TiDB-DM: v1.0.3
TiDB-Server v3.0.9
描述:
最近发现的错误
也许是因为 上游数据库是阿里云的RDS,之前升配的时候出现30秒左右的闪断导致的,应该怎么恢复呢?

请先检查下上游 MySQL 是否有超过 4GB 的 binlog 文件,如果有,请参照下面的方式处理下:

以及下述 FAQ:
binlog全都是500MB,阿里固定的
请再次确认下上游的 MySQL binlog 的大小,如果方便请提供截图。在遇到大事务时,binlog size 会突破 max_binlog_size 的限制~
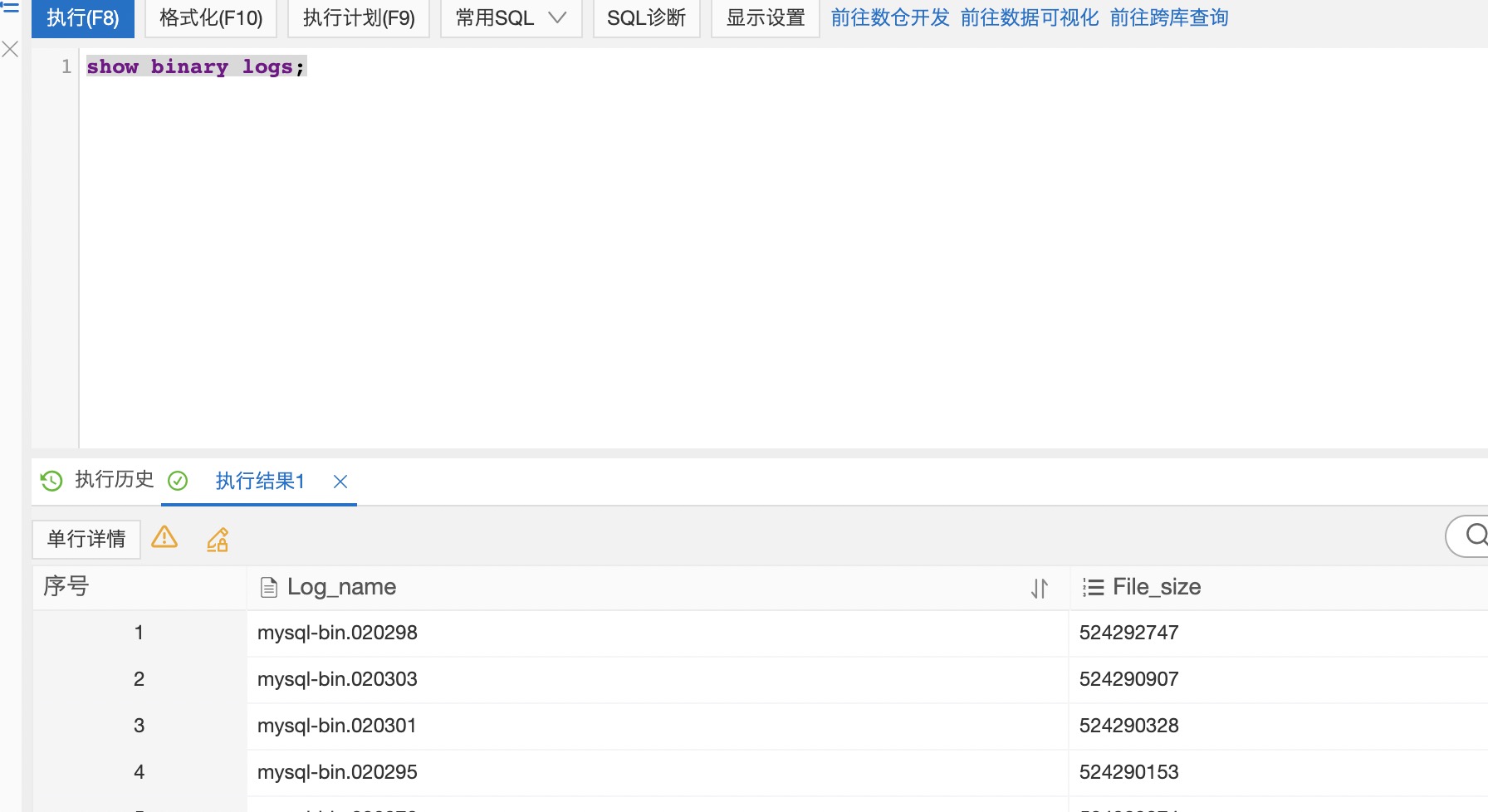
好的,上游 MySQL 在升级配置时,是 master 和 slave 依次滚动升级,并且在升级过程中,master 是否出现了主从切换? DM 同步的是否是 master 的数据?
在出现问题后,有重启过 dm-worker 吗?请提供下 welcome 开始的 日志吧,谢谢~~
上游同步的都是master,没有滚动,就是断链了,问题出现后没有重启过dm-worker,但是执行过stop-task和start-task
welcome 日志是哪个…
-
DM 上游同步的是 mysql master ,在升级配置的时候,master 有出现过主从切换吗?
-
请尝试重启下 dm-worker ,并且将 dm-worker 新输出的日志信息从 welcome 开始提供下。
-
请上传看下 dm relay log meta 文件的内容,目录信息如下:

没有主从切换,就是闪断一下,其他信息稍等我提供一下
dm-worker.log (10.1 KB)
我重启 dm-worker后这是从 Welcome to dm-worker开始的日志
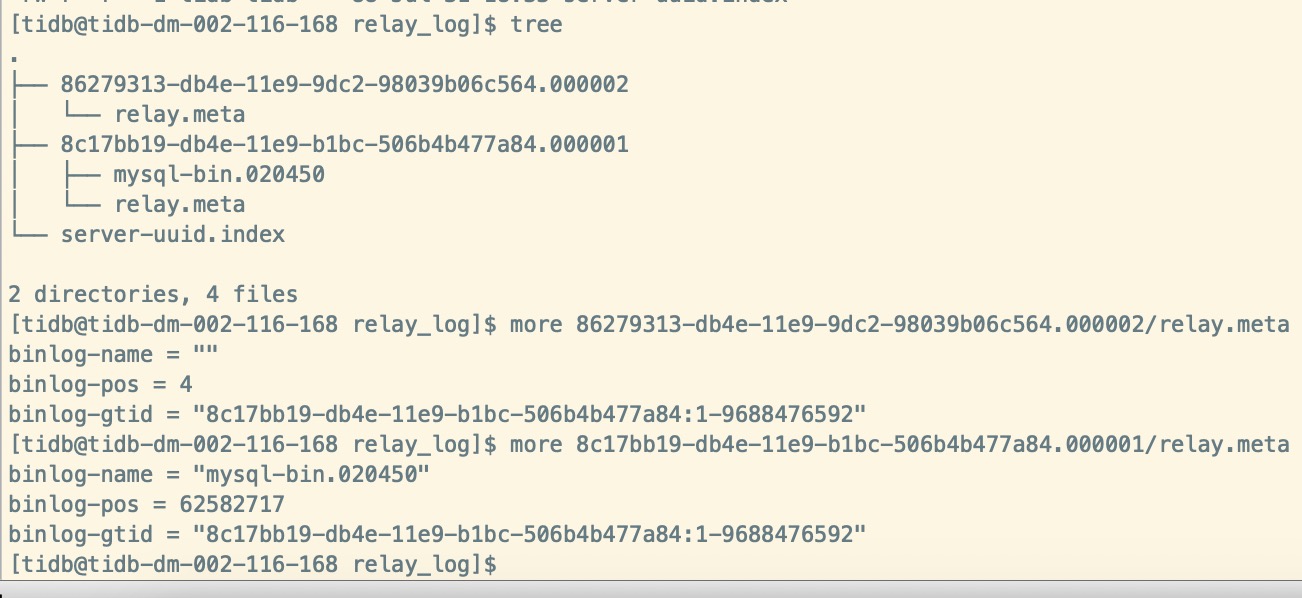
重启的dm-worker1 对应的 source_id 是product08_merge
- 从当前的信息看,在升级配置时,启停 master 时,RDS 会自动进行主从切换,dm-worker 的日志也可以验证这一点:
[2020/07/31 18:36:22.093 +08:00] [ERROR] [relay.go:391] ["the requested binlog files have purged in the master server or the master server have switched, currently DM do no support to handle this error"] [component="relay log"] ["db host"=rm-2zer120i0zogo7pl9.mysql.rds.aliyuncs.com] ["db port"=3306] [error="[code=30015:class=relay-unit:scope=upstream:level=high] TCPReader get relay event with error: ERROR 1236 (HY000): The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires."]
- 建议参考下面的文档来尝试解决这个问题:
好的 我试试
如果还是有问题,请继续跟贴 ![]() ~~~
~~~
我们是高可用版(一主一备),宕机时会进行主备切换, 我们一共八个实例,一开始降一台,没有问题,一天后降四台也没有问题,,再过一天降最后几台时候出的问题,这是什么原因
hi,开新帖将信息整理下发出来我们跟进下吧。