lmy012
(Lmy012)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:V4.0
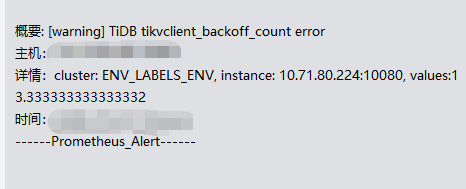
- 【问题描述】: TiDB tikvclient_backoff_count error 频繁告警,想确认下这个告警的原因是什么?
告警内容:
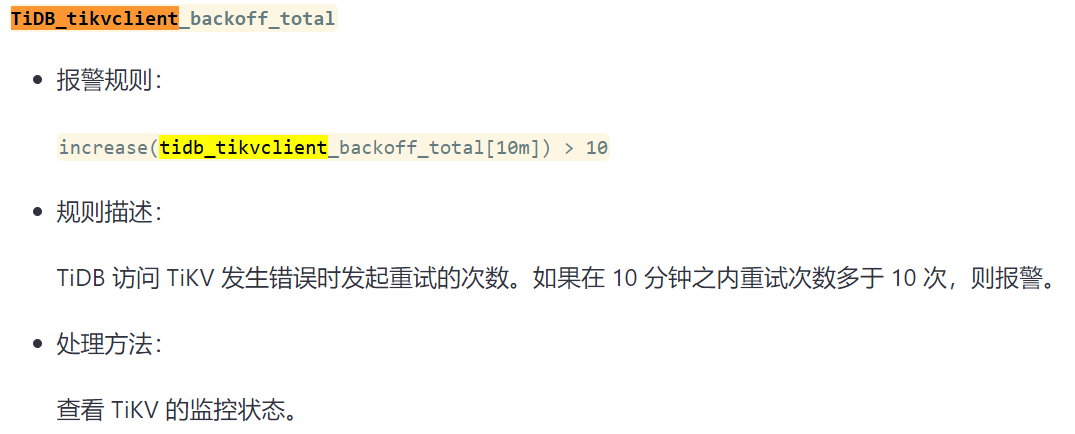
告警规则:
- alert: tidb_tikvclient_backoff_seconds_count
expr: increase( tidb_tikvclient_backoff_seconds_count[10m] ) > 10
监控图:
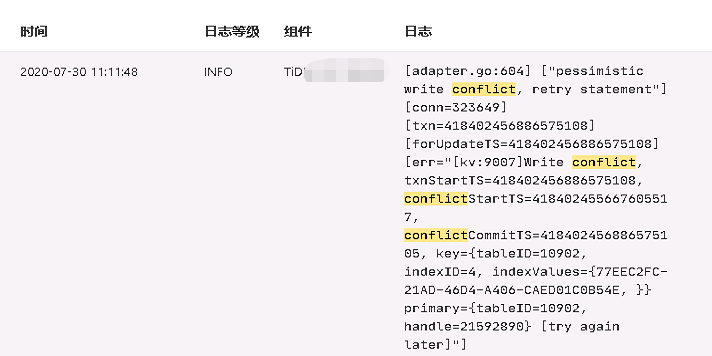
tidb.log中存在conflict关键字。
yilong
(yi888long)
2
1, 监控 KV Backoff OPS:TiKV 返回错误信息的数量
2.
3. 看到您的日志中,有 kv 的报错 pessimistic write confilct.
4. 请问当前业务有什么影响吗? 可以检查下 tikv.log 在这个时间是否还有其他报错。 如果只有pessimistic write conflict,可以看下业务上是否存在很多同时更新同一行记录的类似情况。
1 个赞
lmy012
(Lmy012)
3
业务影响暂时还不确定,但这个告警是一天到晚都存在,就没有停过,怕有风险。
yilong
(yi888long)
4
检查下tikv日志,如果只是写冲突,没有太大风险,有可能影响的就是后写入的要等待一段时间
lmy012
(Lmy012)
5
刚全节点查了今天整天的日志,查找ERROR的话只有以下3类告警日志(今天ERROR日志总量可能就一两百条),感觉也没有啥问题。是否可以考虑在告警规则的阈值改大一点?
[2020/07/30 10:22:35.777 +08:00] [Error] [store.rs:424] [“handle raft message failed”] [err=“Other(”[components/raftstore/src/store/fsm/store.rs:1282]: [region 5186409] region not exist but not tombstone: region { id: 5186409 start_key: 748000000000002EFF1B5F728000000002FF386AAE0000000000FA end_key: 748000000000002EFF1B5F728000000002FF3A65FA0000000000FA region_epoch { conf_ver: 3900 version: 7017 } peers { id: 5186410 store_id: 7 } peers { id: 5186411 store_id: 10 } peers { id: 5186412 store_id: 1 } peers { id: 5186413 store_id: 74 is_learner: true } }")"] [store_id=7]
[2020/07/30 10:54:42.283 +08:00] [Error] [deadlock.rs:675] [“leader client failed”] [err=“Grpc(RpcFinished(Some(RpcStatus { status: 1-CANCELLED, details: Some(“Cancelled”) })))”]
[2020/07/30 11:45:50.156 +08:00] [Error] [gc_manager.rs:533] [“failed gc”] [err=“Engine(Request(message: “stale command”))”] [end_key=748000000000002DFF205F698000000000FF0000020130346664FF62336239FF333464FF3034653736FF3836FF633165663530FF32FF33386464616138FFFF0000000000000000FFF700000000000000F8] [region_epoch=“Some(conf_ver: 4202 version: 6122)”] [region_id=4936076]
qizheng
(qizheng)
6
结合监控看,backoff 类型主要有 regionMiss,staleCommand 和 updateLeader 三类,通常是由于 region 或 leader 调度引起的重试,告警阈值时 10 分钟超过 10 次,频率不算高,可以适当调大阈值。
另外建议检查下告警时间段的监控和业务行为,比如是否有业务导数,集中写入的行为,wirte conflict 只是现象,说明这段时间可能存在较高并发的写入或更新。
我这边也报了很多类似的告警。查看tikv日志有很多Locked,通过tidb的dash去查看有的insert耗时达到了3s。tikv日志详细信息如下
[WARN] [endpoint.rs:527] [error-response] [err=“Key is locked (will clean up) primary_lock: 74800000000000024D5F6980000000000000020391DA3DD465CD2000040000000000000000040000000000000000040000000000000001017531323338313038FF3630363231323332FF3934373200000000FB0380000000042D012A lock_version: 418428798708482050 key: 74800000000000024D5F6980000000000000020391DA3DD465CD2000040000000000000000040000000000000000040000000000000002017531323338313038FF3630363231323332FF3934373200000000FB0380000000042D012A lock_ttl: 3001 txn_size: 2”]
lmy012
(Lmy012)
8
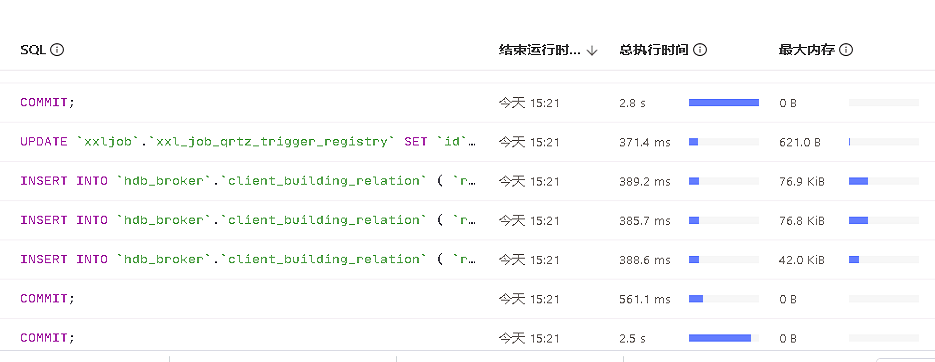
今天,我把阈值改成100,现在看到的告警内容,这个error重试次数已经达到了155次,查看tidb面板的慢sql,也能看到有一些insert的情况,这些insert都是dm集群在同步上游的语句,同时查看这个时间点的binlog日志也才2个,所以猜想写入的量应该也不大。
问题:
1、这个监控的重试次数是如何统计的?
2、是否还能通过其他手段去确认这个告警的原因?毕竟告警的阈值不能无限调大。(critical的阈值是6000)
expr: increase( tidb_tikvclient_backoff_seconds_count[10m] ) > 100
告警内容:
监控图
慢sql查询
DM集群在这个时间点附近的binlog日志:

qizheng
(qizheng)
9
tidb 在遇到 tikv 返回以下文件中定义的几种类型 error 后(https://github.com/pingcap/tidb/blob/master/store/tikv/backoff.go#L48) ,重试 metric 会自增,监控看到的几种 error 可能是正常的调度行为。
可以检查下当前的调度参数设置是否合理
tiup ctl pd -u pd-ip:pd-port config show | grep schedule-limit
"leader-schedule-limit": 4,
"merge-schedule-limit": 8,
"region-schedule-limit": 4,
"replica-schedule-limit": 8,
1 个赞
Culbr
(Culbr)
10
Hi,我们现在遇到了同样的问题,但是日志反馈的写冲突并不严重。请问一下PD的调度参数怎样才算“合理”?或者说把region-schedule-limit从默认的2048改成4,除了降低region调度的频率之外,会有什么负面影响?感谢~
qizheng
(qizheng)
11
pd 调度参数默认就可以,如果是 4.0 版本,region-schedule-limit 默认的 2048 修改的必要性不大了,因为 tikv 这边引入了 store limit 的限制,默认是 15,简单说就是 pd 这边虽然可能发送比较多的调度任务到 tikv,但 tikv 侧做了限制。
1 个赞
qizheng
(qizheng)
12
写冲突不严重的话,先不用调整相关参数,可以检查下冲突是否符合业务预期,另外调大 region 调度会加快 region 迁移 balance 速度,可能会对延迟比较敏感的业务造成一些影响,关于 store-limit 参考 https://docs.pingcap.com/zh/tidb/stable/configure-store-limit#store-limit
1 个赞