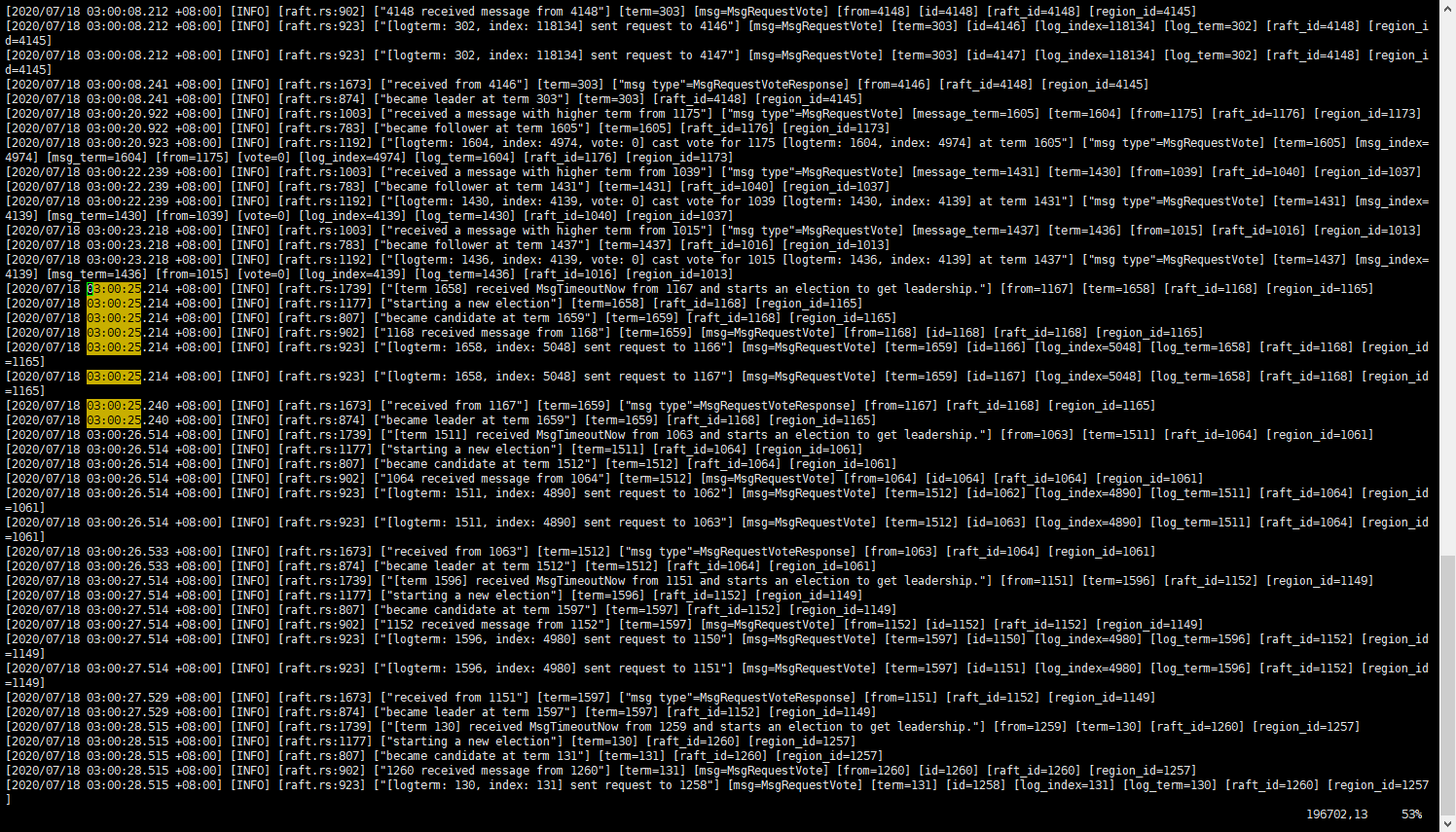
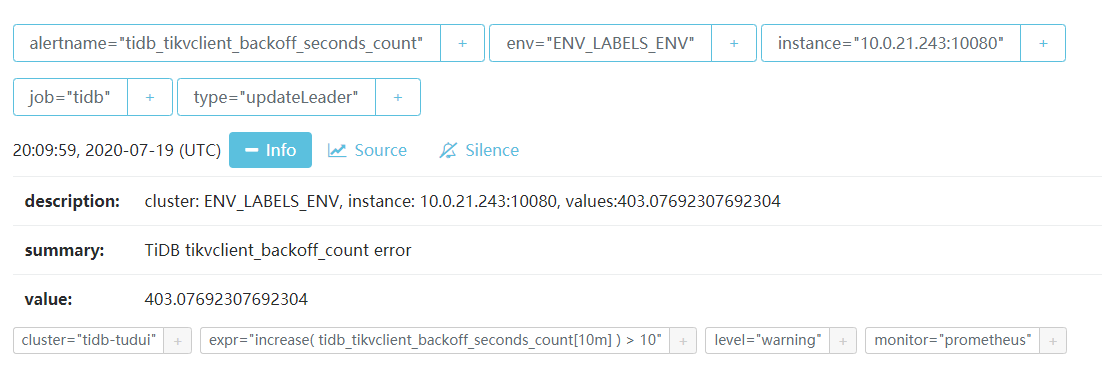
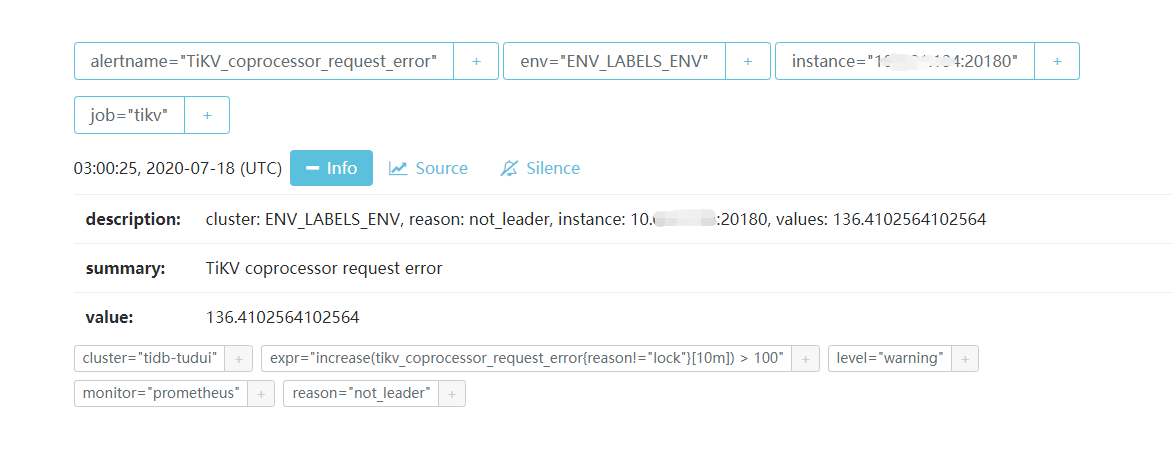
这是告警界面的显示:
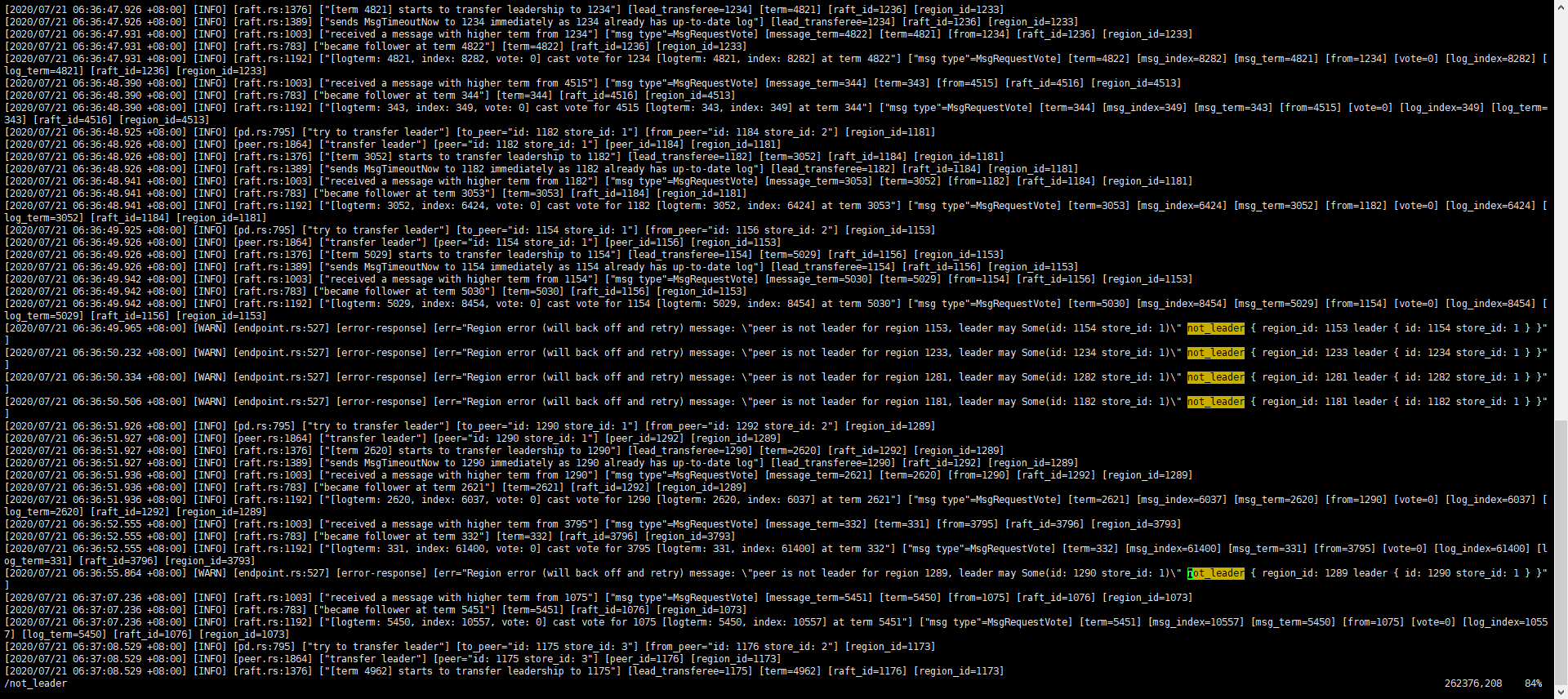
这是当前时间点相应IP地址的节点(TIKV)的日志:
谢谢这位老师,这错误出现次数挺多的,每隔两三个小时都会有一次。目前正在向集群里拉数据,业务那边反应写入数据经常会报错,至于正在写入的那条数据报错以后是否写入成功了,我再去和业务那边复查一下,如果写入成功就先忽略掉它。不过最近又开始伴随着这个错误:
https://docs.pingcap.com/zh/tidb/stable/alert-rules#tikv_coprocessor_request_error
此报错应该是 tikv 重试在规定时间内超过一定次数了,已为失败的操作,该事务应该会在前端报错了。可以先验证下数据是否一致吧,如果还一直有此类的报错产生,可以发一下报错时间点的 tikv.log 和 tidb.log,先看下。
仔细检查了一下,数据暂时没有发现丢失,或者重要数据暂时没有问题。不过我略担心以后会出问题,因为我发现虽然告警界面展示的告警信息not_leader不多,几个小时才发生一次,但是我发现日志里特别多,几乎每几分钟都在不停的warn,日志如下:
可以尝试使用 tidb performance map 排查看下
https://github.com/pingcap/tidb-map/blob/master/maps/diagnose-map.md#72-tikv
再继续观察吧,这日志总感觉不是特别正常,一水的都是切换leader,完了warn not_leader……
ok,看下上面的链接,有疑问可以继续跟帖
好的,谢谢,我去瞅瞅
![]()
Hi, 频繁写入的时候 not leader 数量增多是比较正常的,对于 not leader TiDB 内部会重试,not leader 也不会导致已写入成功的数据丢失。
了解了,谢谢。对了,再问一个问题,我线上集群的Grafana 登陆不上去了,我没记得有账户密码,但是让我输入账户密码才能登陆,我输入数据库的root账户和对应的密码不行,点忘记密码说发邮件重置,完了我填了我的邮箱却没在邮箱里收到重置密码的邮件……就很尴尬,更尴尬的是测试集群的Grafana 界面想怎么进就怎么进……您这边有什么办法吗?
默认账号密码为 admin admin 试下。
谢谢,就是这个默认密码,是我傻了,测试集群用过,正式集群给忘了……
嗯,好的
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。