Tidb版本3.0.13
tidb集群遇到断电,重启tidb后发现tikv起不来
这种情况能恢复吗
1、部署的方式是ansible
inventory.ini (3.0 KB) pd.txt (7.3 KB)
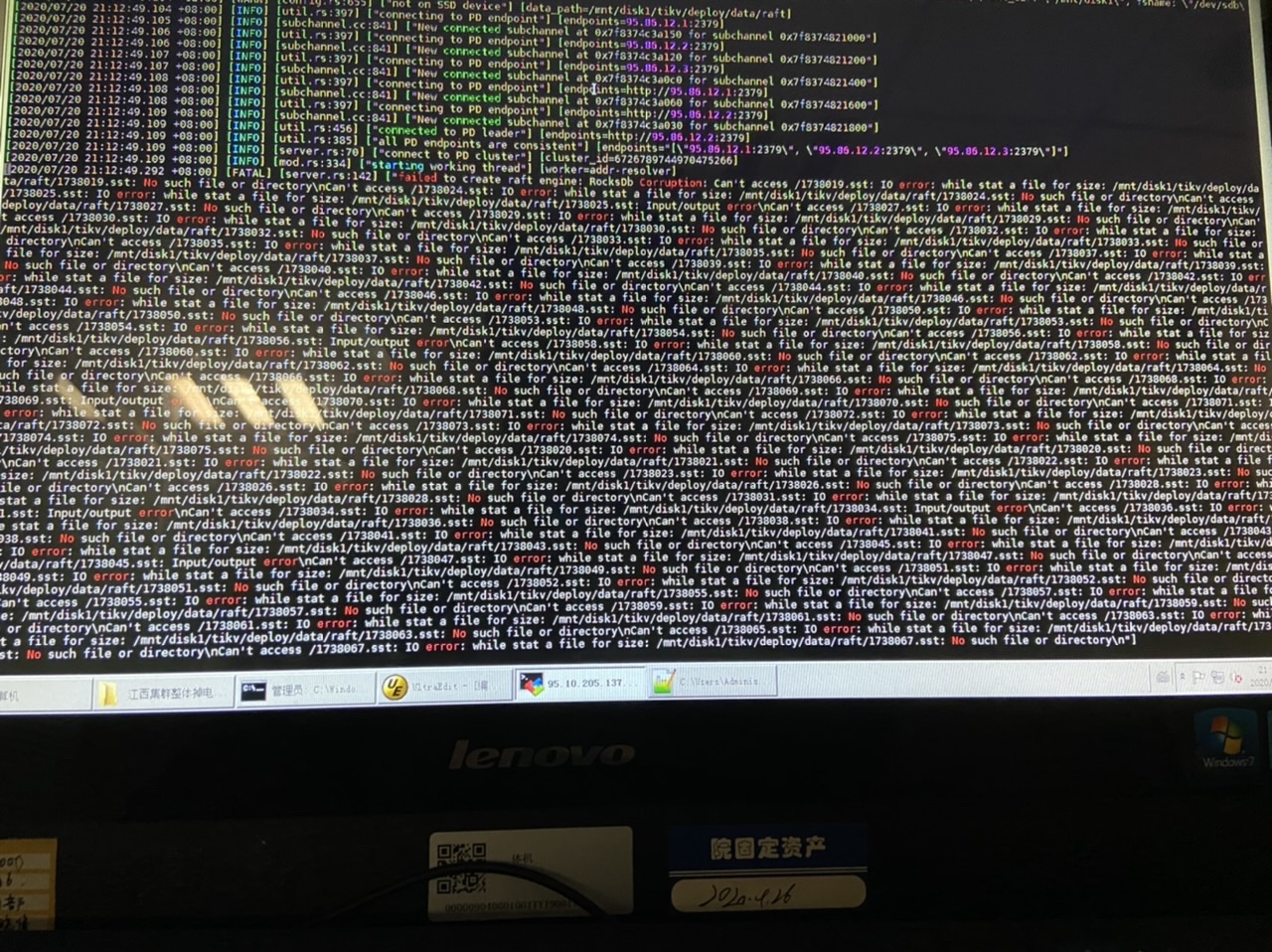
最开始是3个pd,3个tidb,3个tikv。断电后,启动tidb,发现95.86.12.1上面的pd起不来,通过缩容再扩容的方式修复了pd,再次启动tidb,发现95.86.12.1与95.86.12.2上面的tikv起不来,对起不来的tikv做了下线,然后扩了3个tiKv节点。做完这些操作后,再次启动tidb,发现3台tidb都起不来。
![]()
cd 到此目录,
ls -l 查看下,多谢。
从图中看 Raft 数据已损坏,请问是否开启了 sync-log 呢?是单个 TiKV 挂了还是有多个 TiKV 都挂了呢
sync-log是默认配置,3台tikv节点,2台起不来。有希望恢复吗,现在3个tidb节点都起不来,tidb数据库用不起来。有啥办法先让tidb能起来。
由于raft数据损坏,所以当前数据一定会有丢失。请参考文档,强制-region-从多副本失败状态恢复服务。
https://pingcap.com/docs-cn/stable/tikv-control/#强制-region-从多副本失败状态恢复服务
我在损坏的tikv节点上指定tikv-ctl命令,查询出错的region。报错tikv.txt (6.4 KB)
我查看region的时候,bin/pd-ctl -u “http://95.86.12.1:2379” -d store
{
“count”: 6,
“stores”: [
{
“store”: {
“id”: 4,
“address”: “95.86.12.2:20160”,
“state”: 1,
“version”: “3.0.13”,
“state_name”: “Offline”
},
“status”: {
“leader_weight”: 1,
“region_weight”: 1,
“start_ts”: “1970-01-01T08:00:00+08:00”
}
},
{
“store”: {
“id”: 5,
“address”: “95.86.12.3:20160”,
“version”: “3.0.13”,
“state_name”: “Up”
},
“status”: {
“capacity”: “8.991TiB”,
“available”: “7.932TiB”,
“leader_weight”: 1,
“region_weight”: 1,
“start_ts”: “2020-07-21T11:35:30+08:00”,
“last_heartbeat_ts”: “2020-07-21T14:16:43.881442993+08:00”,
“uptime”: “2h41m13.881442993s”
}
}
发现没有显示leader与region的个数
可以使用强制命令,删除整个store来恢复
我使用pd的命令删除store,
store delete 1,store 1的状态一直是offline。删除store还有其他命令?
没有找到强制删除命令
我tikv-ctl的命令一执行就报错,报sst文件找不到
不好意思,我store1与store4启不来,在store1执行tikv-ctl命令,踢出store1与4报相同的错误
在store4上执行命令,踢出store4不报错,踢出store1报错
在其他store上面执行tikv-ctl命令正常。
另外我启动tidb时,也报错。
你好。unsafe-recover 是在所有未发生掉电故障的机器上运行;TiKV 处于关闭状态。
同时请问下,您是否是使用虚拟机部署的? 有大量的sst文件都丢失了?
使用真机部署的,一共3个tikv,因为断电,第一台机器丢了大量sst文件,第一个与第二个tikv起不来,使用unsafe-recover命令,tikc-ctl --db /path/to/tkv/data/db unsafe-recover remove-fail-stores -s 1,4 --all-regions。tidb集群可以启动了,但是,我一激动把唯一能起的来的tikv的部署目录给删了,有什么办法可以把数据恢复出来,现在集群就剩2个起不来的tikv了。
使用unsafe recover 恢复后,就只剩这一个可以使用的节点了。如果这个节点也被删除了,那就没法恢复了。
可以通过把前面2个挂掉的tikv修好,来恢复数据吗,或者再扩容几个tikv,可以把挂掉的2个tikv的数据迁移到扩容后的tikv上吗