ticdc 版本 5.0.1
链路: tidb->ticdc->kafka–>es
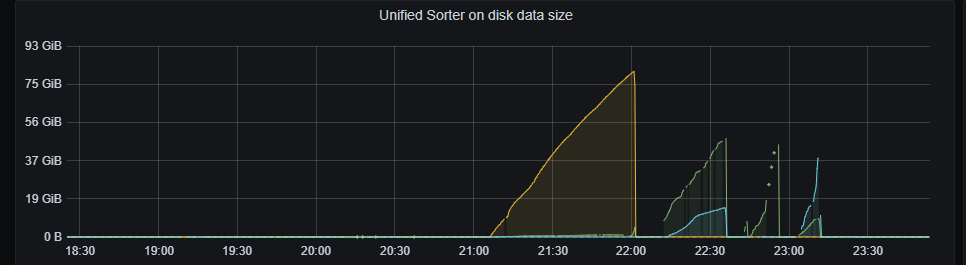
每个月的月初都会洗大批数据,ticdc的任务都会hang主, 我先暂停,然后恢复任务,等一会儿就又开始继续同步了。 是否有优化的空间,可以确定的是肯定跟变更的数据量有关系。
怎么排查解决这个问题?
QPS中的INSERT/UPDATE 大概7万多。
一批次更新或者插入 100-500之间
从cdc的日志中发现一段ERROR:
[2022/01/11 19:07:24.127 +08:00] [INFO] [client.go:935] [“EventFeed disconnected”] [regionID=2335235] [requestID=1198541] [span=“[6d44444c4a6f6241ff64ff644964784c69ff7374ff00000000 00ff000000f700000000ff0000006c00000000fb, 6d44444c4a6f6241ff64ff644964784c69ff7374ff0000000000ff000000f700000000ff0000006d00000000fb)”] [checkpoint=430414033444929542] [error=“[CDC :ErrEventFeedEventError]not_leader:<region_id:2335235 leader:<id:10826532 store_id:2 > > “]
1114651 [2022/01/11 19:07:24.127 +08:00] [INFO] [client.go:952] [“EventFeed retry rate limited”] [delay=199.166783ms] [regionID=2335235]
1114652 [2022/01/11 19:07:24.215 +08:00] [ERROR] [client.go:433] [“check tikv version failed”] [error=”[CDC:ErrGetAllStoresFailed]rpc error: code = Canceled desc = context canceled”] [erro rVerbose=“[CDC:ErrGetAllStoresFailed]rpc error: code = Canceled desc = context canceled
github.com/pingcap/errors.AddStack
\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0 a155152ca3/errors.go:174
github.com/pingcap/errors.(*Error).GenWithStackByCause
\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/normalize.go:279
github.com/pin gcap/ticdc/pkg/errors.WrapError
\tgithub.com/pingcap/ticdc@/pkg/errors/helper.go:28
github.com/pingcap/ticdc/pkg/version.CheckStoreVersion
\tgithub.com/pingcap/ticdc@/pkg/versio n/check.go:128
github.com/pingcap/ticdc/cdc/kv.(*CDCClient).newStream.func1
\tgithub.com/pingcap/ticdc@/cdc/kv/client.go:427
github.com/pingcap/ticdc/pkg/retry.Run.func1
\tgith ub.com/pingcap/ticdc@/pkg/retry/retry.go:32
github.com/cenkalti/backoff.RetryNotify
\tgithub.com/cenkalti/backoff@v2.2.1+incompatible/retry.go:37
github.com/cenkalti/backoff.Ret ry
\tgithub.com/cenkalti/backoff@v2.2.1+incompatible/retry.go:24
github.com/pingcap/ticdc/pkg/retry.Run
\tgithub.com/pingcap/ticdc@/pkg/retry/retry.go:31
github.com/pingcap/tic dc/cdc/kv.(*CDCClient).newStream
\tgithub.com/pingcap/ticdc@/cdc/kv/client.go:421
github.com/pingcap/ticdc/cdc/kv.(*eventFeedSession).dispatchRequest
\tgithub.com/pingcap/ticdc@ /cdc/kv/client.go:788
github.com/pingcap/ticdc/cdc/kv.(*eventFeedSession).eventFeed.func1
\tgithub.com/pingcap/ticdc@/cdc/kv/client.go:575
golang.org/x/sync/errgroup.(*Group).Go .func1
\tgolang.org/x/sync@v0.0.0-20201020160332-67f06af15bc9/errgroup/errgroup.go:57
runtime.goexit
\truntime/asm_amd64.s:1357”] [storeID=3]
1114653 [2022/01/11 19:07:24.215 +08:00] [WARN] [client.go:791] [“get grpc stream client failed”] [regionID=5515474] [requestID=1198537] [storeID=3] [error=“[CDC:ErrGetAllStoresFailed]rpc error: code = Canceled desc = context canceled”]
1114654 [2022/01/11 19:07:24.215 +08:00] [INFO] [region_cache.go:601] [“mark store’s regions need be refill”] [store=10.1.13.7:20160]
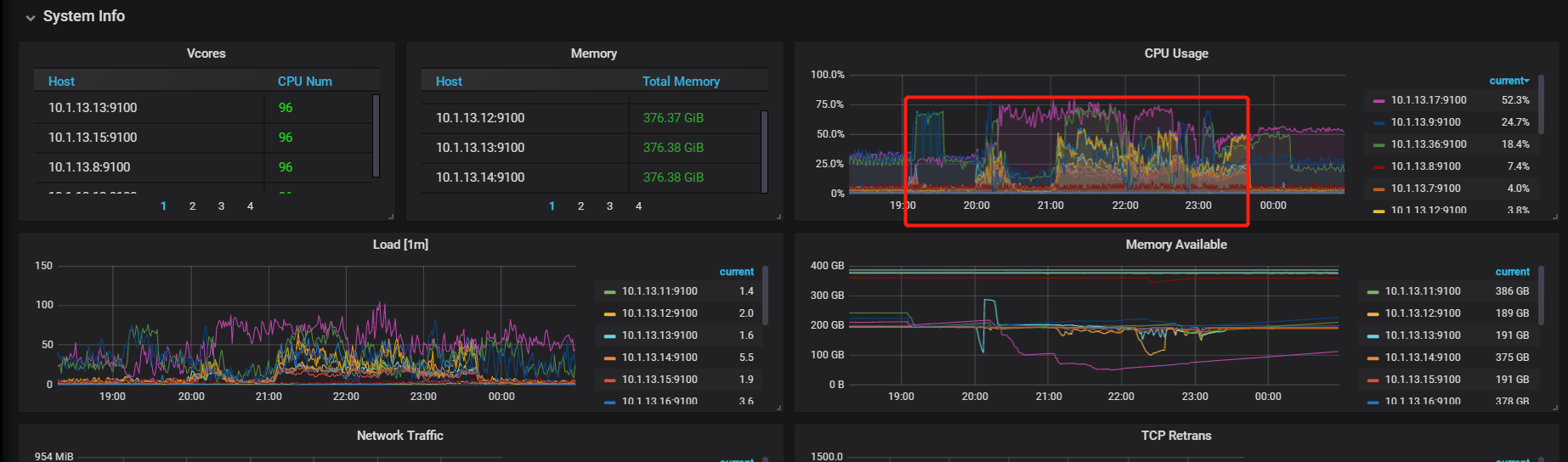
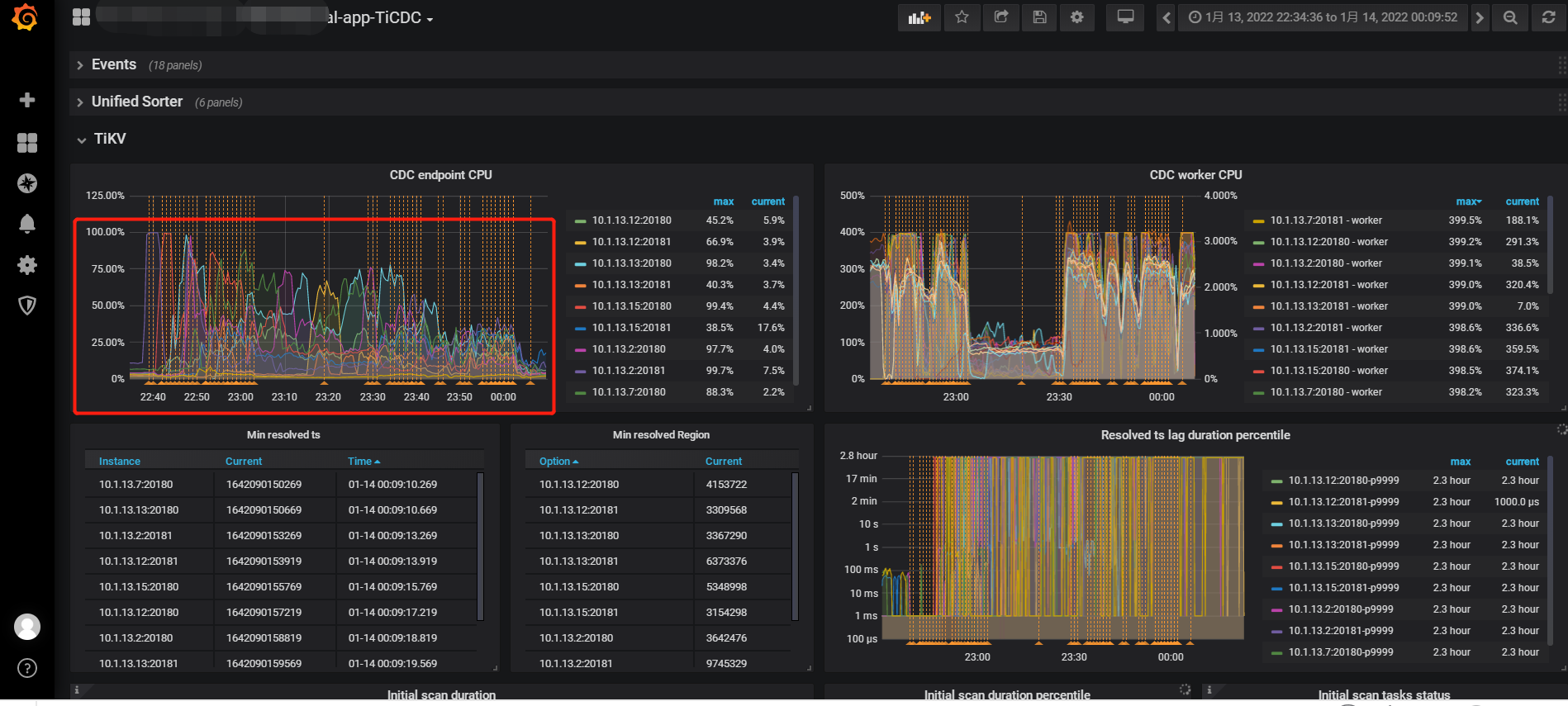
从监控图上看到:CDC endpoint cpu线程 100% ,不清楚这个线程是什么意思。
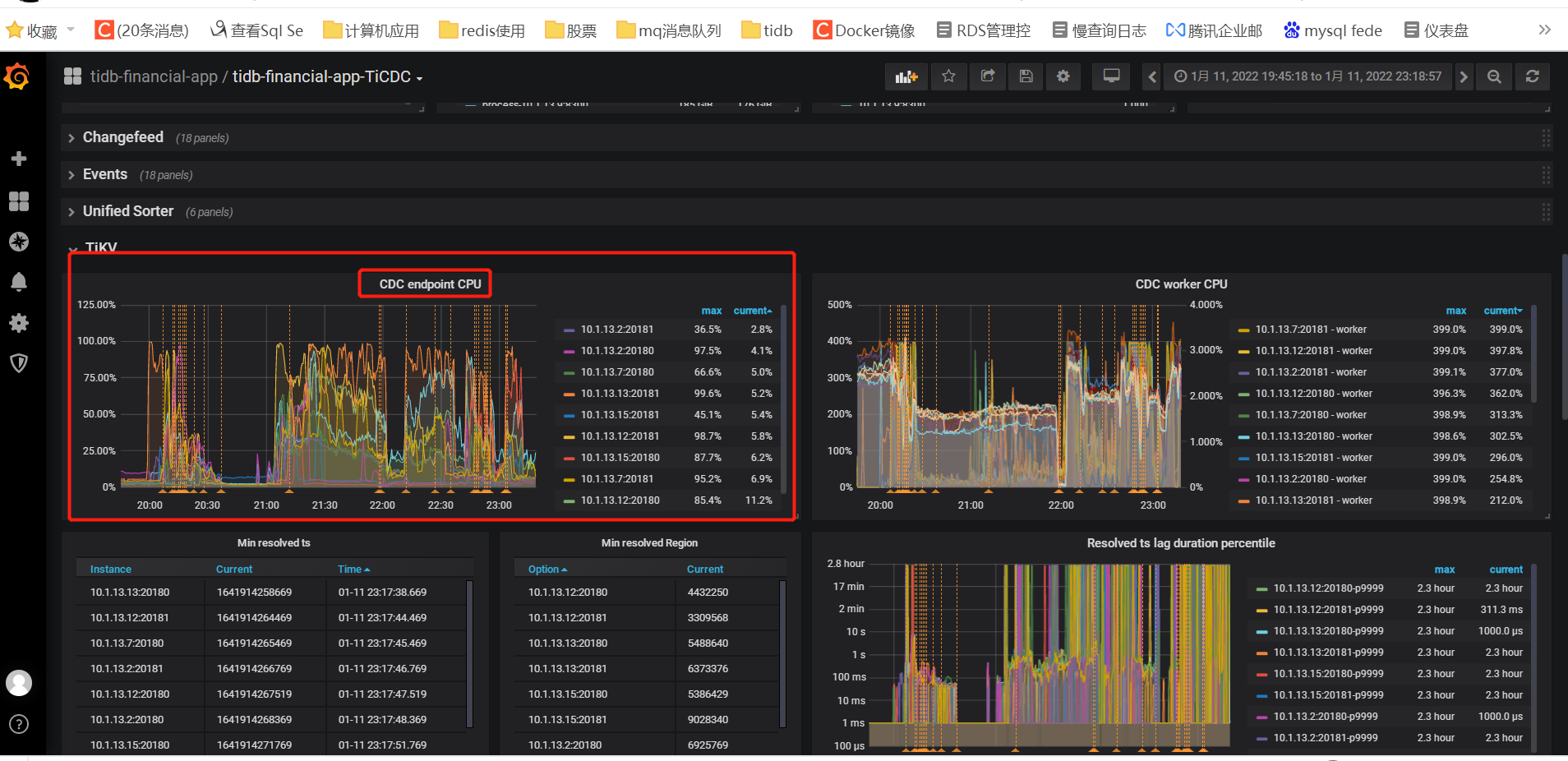
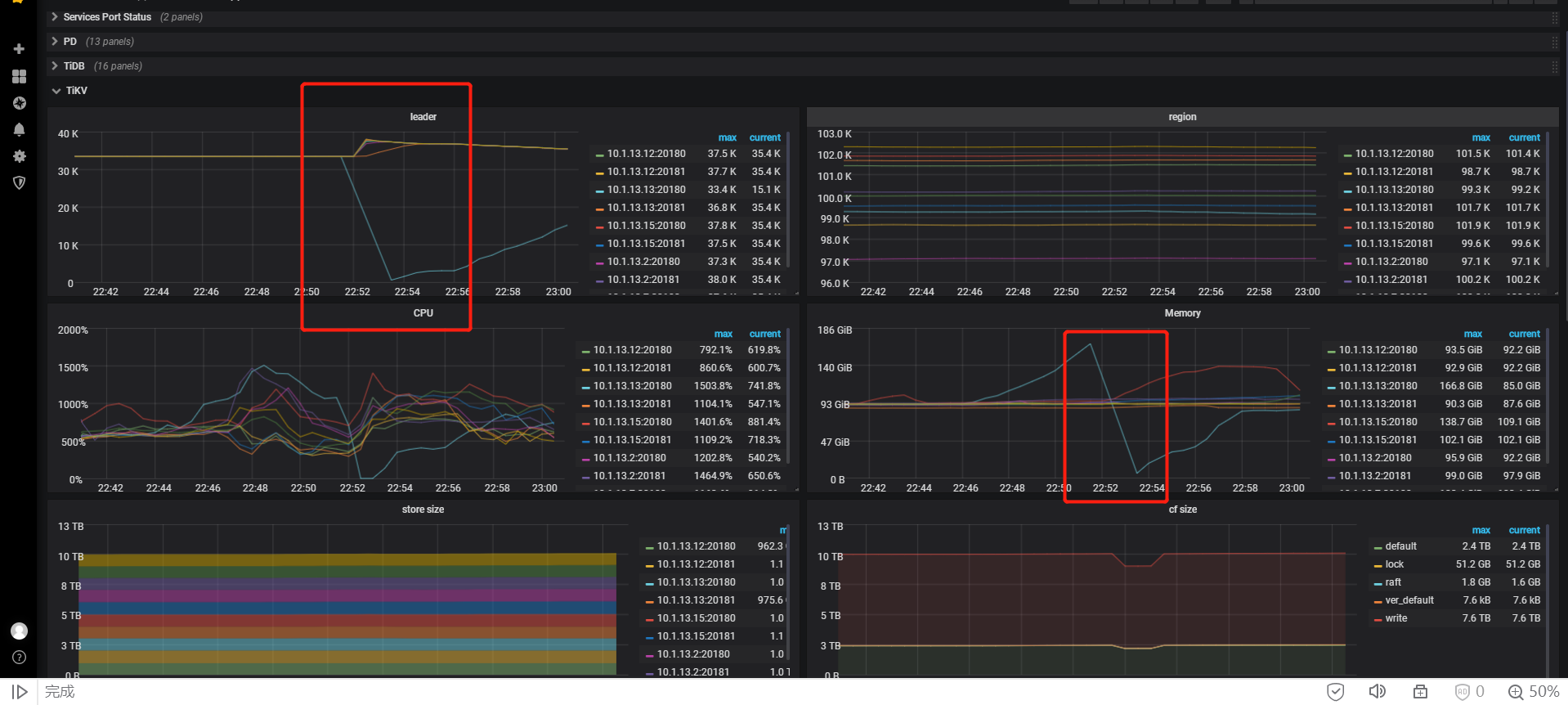
其中一个tikv节点,还挂了一次。