peng-xin
(Peng Xin)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.4
- 【问题描述】:下线tiflash节点之后,残留大量extra-peer,在进行reload操作时,会出现error evicting store leader from 172.16.116.153:20171, operation timed out after 5m0s的错误。
有下面两个小疑问,想让老师帮忙看看
1.如何批量删除异常peer?
2.如何调整驱逐store leader的operation超时时间?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
peng-xin
(Peng Xin)
3
老师您好,详细信息在下面
config.txt (5.1 KB)
store.txt (3.2 KB)
peng-xin
(Peng Xin)
4
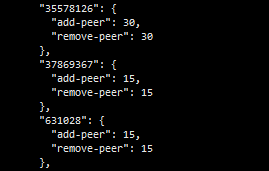
上面这三个都是tiflash的storeId,最开始的是631028这个id;手动下线之后,由于没有停止tiflash服务,导致它重新产生新的tiflash的store;后来在停了tiflash服务,并删除相应数据文件之后,由于没有删除/etc/systemd/system下的tiflash的service文件,导致服务重启,产生新的tiflash的store。
yilong
(yi888long)
5
好的,能否反馈下 config show all 的信息呢,多谢。
peng-xin
(Peng Xin)
6
 老师您好,上面的图片编辑了,config文件就是config show all的内容
老师您好,上面的图片编辑了,config文件就是config show all的内容
peng-xin
(Peng Xin)
8
yilong
(yi888long)
9
您好,和另一个帖子一样,先检查下placement rules,多谢
peng-xin
(Peng Xin)
10
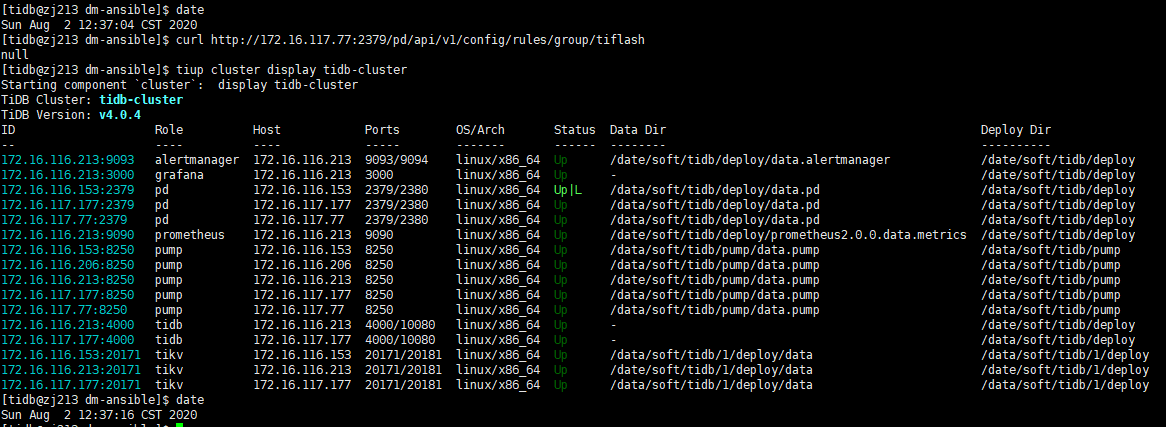
placement rules之前已经通过下述命令清理完毕了
curl http://<pd_ip>:<pd_port>/pd/api/v1/config/rules/group/tiflash
curl -v -X DELETE http://<pd_ip>:<pd_port>/pd/api/v1/config/rule/tiflash/table-45-r
peng-xin
(Peng Xin)
11
extra-peer的问题,通过调整store limit和间段执行(原因是scheduler会暂停)tiup cluster reload
extra-peer已经下线完毕。
但是tikv滚动重启时,驱逐leader超时的问题还没有解决
system
(system)
关闭
13
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。