写入程序是接收 kafka, 然后批量 500 条消息组合成一条 insert 插入 tidb, 平时接收消息的 qps 大概在 20-30w, 插入 tidb 的 insert 单条 qps 是 2.5w- 3.75w, 大概是 8:1 的比例, 然后 insert 是 500 row 一条, 最后 insert qps :
50- 75, 这是平时的 qps ; 大促期间的插入 tidb 的单条 insert qps 需要至少达到 8 w,
目前运行的情况是:
八个客户端写入, 8 cpu, 8192 mb 内存, 每个 50 个连接,
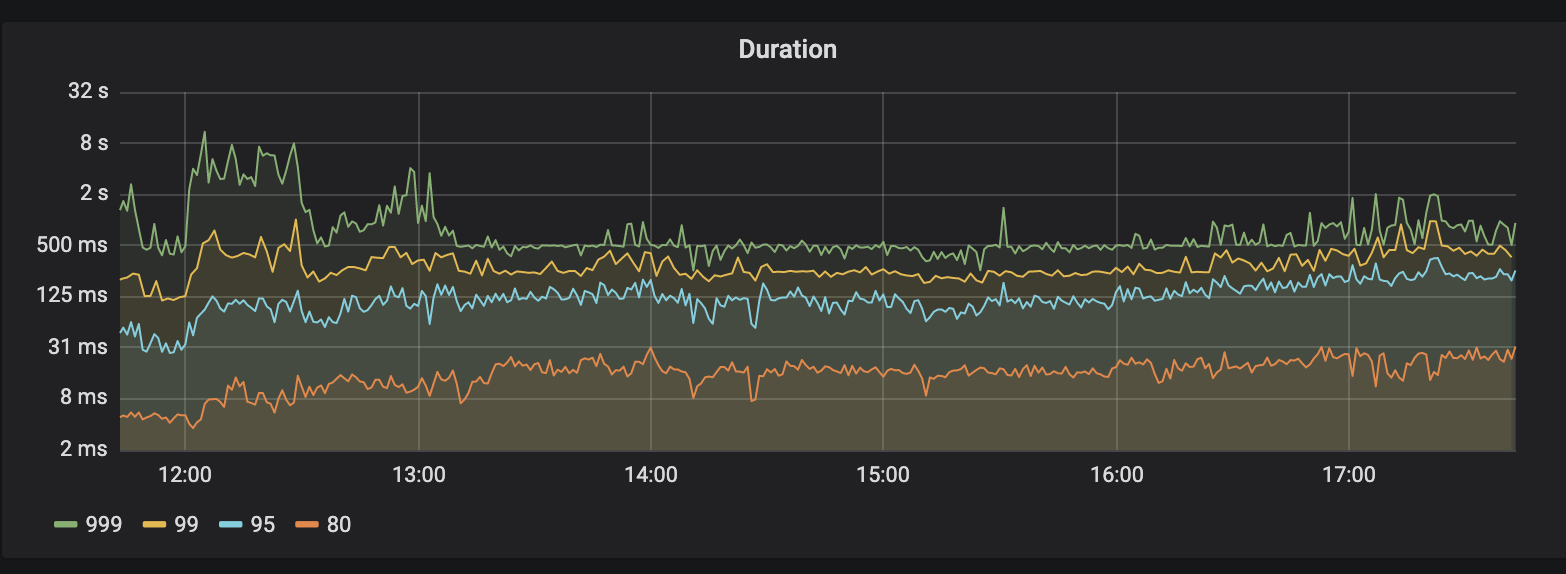
consume kafka 平均 qps 22w, 如图一, 对应 tidb 单条 insert qps : 2.75w, 但是波动比较大, 可能受集群其他业务写入的影响, 集群不是专用的,

集群配置如图二:
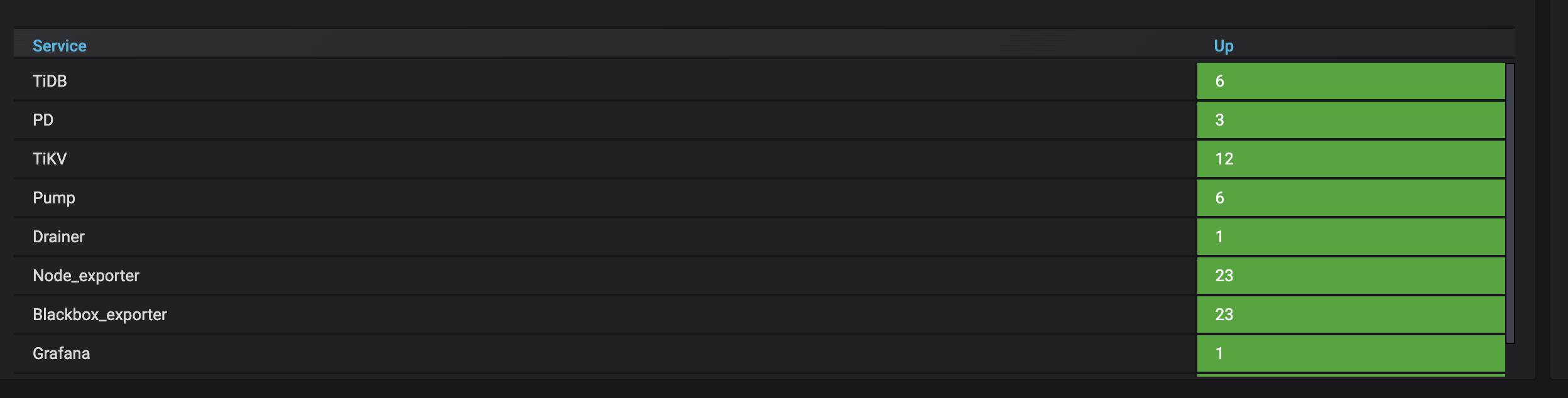
机器配置: 196G RAM, 2.5T RAID 5 SAS SSD. 48 core CPU
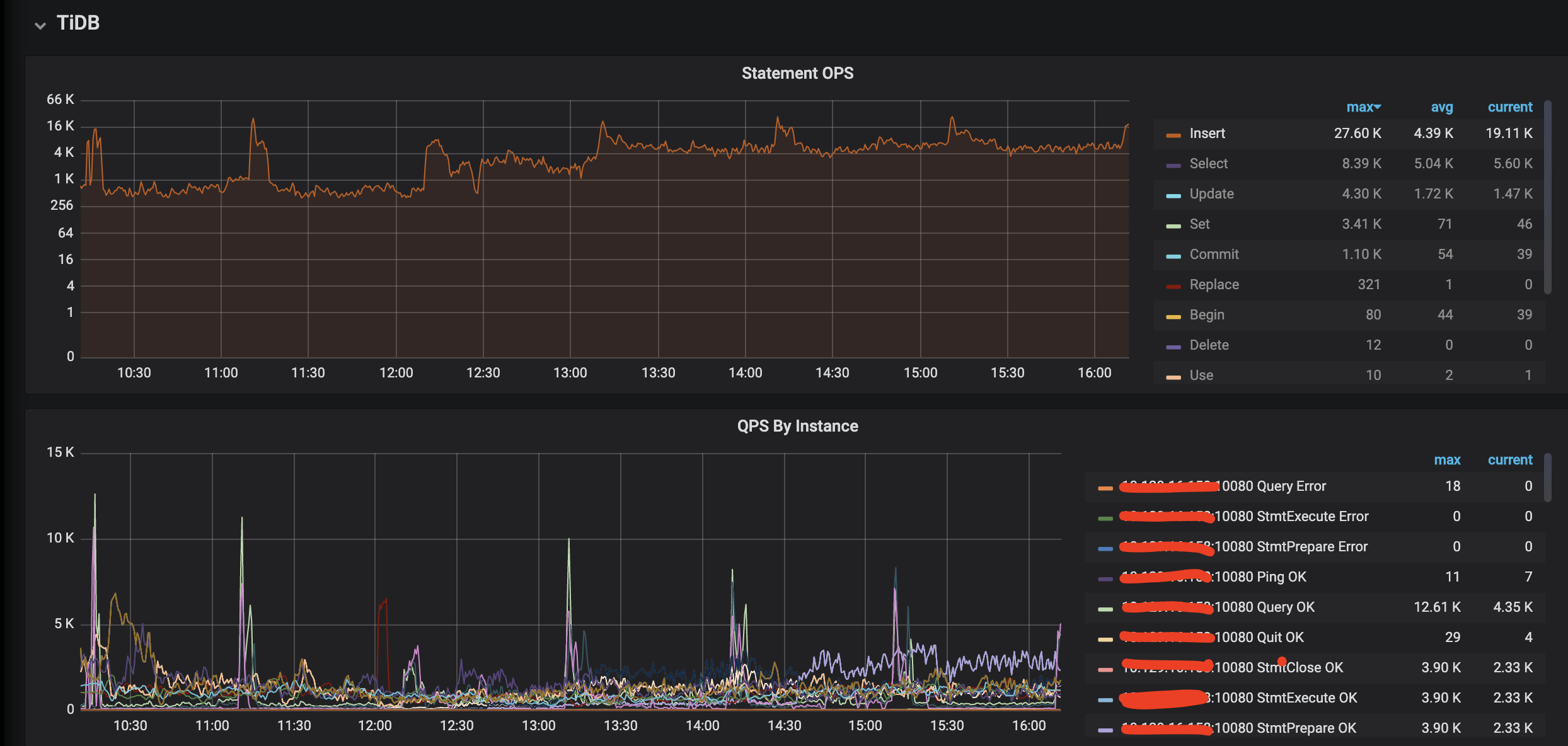
statement qps 如图三:
还需要什么信息可以再问我,
想问下:
- 能否估算出这个集群的最大 insert qps ,
- 目前应该没有达到写入 qps 的上限, 我们现在正在两台两台机器的往上加写入的并发, 但是又怕影响集群的整体性能, 应该如何观察, 看哪些指标判断是否到达了瓶颈以及是否影响集群的整体性能