类问题,请下载
脚本运行。终端输出打印结果,请
务必全选并复制粘贴上传。
yilong
(yi888long)
2
- 请问使用的是 backend 模式导入吗?
- 麻烦反馈下 over-view pd detail-tikv 的监控
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
errnil
(Hacker 8l1k Vr J6)
3
1 是的, backend的模式导入, 配置如下:
[tikv-importer]
backend = “tidb”
on-duplicate = “replace”
2 tikv detail太多指标了, 页面没响应了,试了多次也不行。我截屏了tikv trouble
原始PDF太大了, 上传不了, 我压缩了再上传
over_view_s_compressed.pdf (495.3 KB) pd_s_compressed.pdf (815.5 KB) tikv_trouble_s_compressed.pdf (892.8 KB)
errnil
(Hacker 8l1k Vr J6)
5
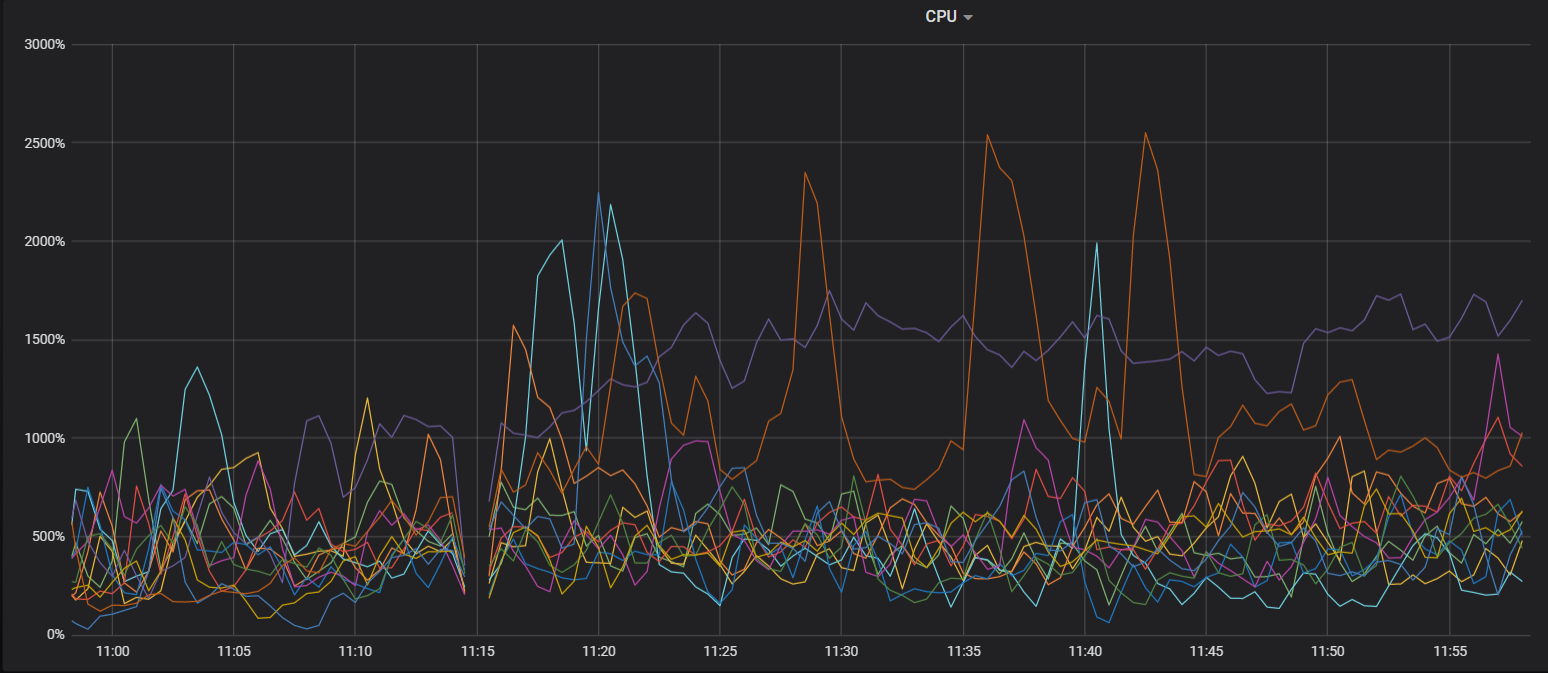
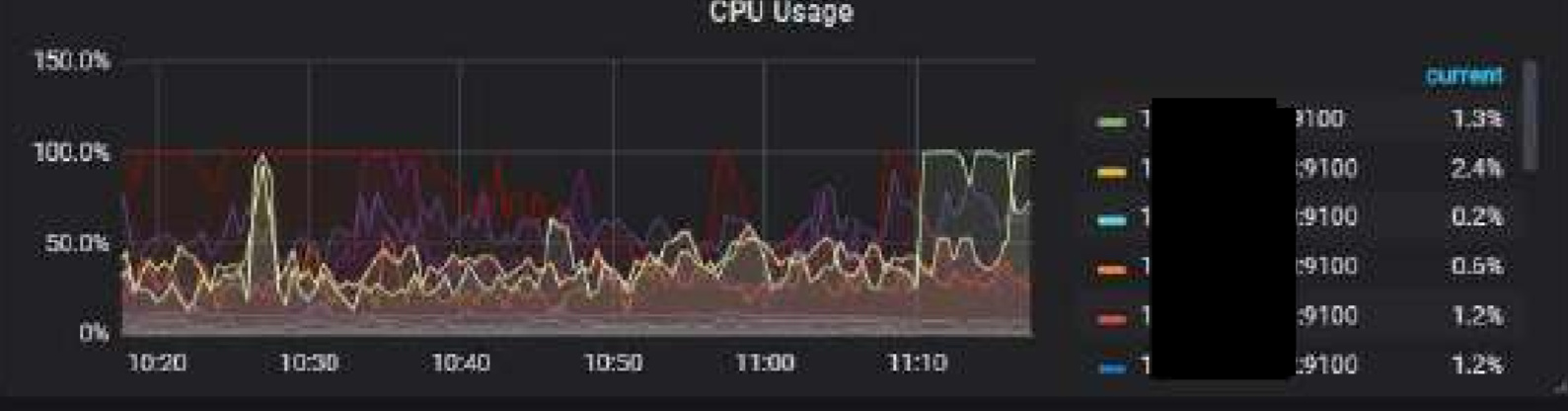
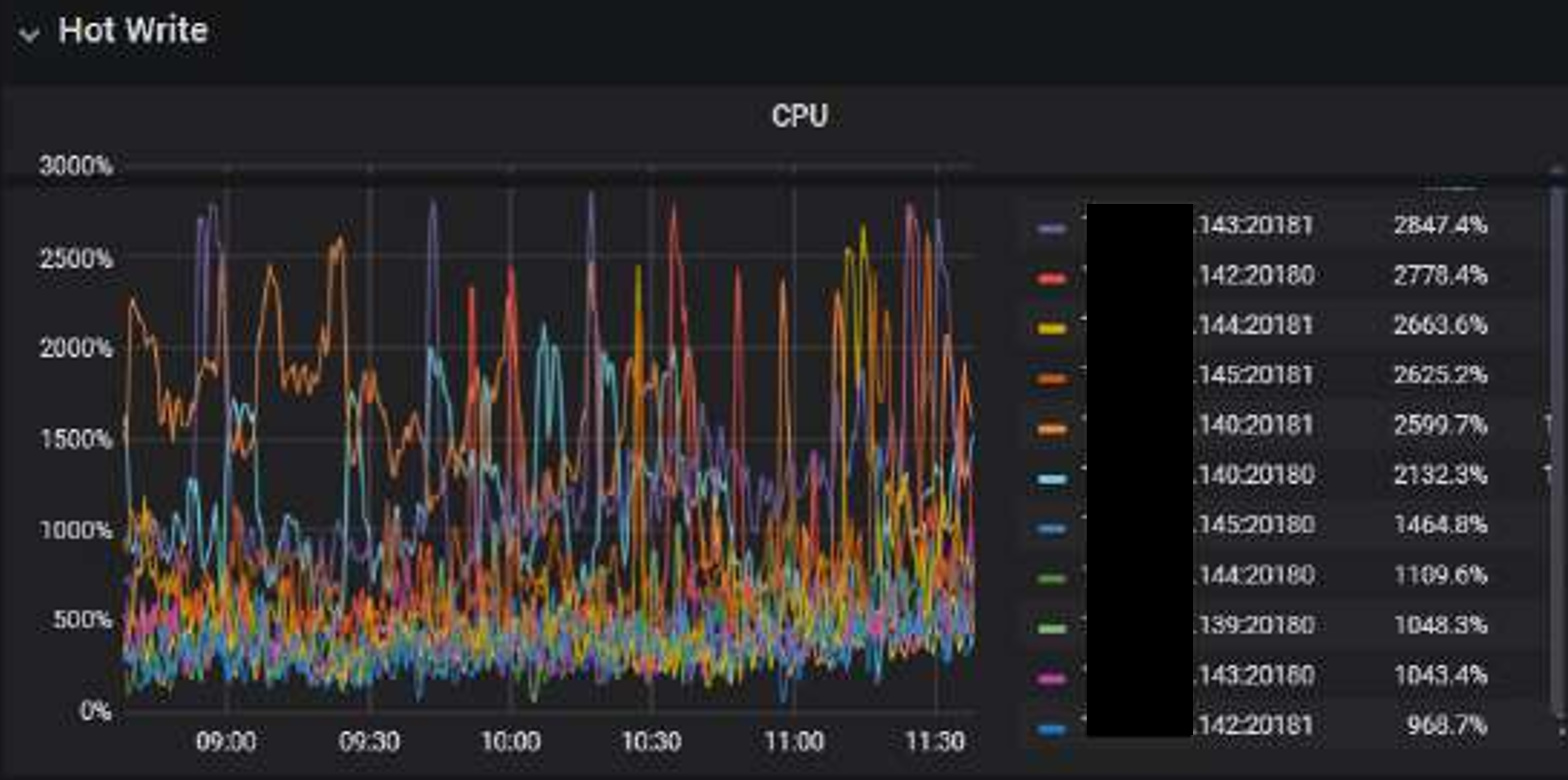
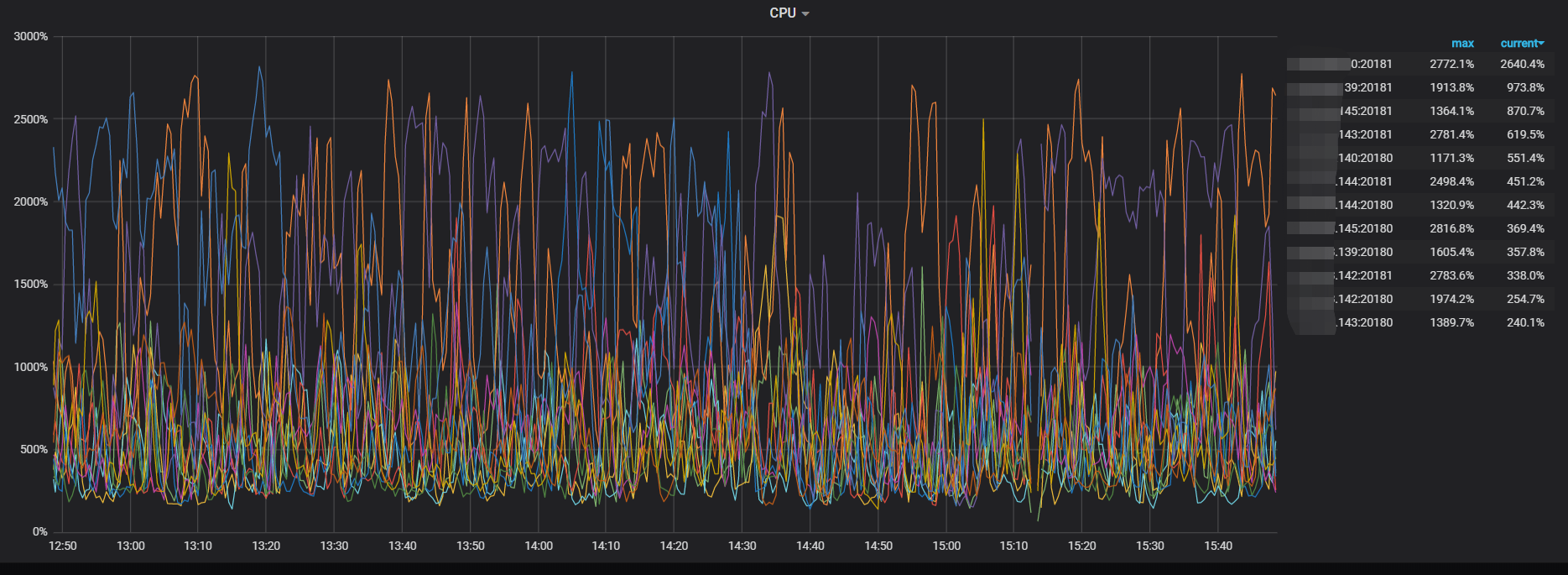
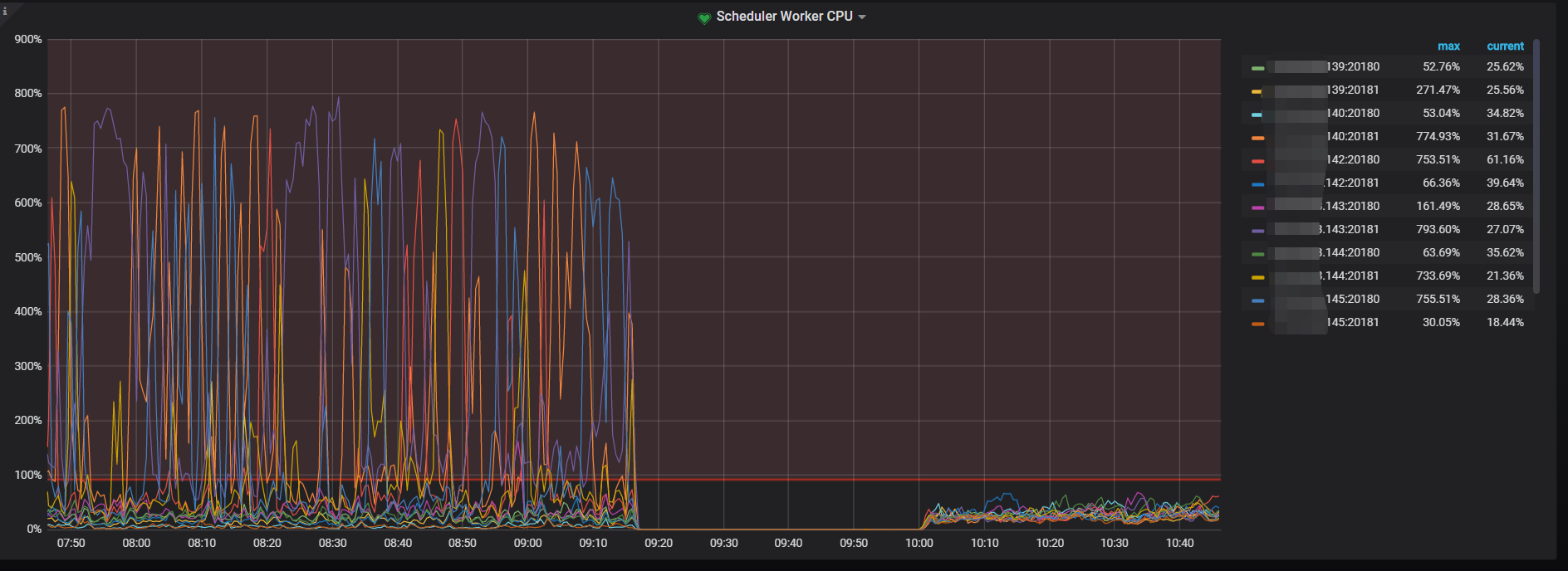
1 CPU都很高, 热点节点不停转移。但实际这个时候没什么数据在写入了, 因为都写不进去了, 然而CPU一直持续这么高
2 我把lighting停了, 把scheduler线程CPU满的tikv节点重启了, 写入就正常了, scheduler的CPU没满了。 目前这个tidb集群,没有查询, 还处于导入数据阶段, 目前是通过DM在导入数据。因为从多个数据库导入相关的表,有部分重复的数据, DM导入全量数据不支持insert改为insert ignore或者replace, 因此lightning与DM一块使用
3 给表加索引时,也出现两样的现象, scheduler线程CPU满, 基本没法写入
4 把lighting停了, 把加索引的DDL过滤后, DM数据导入正常, 虽然CPU也很高, 但scheduler CPU不会满, 插入的QPS为2000左右, 而异常时insert基本只有个位数QPS
5 tiflash开户了, 但目前没有设置表的同步为tiflash
6 只要把scheduler线程CPU满的节点重启了, 写入会正常一会,然后某个节点的scheduler线程CPU会打满,然后基本就处于整个集群CPU持续高, 数据基本写不入的情况了
errnil
(Hacker 8l1k Vr J6)
7
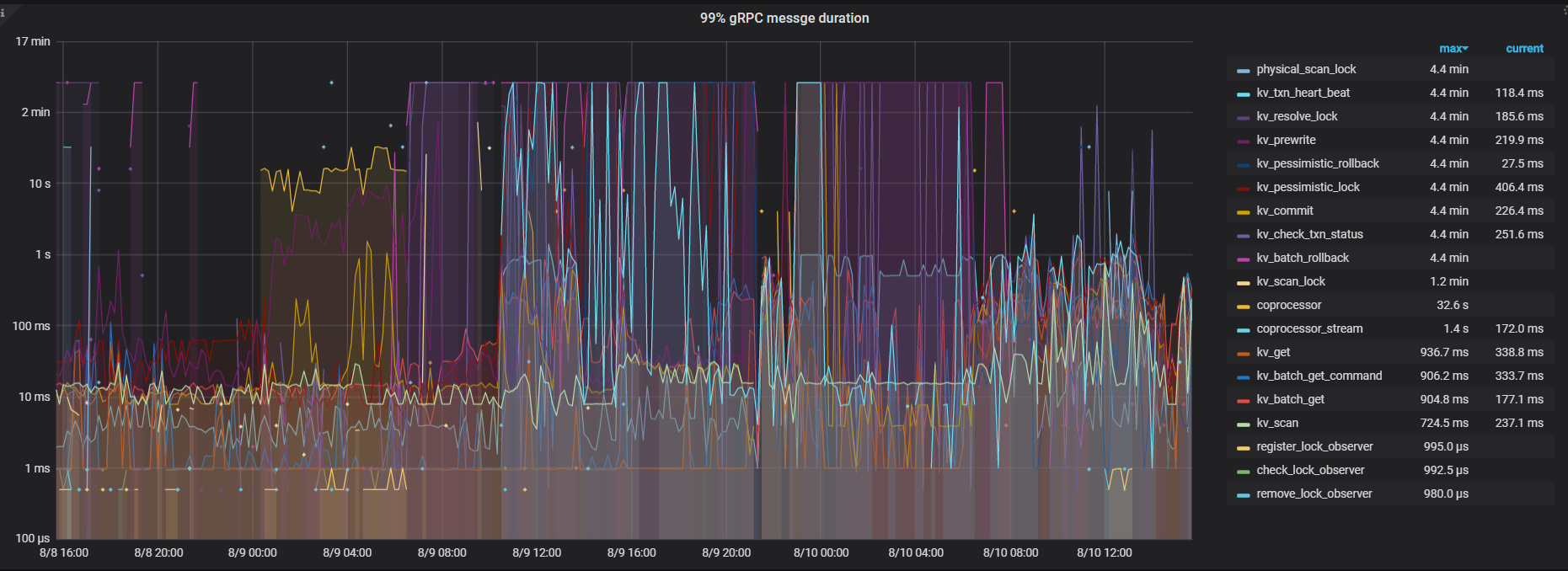
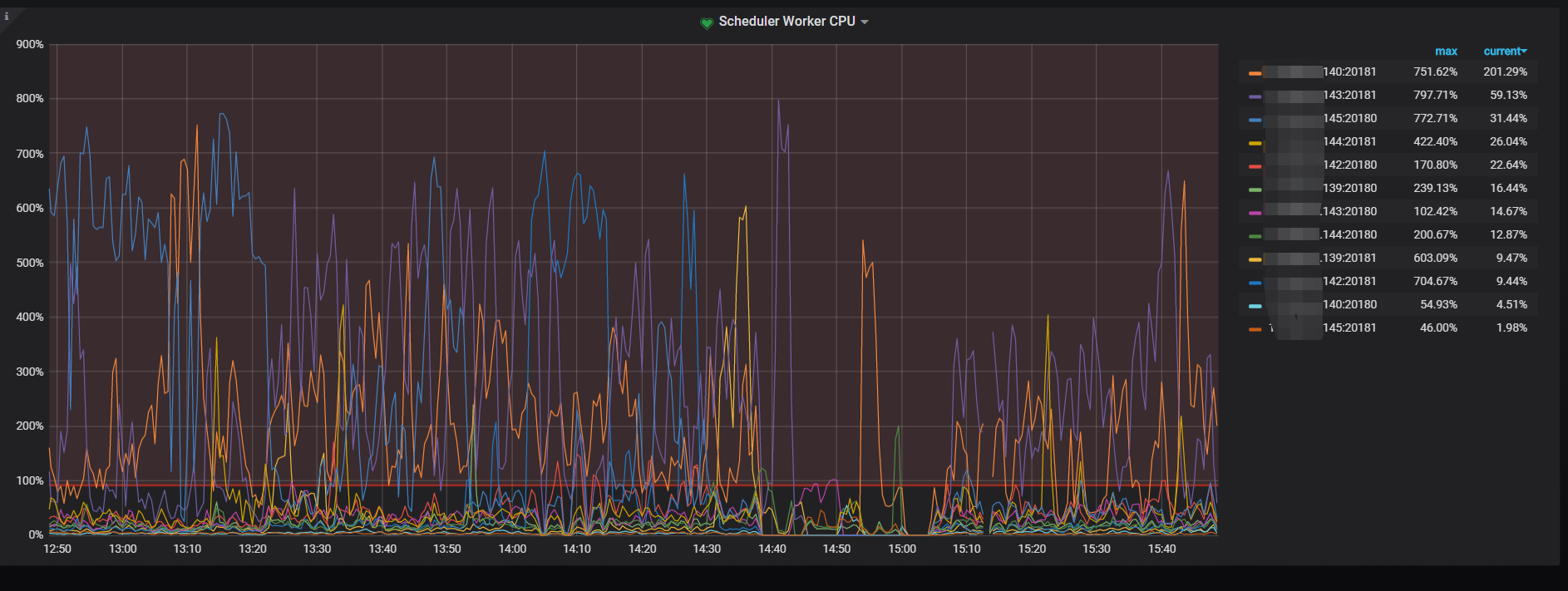
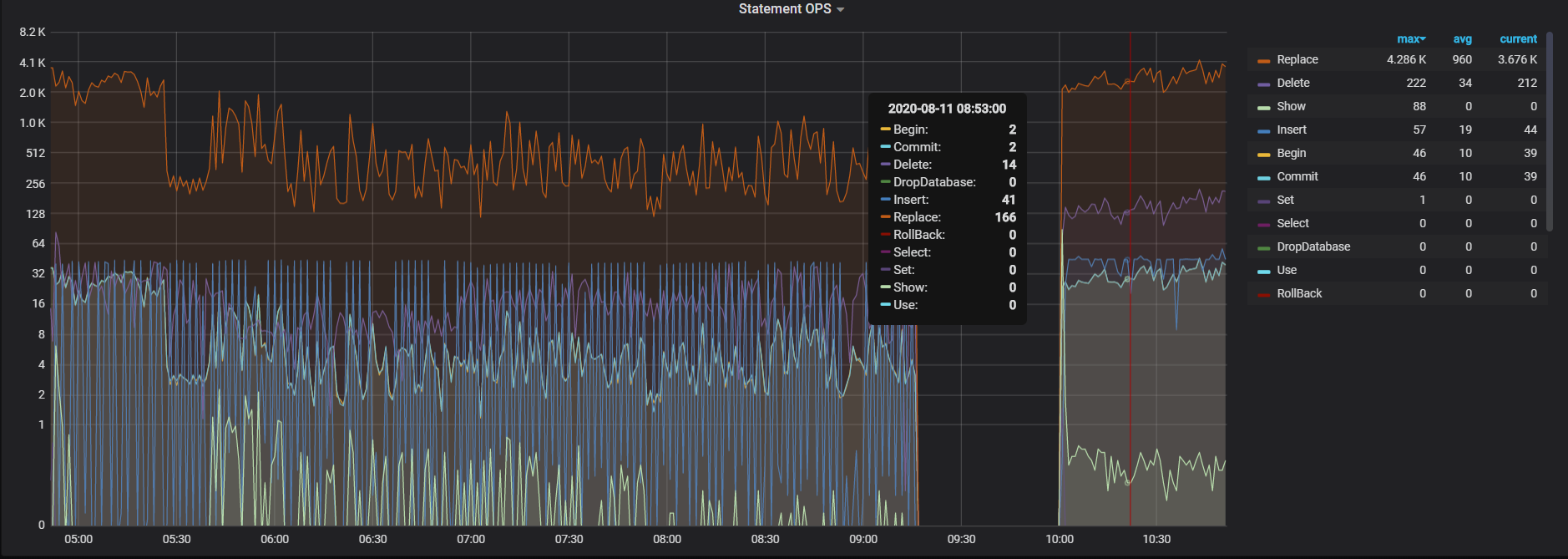
1 是prewrite很慢。scheduler-worker-pool-size我调到8, scheduler线程CPU就去到800%,调到16,scheduler线程CPU就去到1600%。 实际上这个时候,已经基本写不入了,但是我没关闭lightning,让它持续这样跑了24小时, 这24小时都基本这样, 基本没法写入,CPU又一直这么高
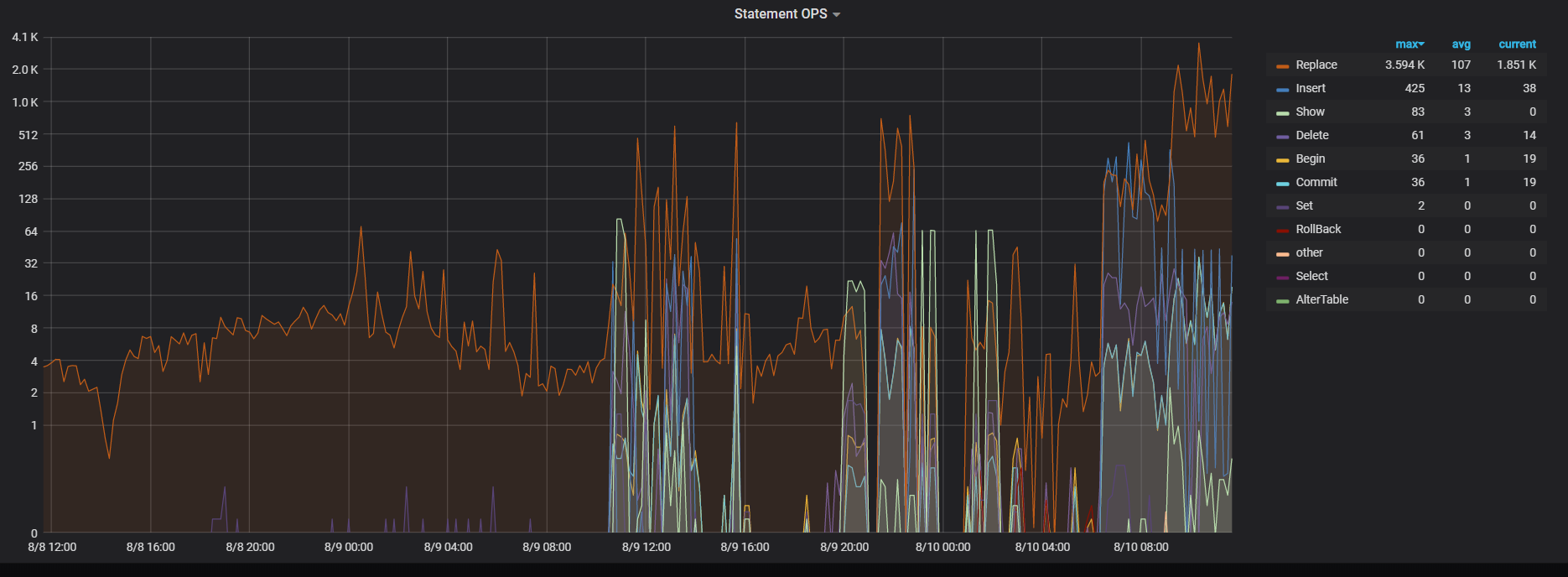
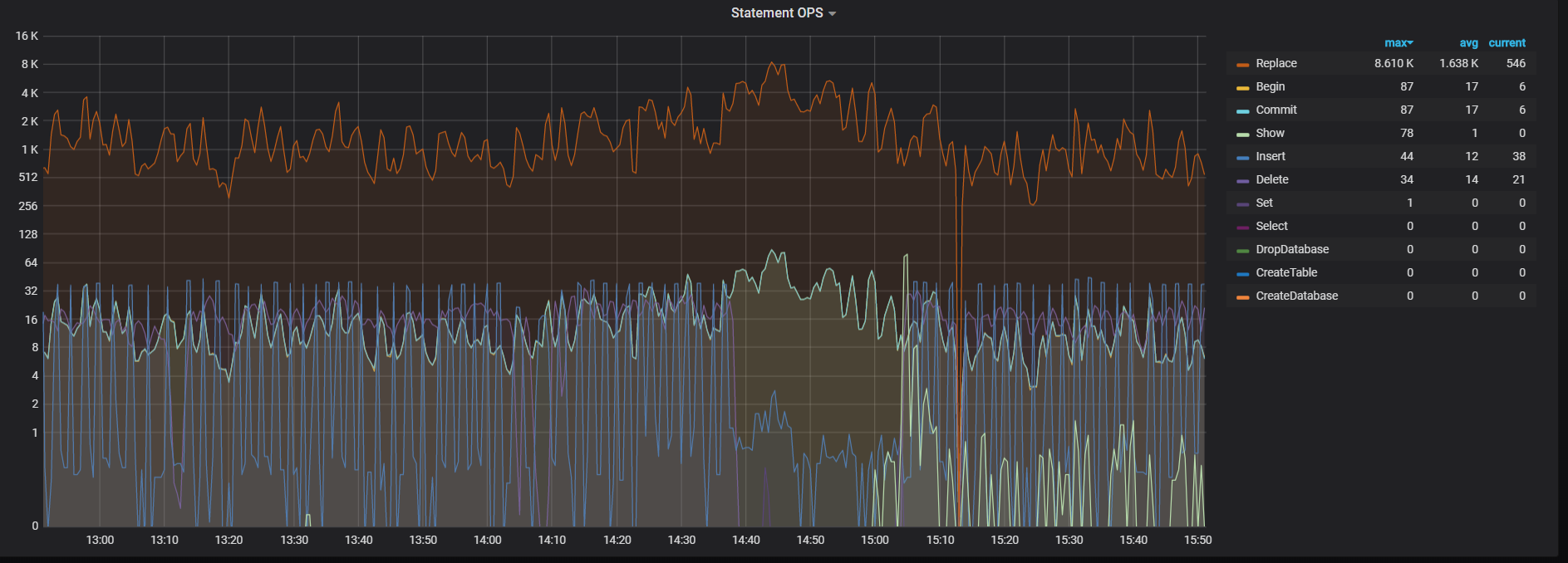
2 停止导入lightning导入后, CPU也高, 但没这么高, 能正常能过DM导入数据,也没有出现scheduler cpu一直很高的现象。 下面是现在关闭了ligtning只有DM在同步数据的CPU情况, 可以看到CPU依然很高, 但scheduler cpu没有满, statement ops看到数据正在导入, 没有出现statement ops只有个位数而CPU就极高的现象
yilong
(yi888long)
8
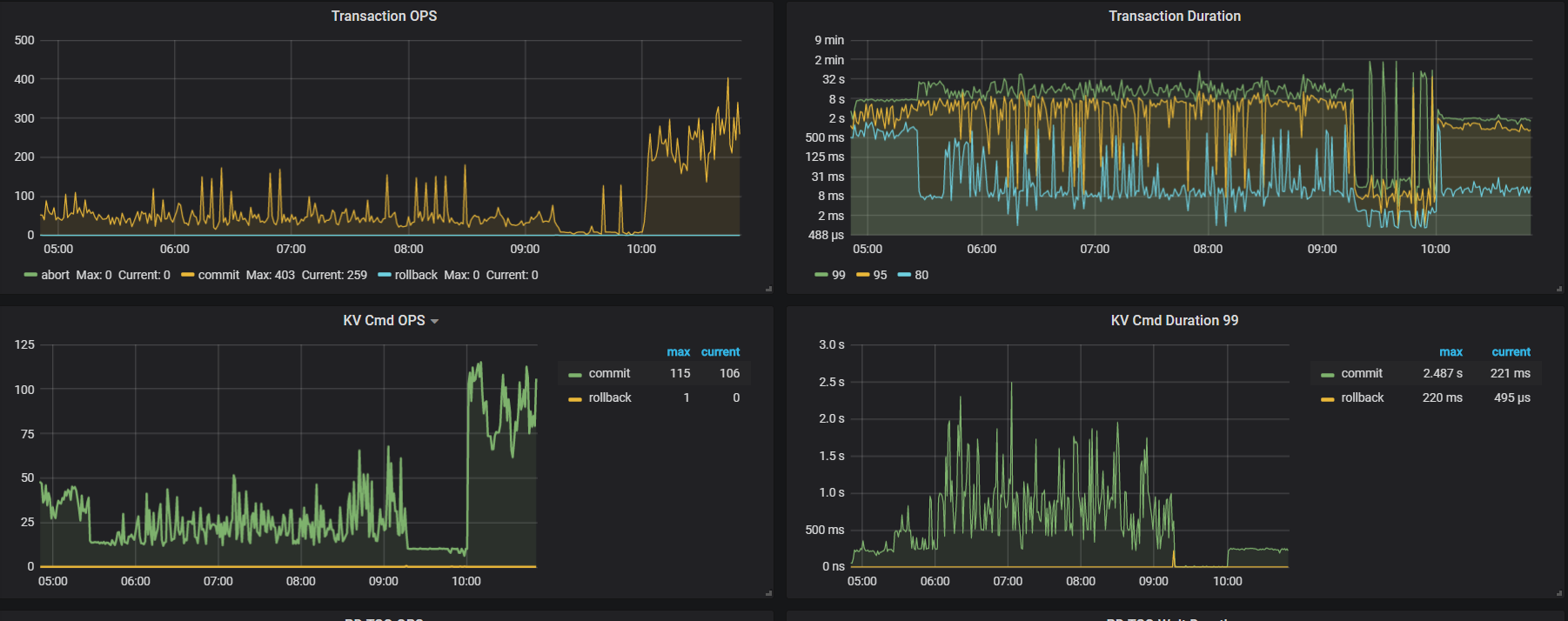
麻烦发一下 CPU 高的时候 rocksdb - kv 的 metrics,多谢。
errnil
(Hacker 8l1k Vr J6)
9
errnil
(Hacker 8l1k Vr J6)
10
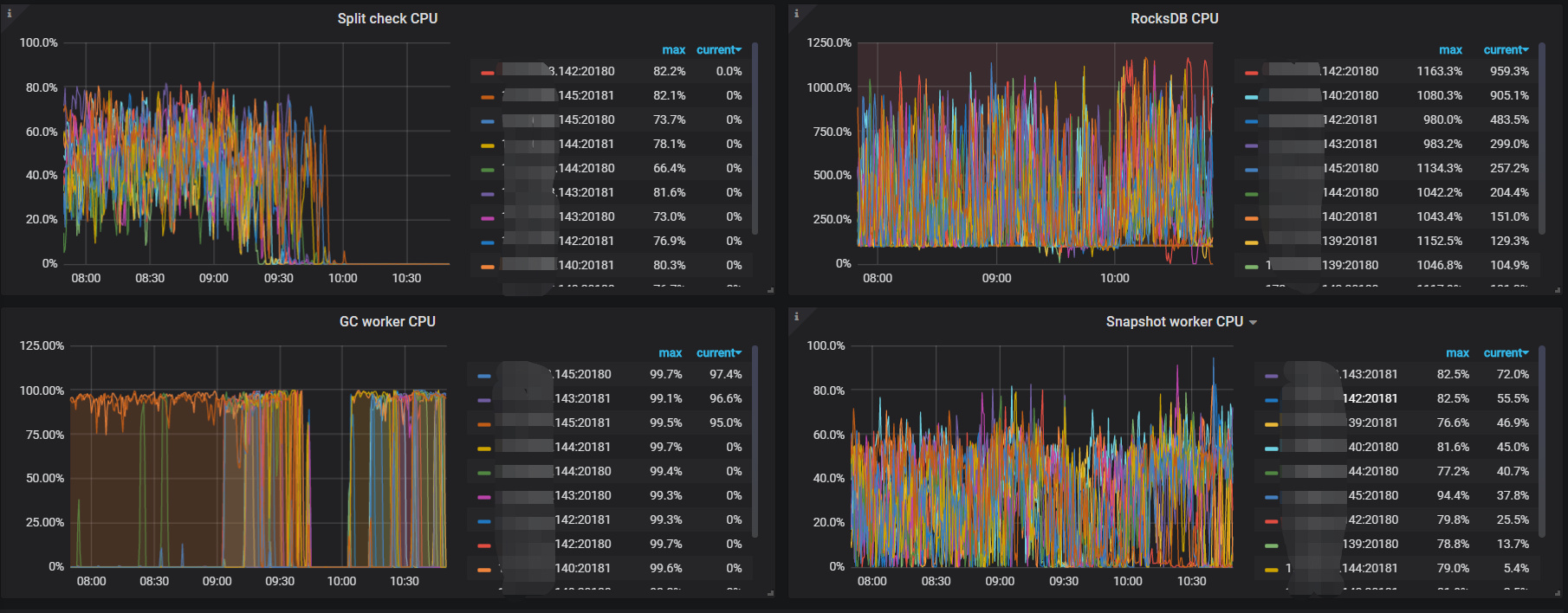
看来可能是region的分裂太频繁了导致。我下面的设置提高了差不多10倍, 原来是700万key, 300多MB:
coprocessor.region-max-size: “10GB”
coprocessor.region-split-size: “6GB”
coprocessor.region-max-keys: 50000000
coprocessor.region-split-keys: 30000000
merge region的设置相应提高到下面的值
schedule.max-merge-region-size: 5000
schedule.max-merge-region-keys: 30000000
然后重启tikv与pd, dm的写入快了几倍, scheduler的CPU下降了几倍,tikv整体的CPU也下降了不少, 而split check 的CPU几乎降到了0。 就是不知道会不会数据持续写入后, 达到region分裂的大小后,又会出现CPU好高,写入停滞的情况。也没有找到split check的线程数设置参数
yilong
(yi888long)
11
请问您方便把参数改回去试试吗? 感觉应该是重启恢复的。
errnil
(Hacker 8l1k Vr J6)
12
tikv我重启过多次了, 没有起作用,只是重启完成几分钟内能正常写入, 很快就CPU打满,基本写不入了。
pd我倒是第一次重启
yilong
(yi888long)
13
是的,所以不知道是否方便,修改回原来的参数验证下,理论上感觉不是参数的问题,多谢。