leojiang
2020 年7 月 17 日 01:46
1
tidb版本3.0.11,生产环境。四台kv统一都是8核64Gssd500G
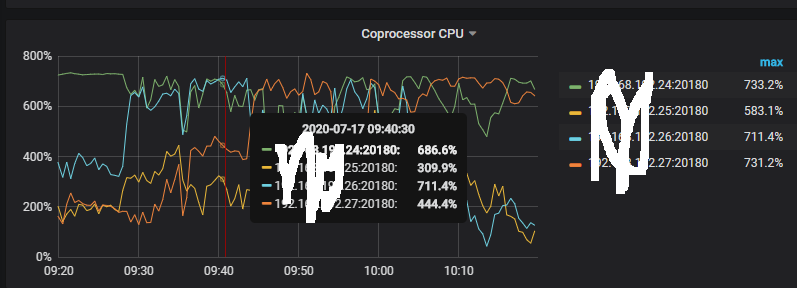
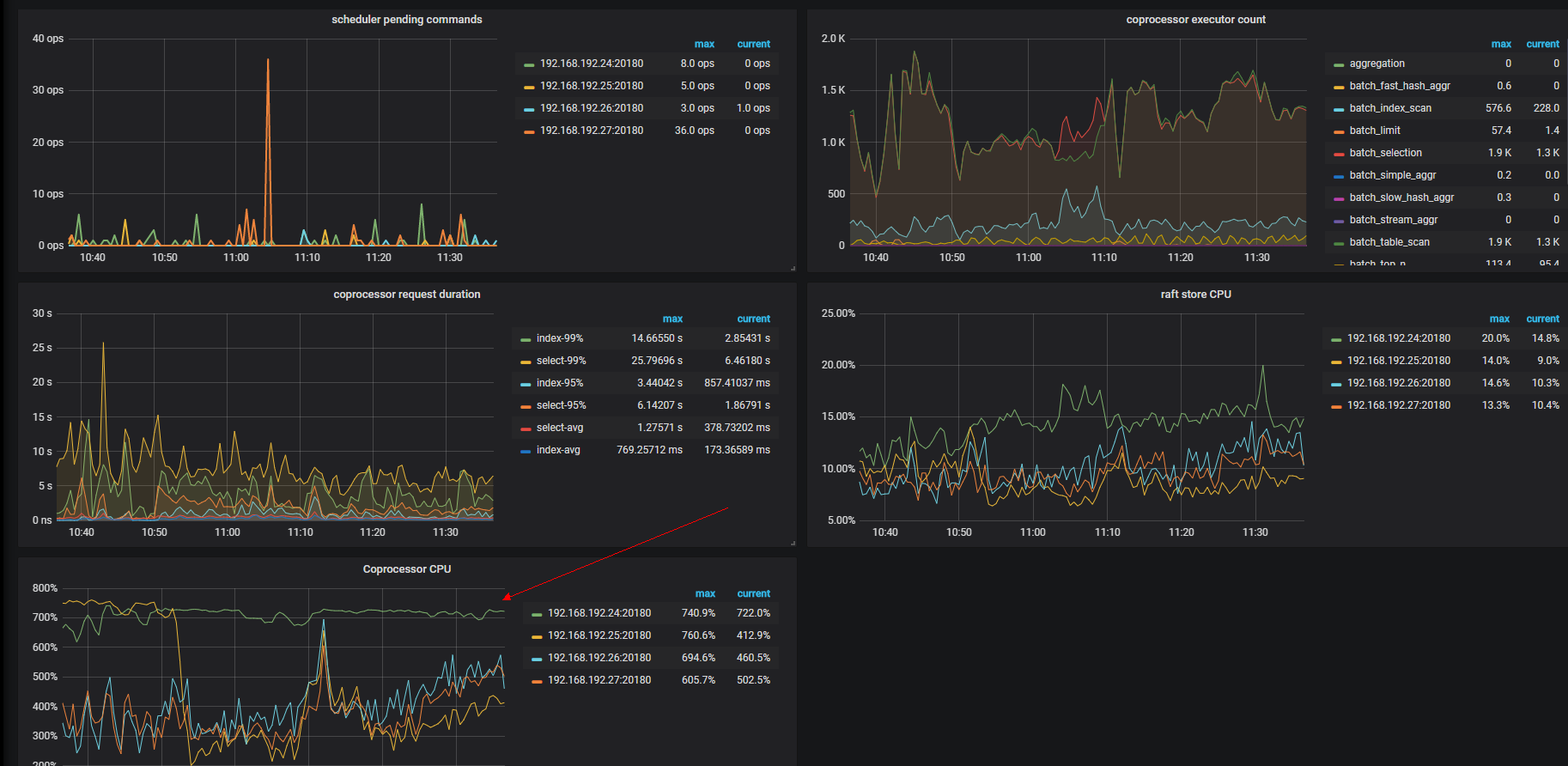
Coprocessor CPU发现使用达到了瓶颈.,region不均衡。
1、想问下着种情况是正常情况,还是……
这种情况该何如解决定位,请各位老师帮忙解惑下,感谢!
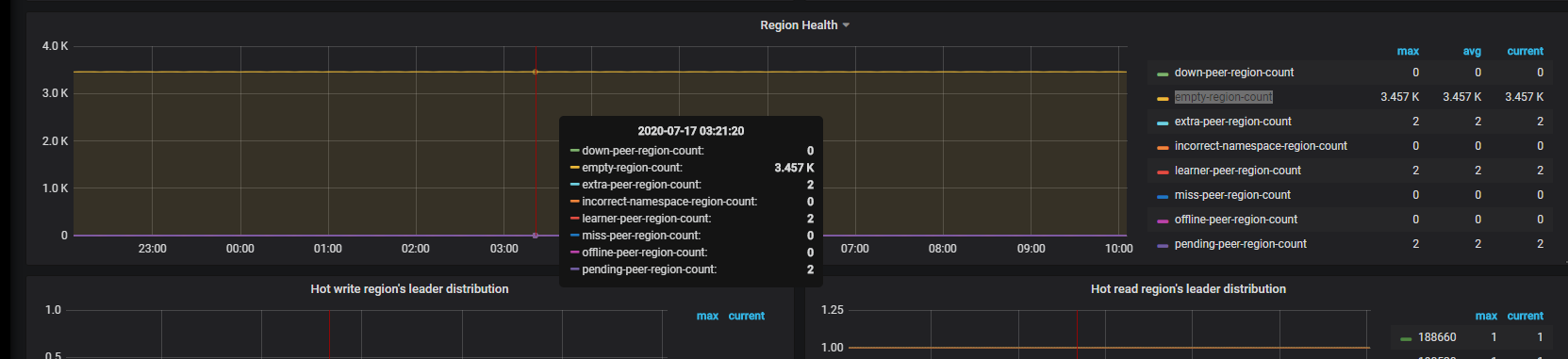
空region该如何消除,tidb自身并没有删除空region。
1、Coprocessor CPU 达到瓶颈是怎么判断的 ?能不能发一下对应的监控截图,可以发一下 TiKV-details 的 dashboard 下面的 Thread CPU 和 Coprocessor Details 的监控面板的监控,帮你确认一下。
通过 slow log 查询一下 cop 请求比较多的 sql ,尝试左右一些 SQL 优化;
如果 SQL 执行计划是预期的,可以考虑增加 coprocessor CPU 的并发线程数;
慢日志相关文档:https://docs.pingcap.com/zh/tidb/stable/identify-slow-queries#慢查询日志
leojiang
2020 年7 月 17 日 02:34
3
多谢老师。
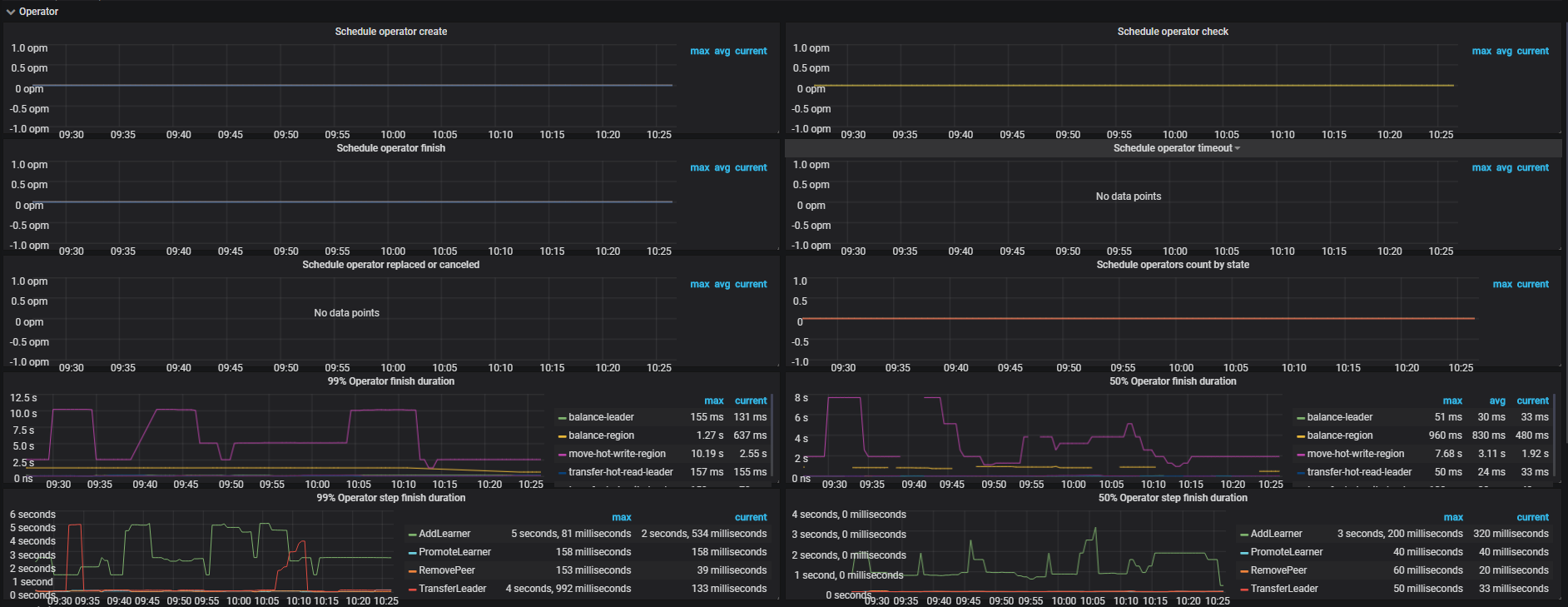
4、PD Dashboard 下面的 operator 和 balance 面板下面的监控,这个主要看哪些参数啊。
leojiang:
1、这个是这种cpu使用是正常现象么?
在 24、26 存在读请求热点,可以排查 tikv 的日志和 tidb 的 slow log 看看是不是慢查询;
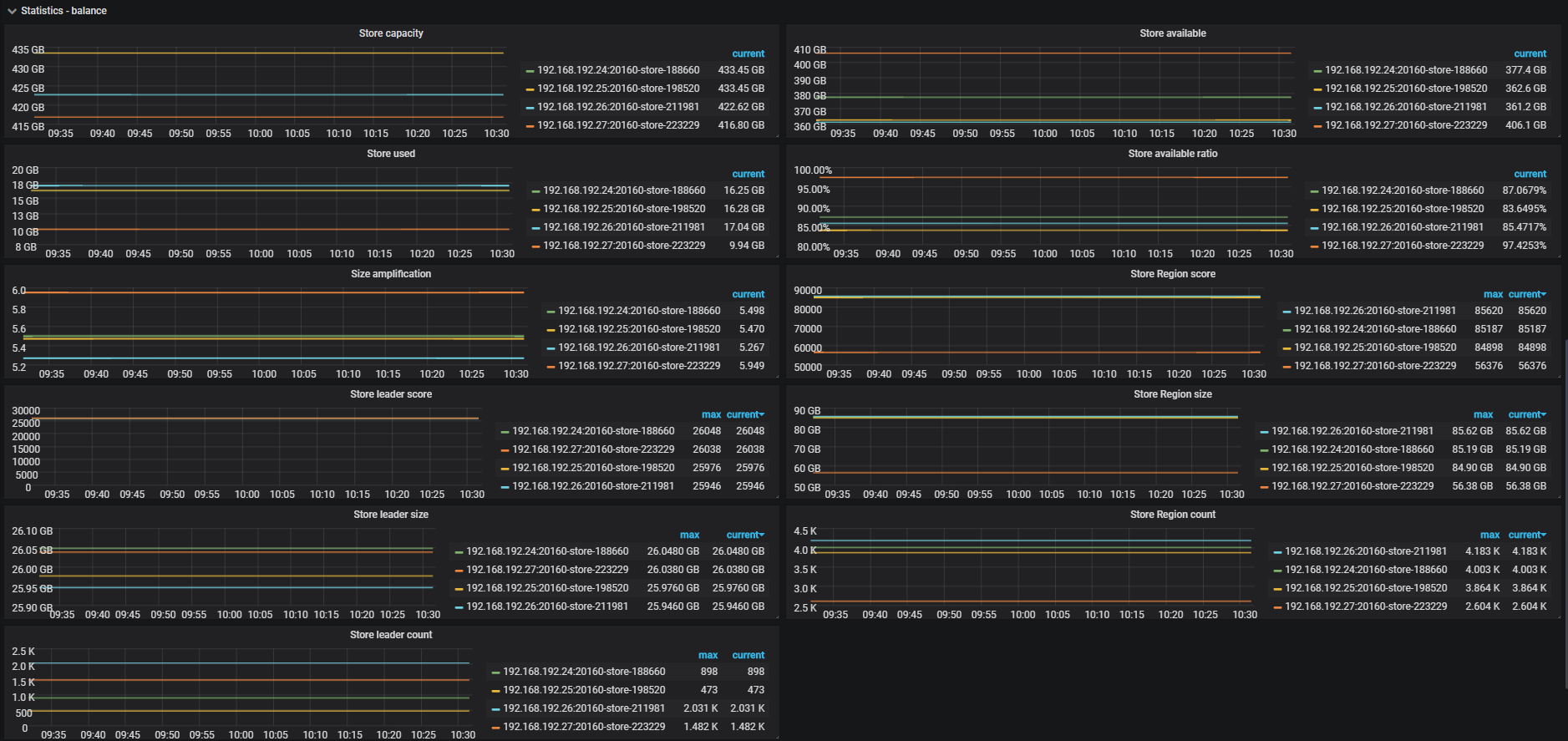
主要关注一下 store region/leader size 是否均衡,从监控看是均衡的,但是 leader/region count 是不均衡。能耐是存在 region size 差异,大 region 或者空 region 都会导致 count 不均衡。PD 在调度 leader score 的计算逻辑是基于 Region size, 所以可能出现 leader Region Size 分布均匀,但是 leader Region Count 相差很大的情况。
leojiang
2020 年7 月 23 日 03:37
5
有一台kv cpu使用不降,这种情况该怎么定位是什么原因产生的啊
QBin
2020 年7 月 23 日 05:44
6
system
2022 年10 月 31 日 19:12
7
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。