tidb v4.0.0
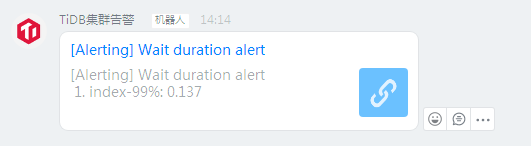
集群部署是从3.0版本升级至4.0,参数都是默认,没有做修改。现在看tidb内存使用告警,点击链接进去后看到是如下图:

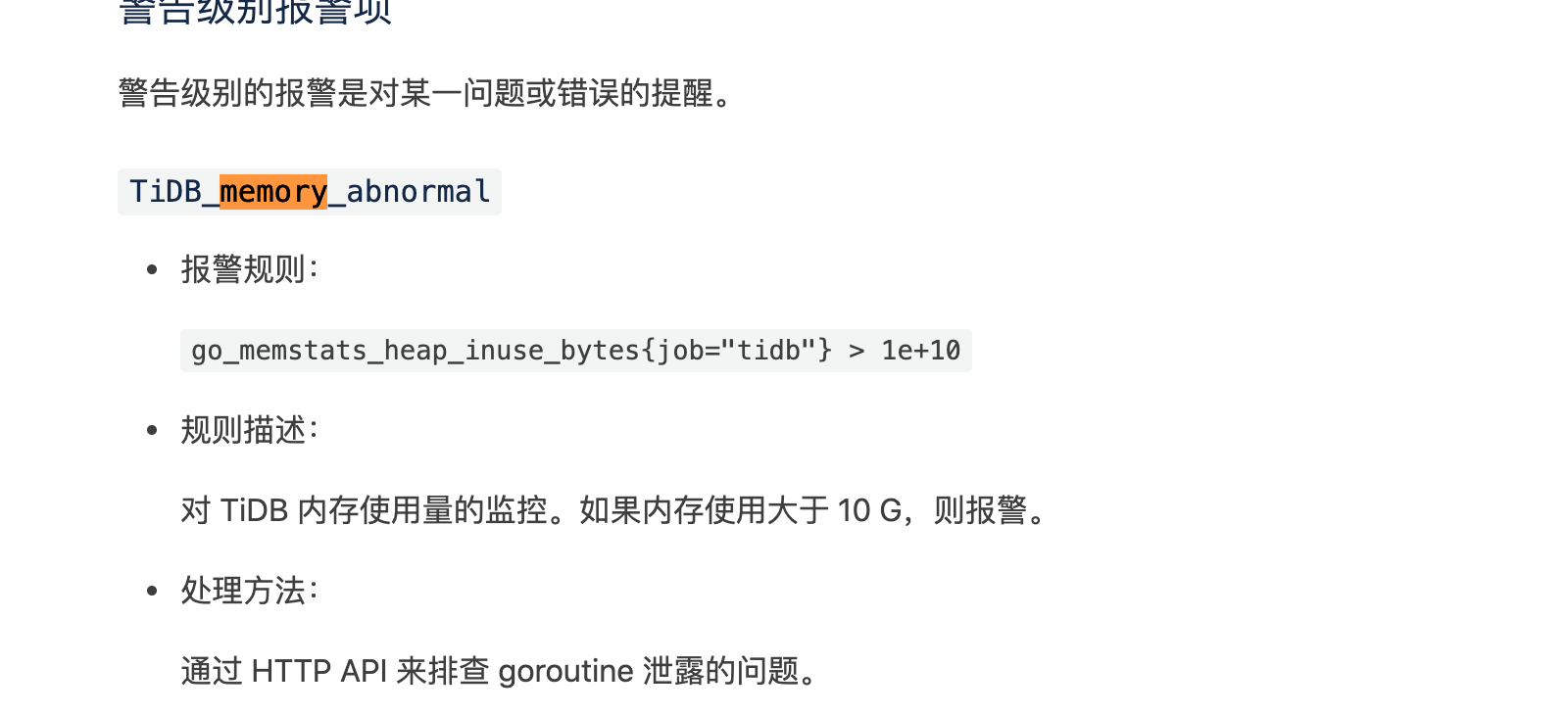
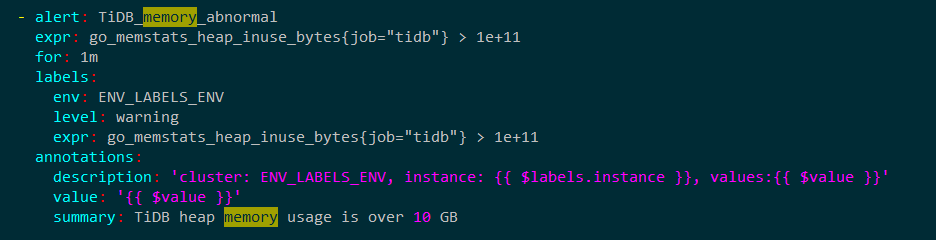
看到阈值是1G,然后在deploy/conf下查看tidb.rules.yml,看到告警阈值是10G
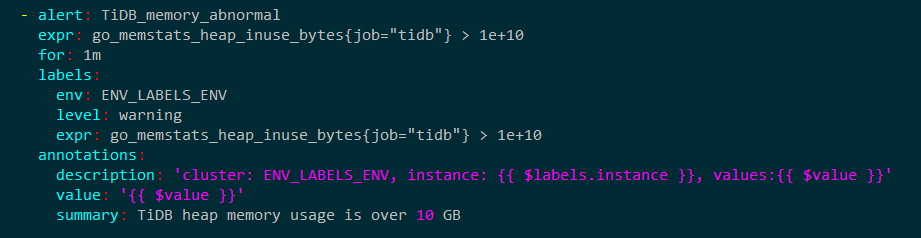
这个告警配置是在这个tidb.rules.yml文件吗?对不上
tidb v4.0.0
集群部署是从3.0版本升级至4.0,参数都是默认,没有做修改。现在看tidb内存使用告警,点击链接进去后看到是如下图:
看到阈值是1G,然后在deploy/conf下查看tidb.rules.yml,看到告警阈值是10G
这个告警配置是在这个tidb.rules.yml文件吗?对不上
麻烦发一下报警的文本信息,我们分析一下。
是提供tidb.rules.yml文件吗?
请问这个文本怎么获取?不太熟悉
可以发一下告警的内容么?
内容就是上面截图这个链接,还需要什么内容呢?没怎么理解
或者能不能给我一个提取的语句或者命令什么的,我取一下
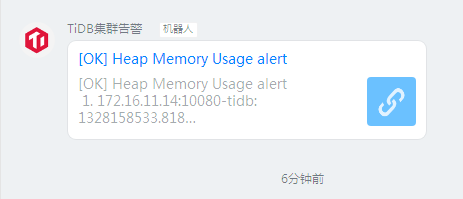
机器人里面报警是一个链接,链接里面没有具体的报错文本么 ?想要看一下这个告警是多少的报错阈值。现在只看到是有告警,有告警日志么 ?
机器人里面看到就一个链接(如上图),没有地方看文本。然后点击链接就是上面的那个监控图,图上有告警阈值
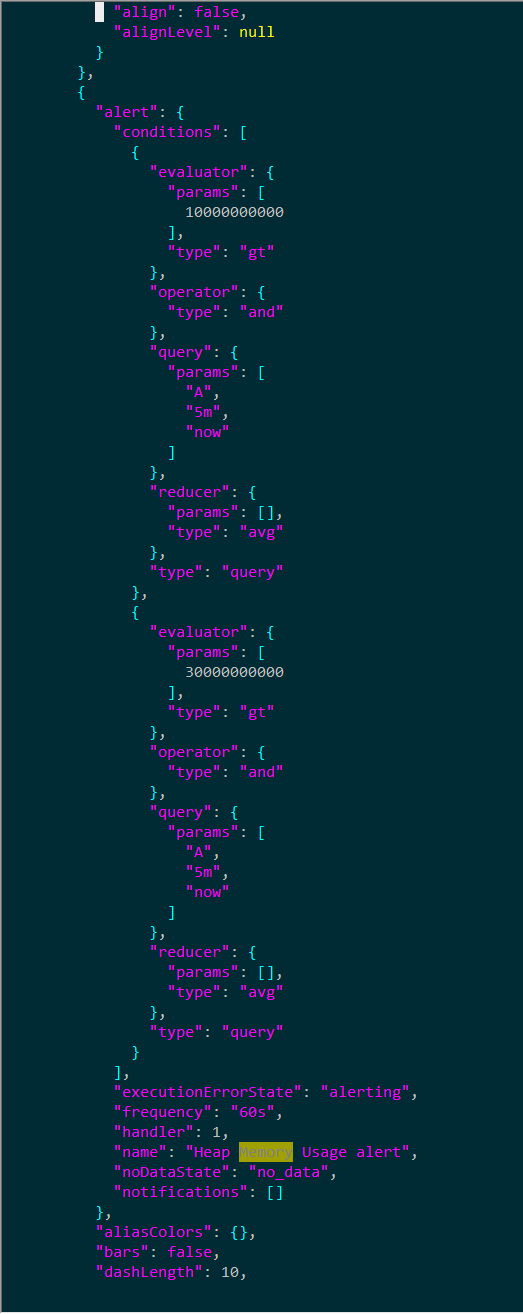
如果是报警是上面描述的这个 tidb_memory_abnormal ,那么告警阈值是 10G
https://pingcap.com/docs-cn/stable/alert-rules/#tidb_memory_abnormal
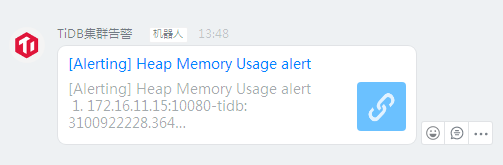
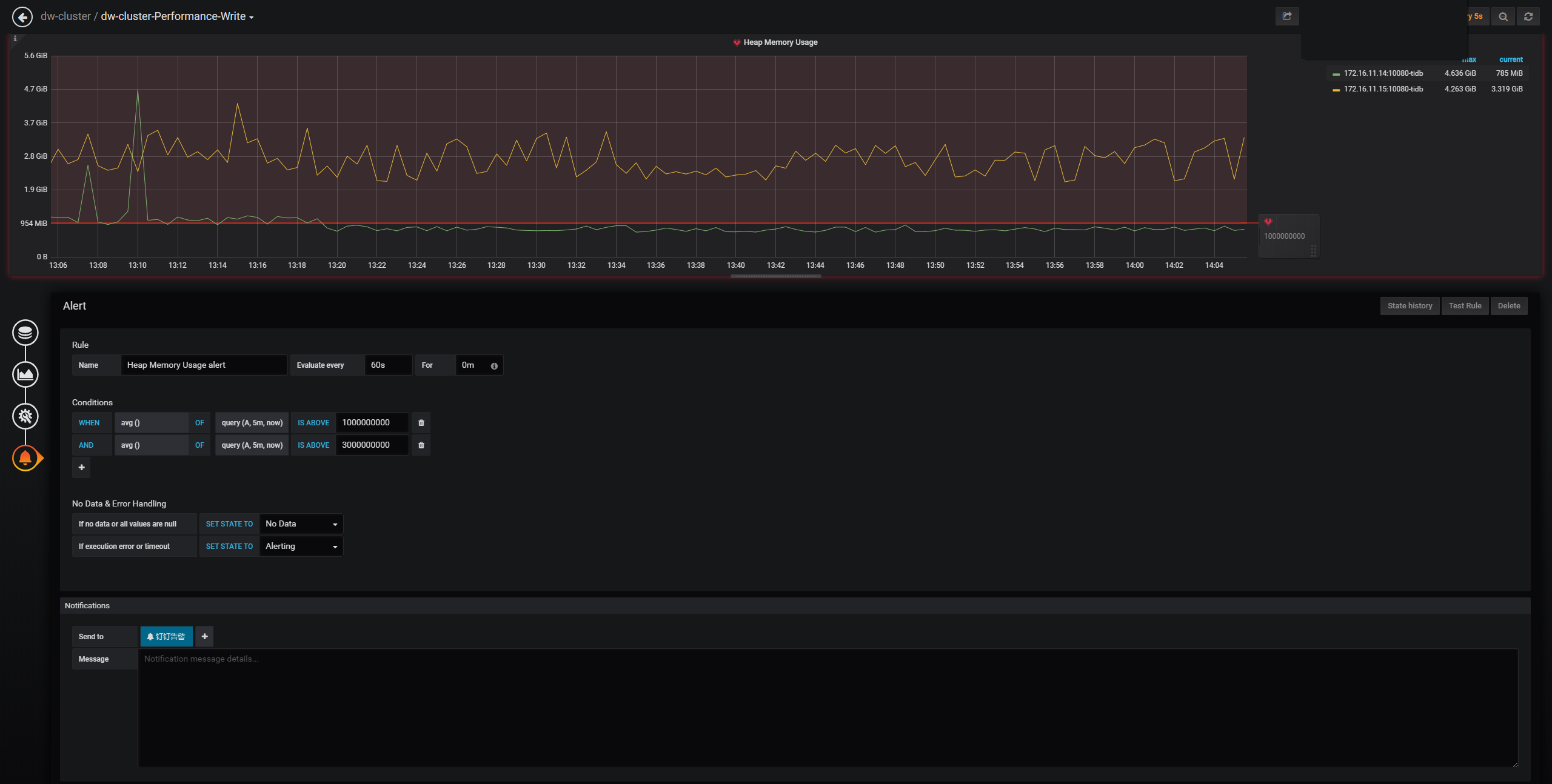
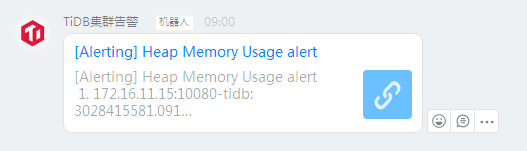
这是刚那会的告警,13:48分的,这个机器人点开链接是下面这个图
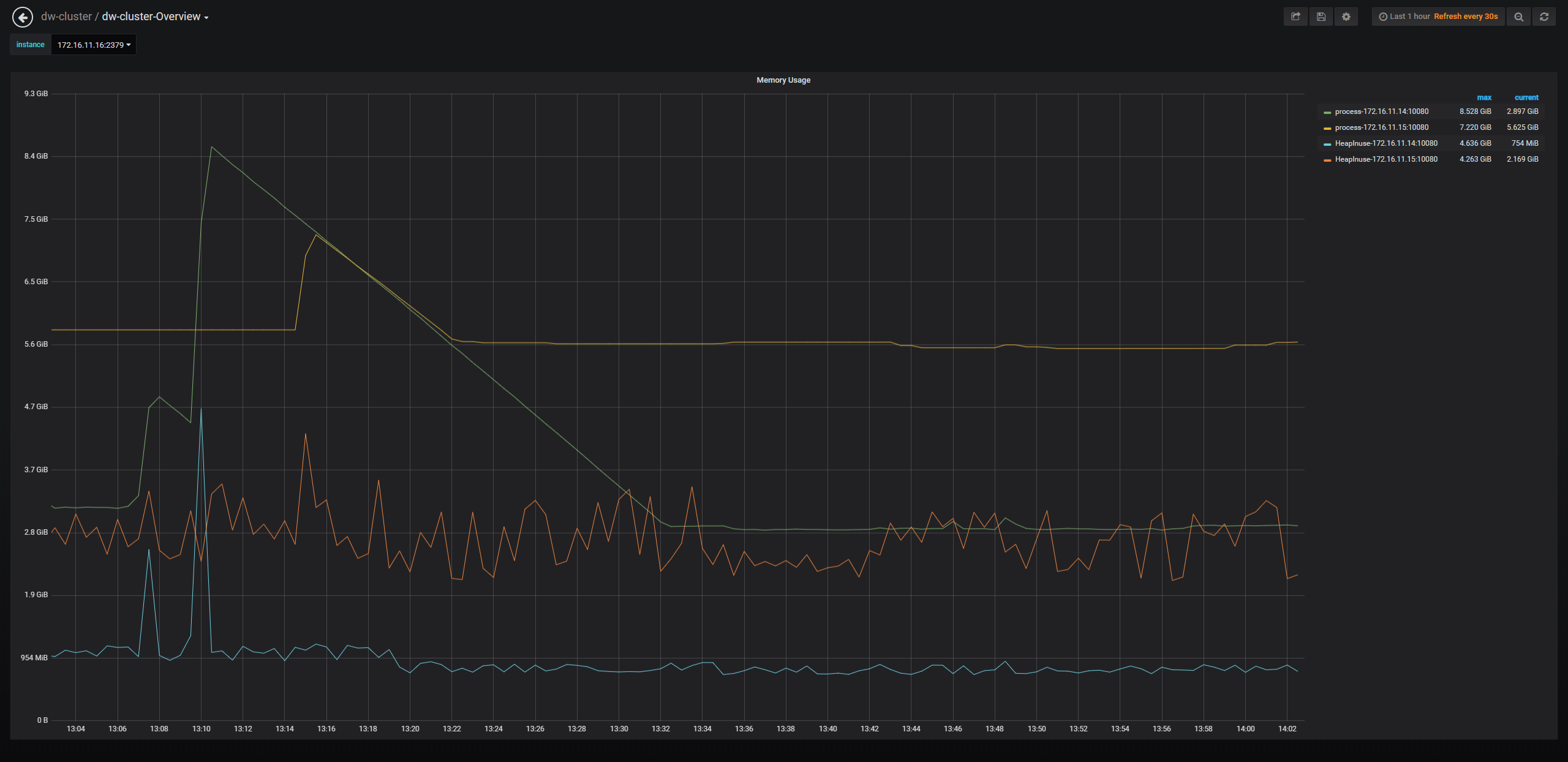
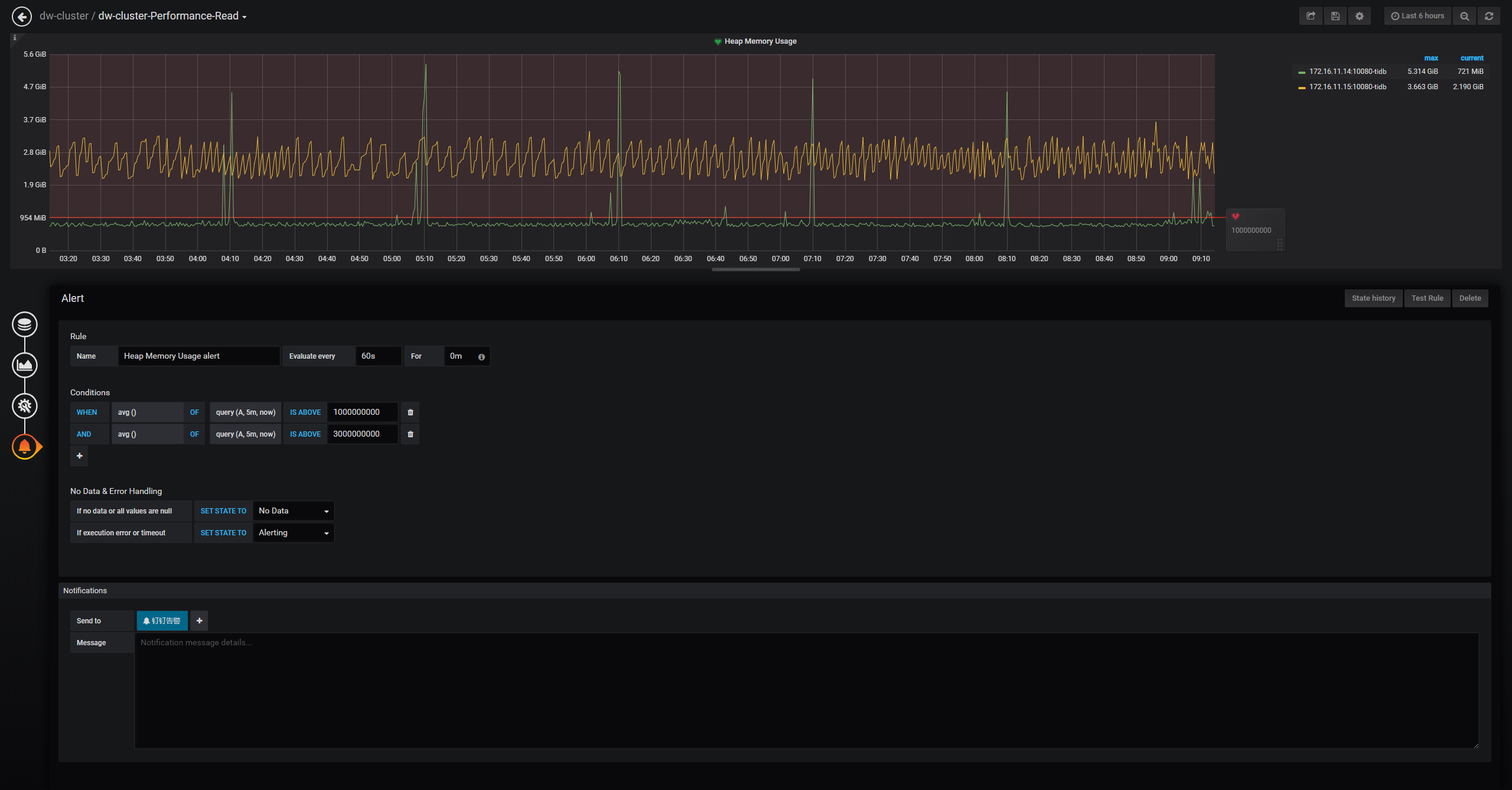
从图中看是阈值是1G就告警,然后我拉取最近一小时的tidb内存使用监控,如下图
感觉这告警比较混乱,是1G阈值话,肯定有很多告警。如果是10G阈值的话,那应该没有告警。
监控的相关的配置都是初始化默认的,没有修改过。
点击 edit ,找到具体的属于哪个监控项
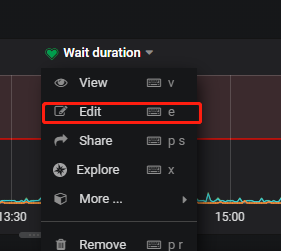
继续查看edit,就可以找到:
找到对应的规则介绍:
https://docs.pingcap.com/zh/tidb/stable/alert-rules#tikv_coprocessor_request_wait_seconds
上面那个内存10G告警,我想修改阈值,是直接编辑tidb.rules.yml这个文件,然后重启一下prometheus吗?
重启命令tiup cluster restart dw-cluster -N x.x.x.x:9090是这样吗?
找到 Prometheus 安装服务器的部署目录的/bin目录下,修改这里的rules文件,之后再重启,多谢。
嗯,改为100G,是想试试修改哪一个文件可以生效。但没成功。
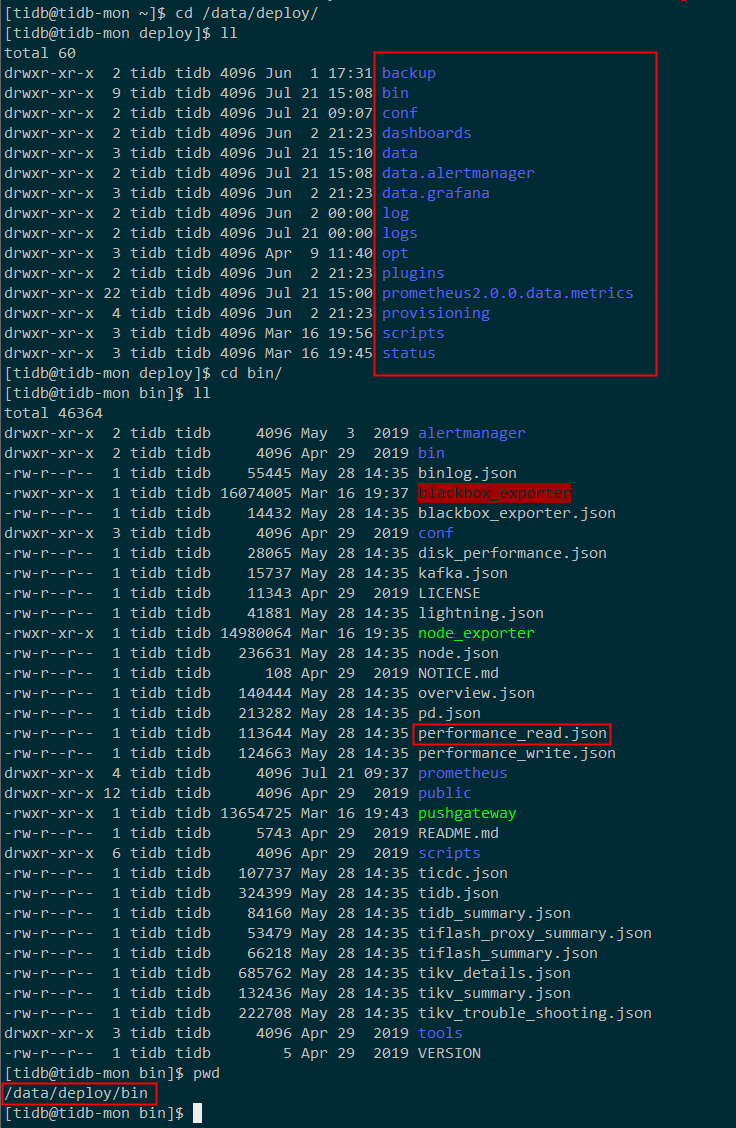
我这是从3.0.11升级至4.0.0的,中控机(监控也安装在此机器上)的deploy目录是:/data/deploy,如上图,没有单独的grafana目录
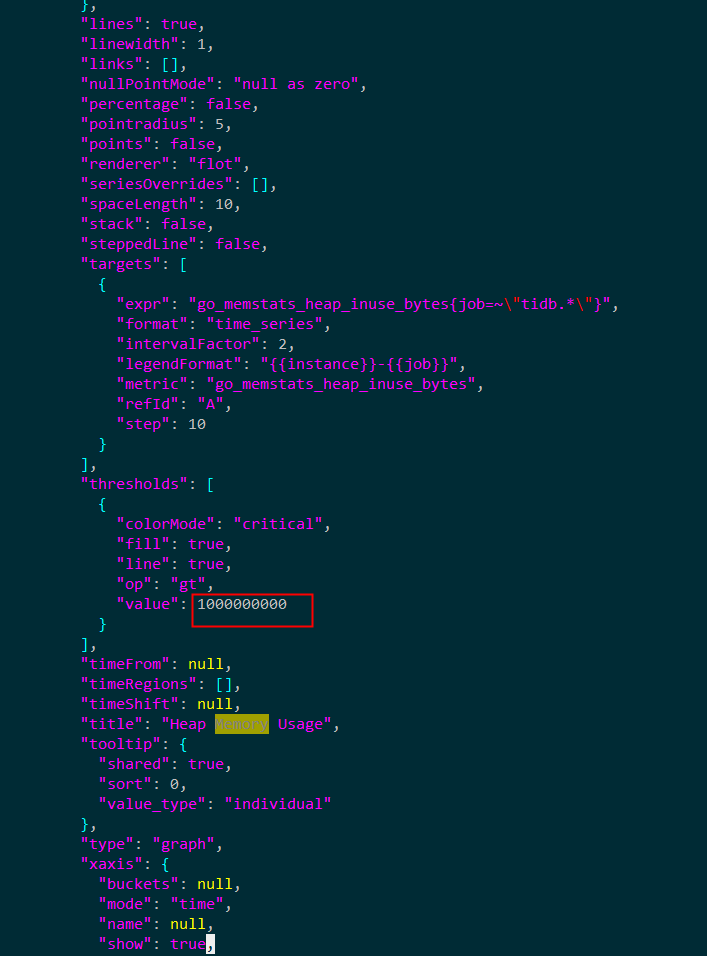
在/data/deploy/bin这下面找到performance_read.json,打开后如下图
这里也是10G,这也不对
这里是 1G 吧?