[2020/07/17 13:14:57.091 +08:00] [INFO] [mod.rs:335] [“starting working thread”] [worker=addr-resolver]
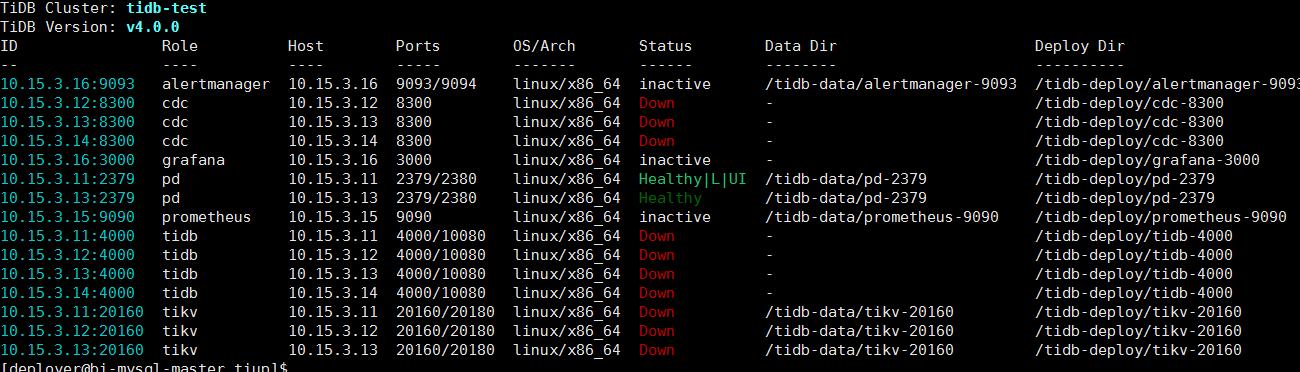
看信息比较明确,但是需要如何清理掉缩减的PD: 10.15.3.14:2379
请问是缩容的 PD,然后现在启动不了么? 麻烦确认一下缩容操作如何进行的,另外通过 pd ctl 查询一下当前 PD cluster 状态。
pd-ctl -u "http://10.15.3.11:2379" member
如果是通过 tiup scale-in 缩容的 pd 节点,如果有报错,麻烦发一下完整的报错 log 日志。
是通过tiup scale-in 缩容的,新建文本文档.txt (20.0 KB)
日志中的报错意思说明 TiKV 启动参数中存在两套 PD cluster,所以麻烦确认一下 TiKV 的启动命令是不是有 10.15.3.14:2379 节点配置,并且 10.15.3.14:2379 是启动的。
tikv启动脚本里面的确还有10.15.3.14:2399,但是我需要怎么操作?手动删除?
然后我也手动kill掉了10.15.3.14:2399 这个进程了
说明你执行 tiup scale-in 缩容 pd 没有成功,目前处理办法是手动将 tikv 启动命令的中的 14 节点配置信息删除,然后将 14 的 pd 服务强制停止掉。手工 kill 服务是不管用户,因为 pd 服务是通过 systemd 来守护,建议通过对应的 systemd 服务停止,并且将 14 节点的 pd 服务移除。
现在的情况是已经按照你说的将14的pd停止了,然后rm -rf 掉了tidb-data 和tidb-deploy 下的pd-2399,
“pd”:{“endpoints”:[“10.15.3.11:2379”,“10.15.3.13:2379”,“10.15.3.14:2399”]
[“failed to start node: “[src/server/node.rs:204]: cluster ID mismatch, local 6835897265761420397 != remote 6850291615725620059, you are trying to connect to another cluster, please reconnect to the correct PD””]
我采用手工启动的,endpoint里面的也没有了14的信息了,但是依然还是在报错
麻烦滚动一下 TiDB 集群
tiup cluster reload tidb-test
感觉陷入死循环了,这个要让我先启动tikv,然后手动启动tikv又报ID mismatch
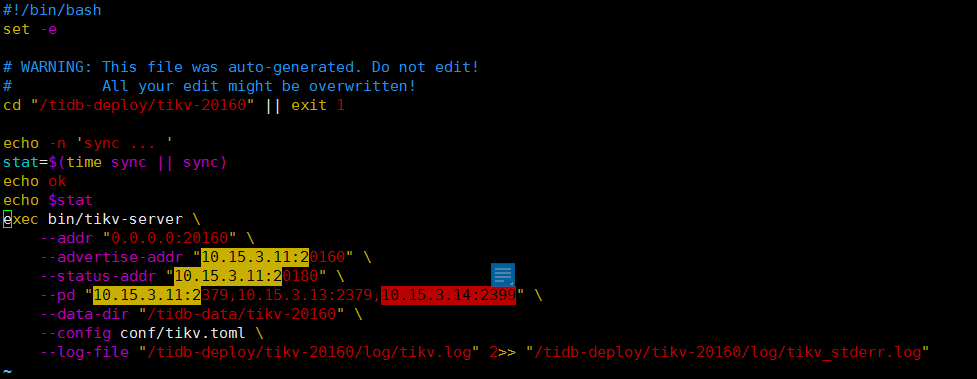
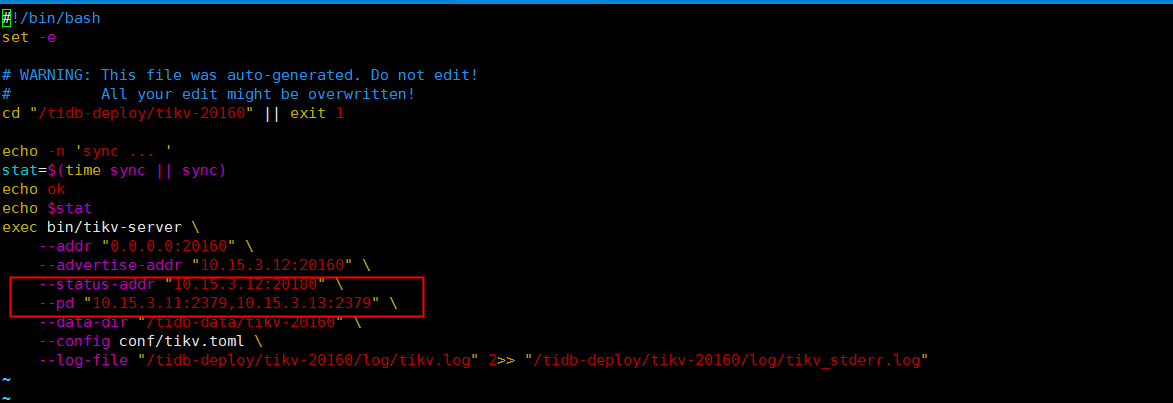
麻烦发一下 tikv 的 deploy 目录下面的 run_tikv.sh 里面是否有这个 pd 配置,尝试删除一下。
目前三个tikv的run_tikv.sh里面都没有这个信息了,但是他还在 在报 cluster ID的问题
请教一下,如何清空本地的local cluster ID?
3.4.2 TiKV 启动报错:cluster ID mismatch
TiKV 本地存储的 cluster ID 和指定的 PD 的 cluster ID 不一致。在部署新的 PD 集群的时候,PD 会随机生成一个 cluster ID,TiKV 第一次初始化的时候会从 PD 获取 cluster ID 存储在本地,下次启动的时候会检查本地的 cluster ID 与 PD 的 cluster ID 是否一致,如果不一致则会报错并退出。出现这个错误一个常见的原因是,用户原先部署了一个集群,后来把 PD 的数据删除了并且重新部署了新的 PD,但是 TiKV 还是使用旧的数据重启连到新的 PD 上,就会报这个错误。
这个地方说出了原因,但是没有解决方案啊。。。。@SUN-PingCAP
Hacker_G8a2iarY:
这个地方说出了原因,但是没有解决方案啊。。。。
可以在 tikv 的节点 deploy 目录下面找到 run_tikv.sh 脚本里面会有配置的 pd 配置,把它删除掉应该就可以了。
system
2022 年10 月 31 日 19:14
19
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。