为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.1
- 【问题描述】:上游MySQL 通过DM 同步数据到下游TIDB ,在load 数据过程中整个tidb 集群响应特别慢
具体信息如下:
1.dm 相关信息:
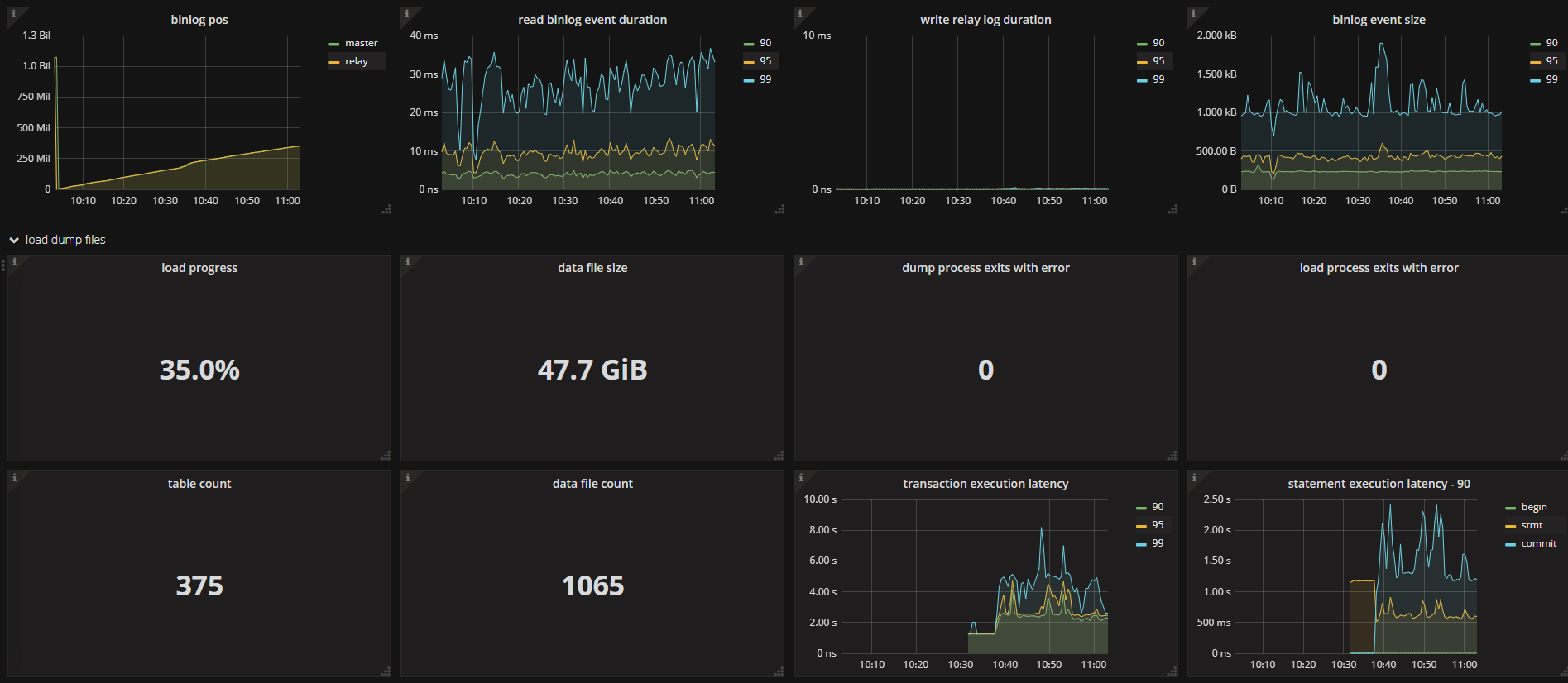
2.tidb 集群状态信息:
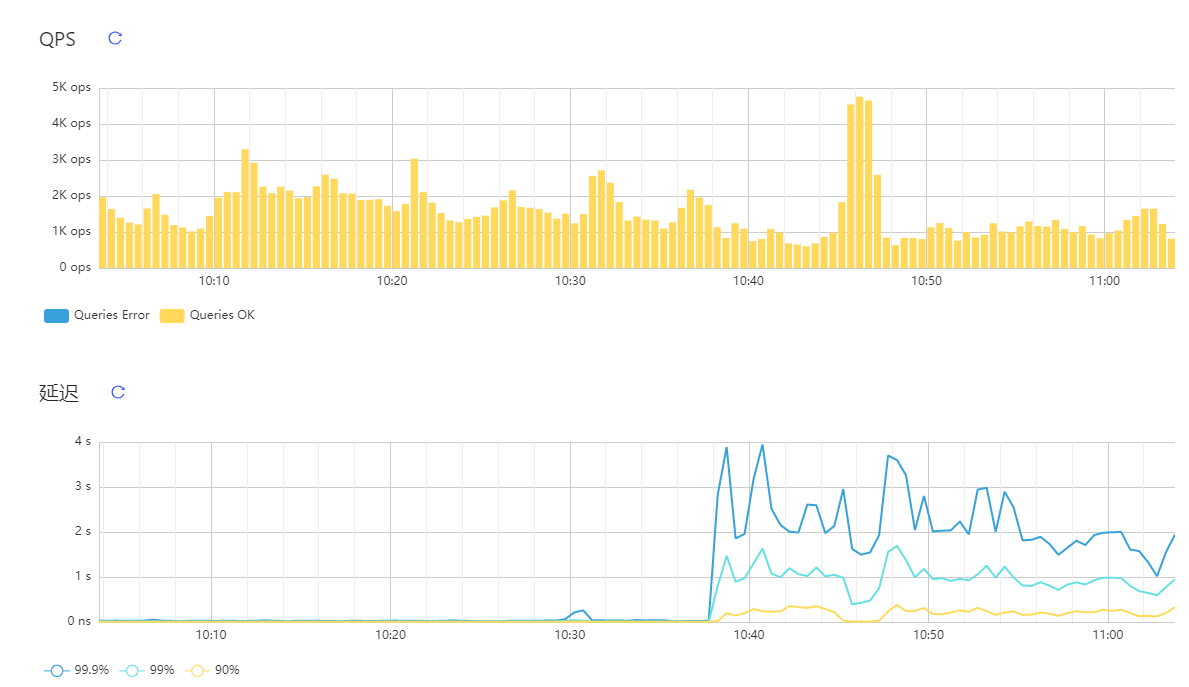
3.tikv-server 负载情况(40C 376G 配置) (两台物理机,每台3个tikv-server)

4.整体system
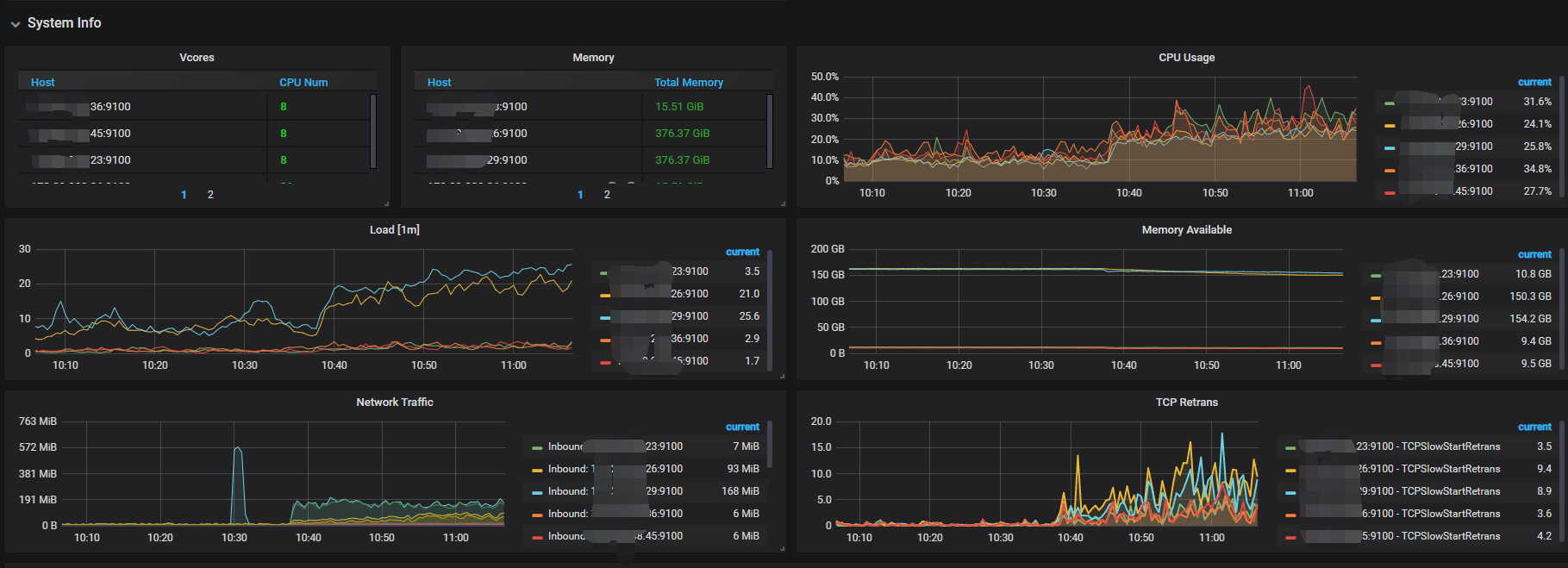
请问优化方法和方向? 多谢
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
2.tidb 集群状态信息:
3.tikv-server 负载情况(40C 376G 配置) (两台物理机,每台3个tikv-server)
4.整体system
请问优化方法和方向? 多谢
你好,
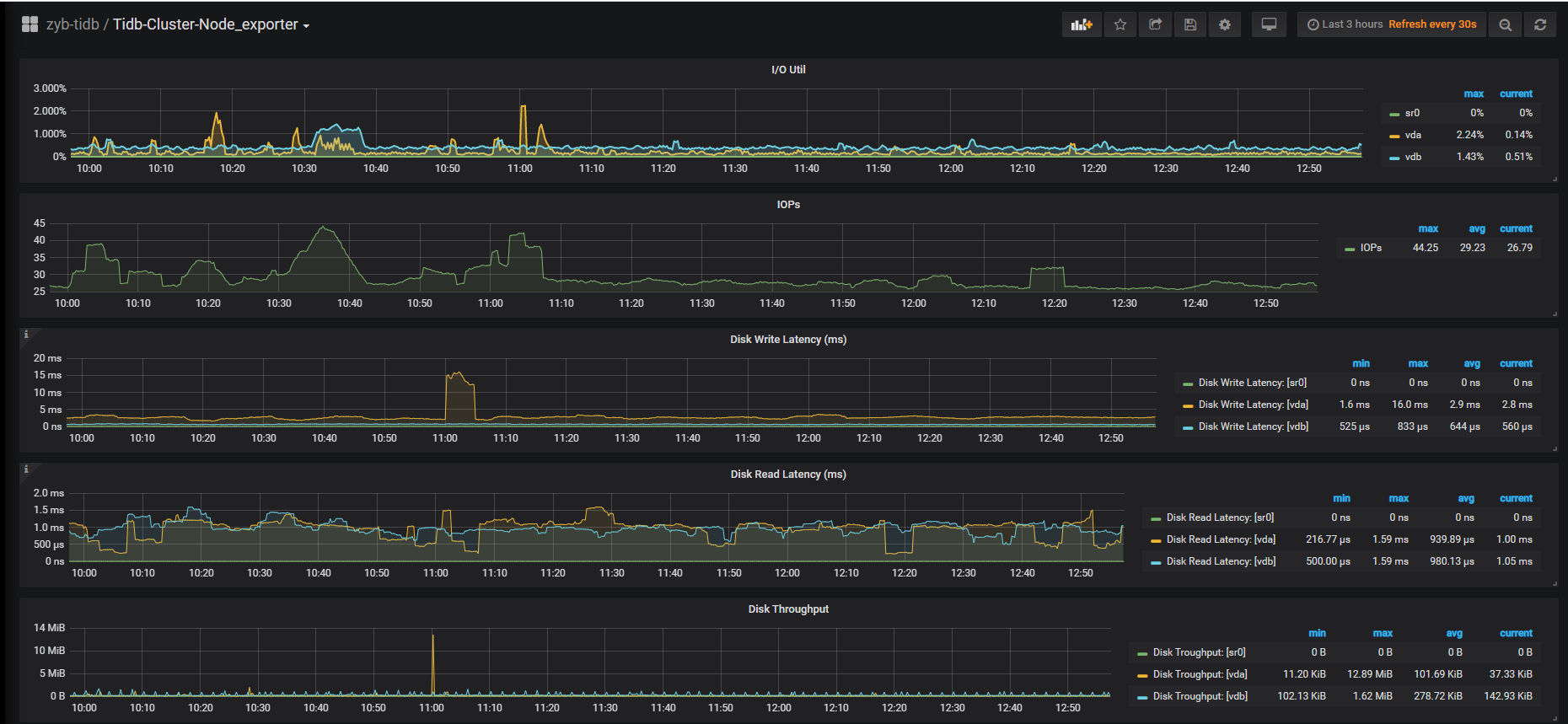
可以看下,grafana 监控中 node exporter - disk - io util / disk write latency
task 中 loader 部分的配置发出来看下
当前集群两台 tikv 的 load 较高,但是集群资源充足,现在数据 load 阶段,可以确认下是否为热点问题。
https://book.tidb.io/session4/chapter7/hotspot-resolved.html
目前通过调整loader 的pool-size=4 ,集群整体响应时间变好了(从秒级别降到毫秒级别)

从grafana 的troubleshooting 面板发现有部分的写热点。
此处未做详细分析,后续如果有进展会在此贴出来。
感谢官方人员。
![]()
还要继续麻烦一下,现在整个集群的状态还是不理想,当有一个worker在 load 数据并且速度不是很快,但是其他的worker 还是会有同步延迟的情况。之前排查是有个物理机有读写热点的tikv
有几个问题请给看下:
问题1::我想扩容两台 tikv 的机器,希望能加快一些load 的速度,不知是否可行。
已经从原来的两台物理机6个tikv ,又新增了两个物理机,分别新增了扩容了1个tikv 实例。现在是8个tikv
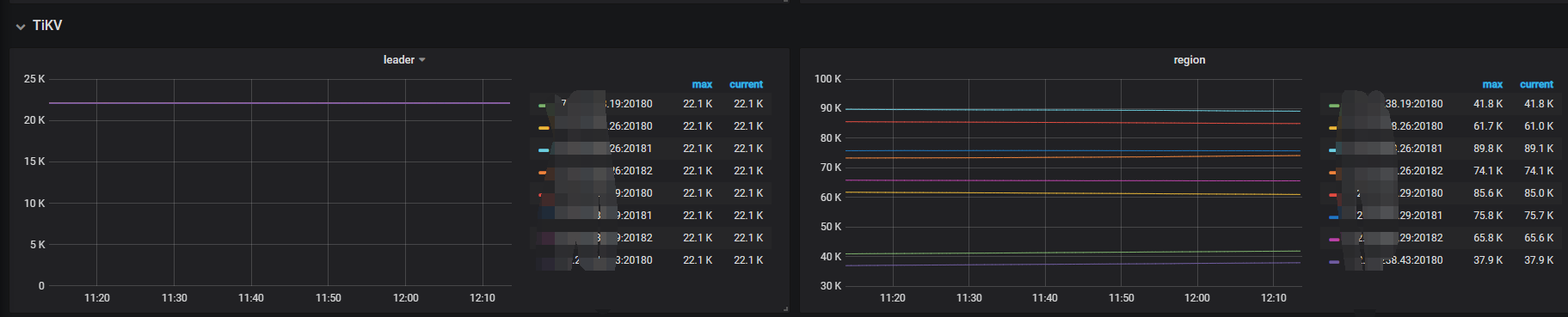
问题2:为什么扩容后tikv 的leader 已经均衡了,但是region 相差很多,现在从监控上来看238.26 那个物理机的tikv 的读写region热点还是比较多,不是可以自动调度么 ?
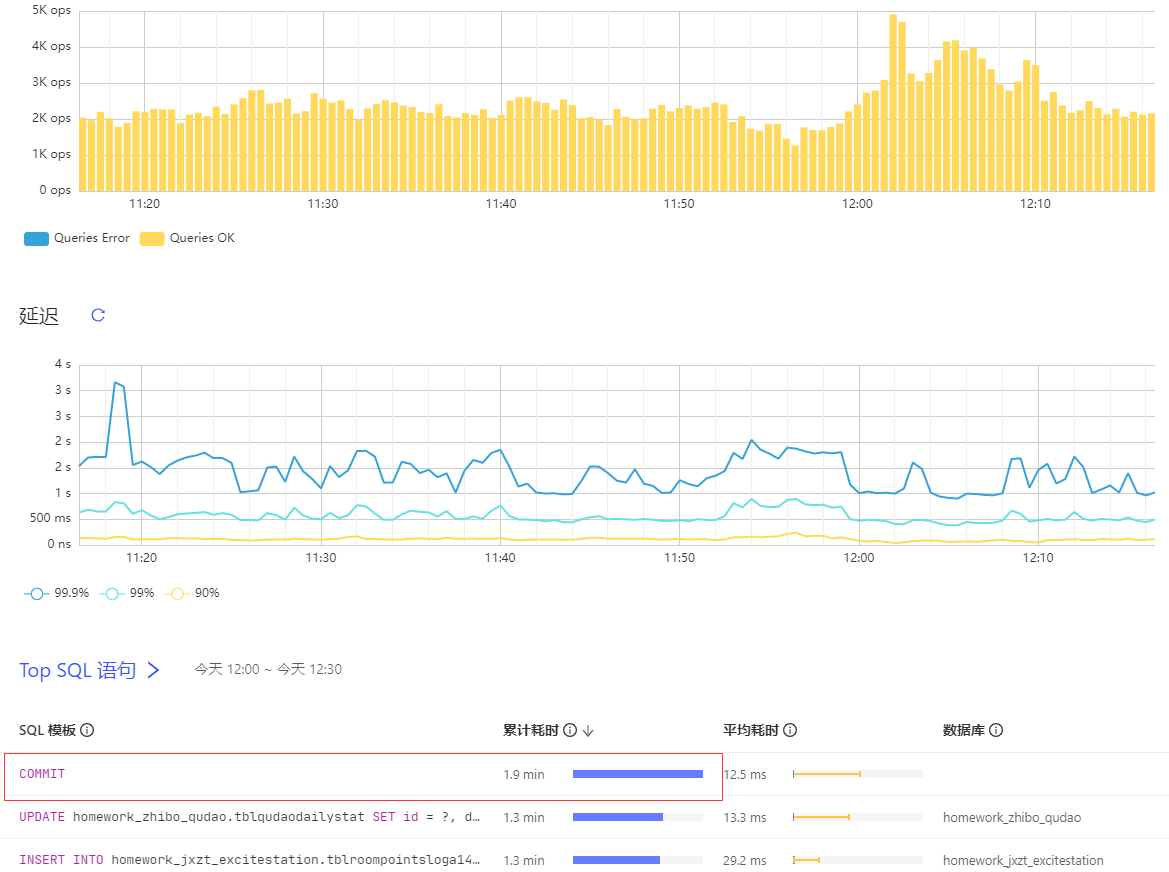
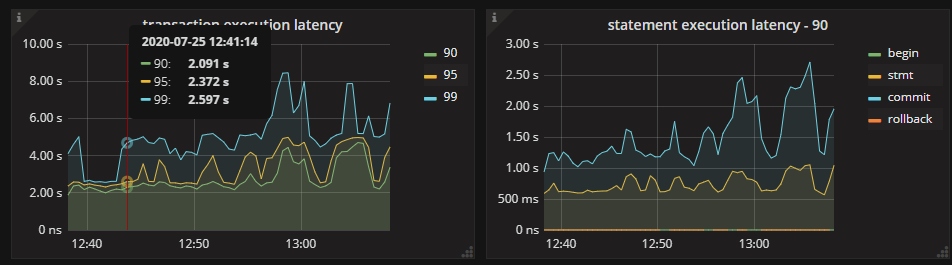
问题3:集群的延迟比较高,耗时挺多都在commit,这个能优化么,是否跟悲观事务模型有关?
下面是load 的配置文件
—
name: course_fudao # global unique
task-mode: all # full/incremental/all
is-sharding: false # whether multi dm-worker do one sharding job
meta-schema: “dm_meta” # meta schema in downstreaming database to store meta informaton of dm
remove-meta: false # remove meta from downstreaming database, now we delete checkpoint and online ddl information
enable-heartbeat: false # whether to enable heartbeat for calculating lag between master and syncer
case-sensitive: true
target-database:
host: “xxxxxxx238.34”
port: 4000
user: “dm_worker”
password: “xxxxxxx=”
session:
sql_mode: “NO_ENGINE_SUBSTITUTION”
source-id: "course_fudao"
black-white-list: "bw-rule-course_fudao"
mydumper-config-name: "global" # ref `mydumpers` config
syncer-config-name: "global" # ref `syncers` config
loader:
pool-size: 8
dir: "/data/dm_worker6/dumped_data"
black-white-list:
bw-rule-course_fudao:
do-dbs: [“homexxxxx”]
ignore-dbs: [“mysql”, “sys”]
mydumpers:
global:
mydumper-path: “/home/tidb/tidb-tools/bin/mydumper”
threads: 8
chunk-filesize: 64
skip-tz-utc: true
#extra-args: “–regex ‘.*’”
syncers:
global:
worker-count: 8
batch: 100
问题4:在load 数据过程中我stop-task 又start-task ,会看到监控上有报错信息,这个不会导致数据丢失或者异常吧?
我看你再其他的贴子解释是loader 会随机扫描sql 文件,所以有可能冲突。
问题1::我想扩容两台 tikv 的机器,希望能加快一些load 的速度,不知是否可行。
已经从原来的两台物理机6个tikv ,又新增了两个物理机,分别新增了扩容了1个tikv 实例。现在是8个tikv
→ 加快 loader 速度,loader 本身可以调大并发数来加快并发写入。如果并发数已经调大还是慢,需要看下 TiDB 集群,集群的写入瓶颈点在什么地方,比如热点、事务冲突或者节点负载高等都会影响,可以参考这里来分析:https://github.com/pingcap/tidb-map/blob/master/maps/performance-map.png
问题2:为什么扩容后tikv 的leader 已经均衡了,但是region 相差很多,现在从监控上来看238.26 那个物理机的tikv 的读写region热点还是比较多,不是可以自动调度么 ?
→ PD 对热点 region 会自动调度,一直还存在可能是热点调度不及时,可以手动对热点region 进行处理,参考 pd-ctl 部分,比如热点 region split 或者 transfer 等,参考:
https://docs.pingcap.com/zh/tidb/stable/pd-control#下载安装包
问题3:集群的延迟比较高,耗时挺多都在commit,这个能优化么,是否跟悲观事务模型有关?
→ commit 慢跟悲观事务关系不大,参考写流程来分析:https://github.com/pingcap/tidb-map/blob/master/maps/performance-map.png
问题4:在load 数据过程中我stop-task 又start-task ,会看到监控上有报错信息,这个不会导致数据丢失或者异常吧?
→ 不会有丢数据问题,具体可以看下 worker 的 log 信息。
问题1:如果我调高了loader 的并发数,但是如下监控的指标延迟比较高,是不是就说明没效果呢?我现在是8个并发,调整到16个后明显延迟增大了。
问题2:我扩容以后数据的分布并不均匀这个是什么情况 ? 最多80K region,最少的40K region 。需要手动调节pd 中的balance 相关参数么 ?
现在3个tikv 的那个节点机器CPU 使用的比较重,所以想如果数据均匀分布到其他新扩容的tikv ,集群的整体状态应该会好一些吧 ?如下是3tikv 的机器 :36C ,IO 没有压力目前
问题1:如果我调高了loader 的并发数,但是如下监控的指标延迟比较高,是不是就说明没效果呢?我现在是8个并发,调整到16个后明显延迟增大了。
->看起来瓶颈在 TiDB 层,可以按照之前发的排查思路,从 TiDB 侧排查下写操作的瓶颈
问题2:我扩容以后数据的分布并不均匀这个是什么情况 ? 最多80K region,最少的40K region 。需要手动调节pd 中的balance 相关参数么 ?
-> 算在当前集群的 region 平均大小,用总数据量/region 个数(leader *3),确认下是否有小 region 影响了调度
现在3个tikv 的那个节点机器CPU 使用的比较重,所以想如果数据均匀分布到其他新扩容的tikv ,集群的整体状态应该会好一些吧 ?如下是3tikv 的机器 :36C ,IO 没有压力目前
-> 看 CPU 使用情况,看着是有热点或者单个 KV 负载高,扩容节点 balance 数据之后,会集群性能会有提升。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。


{kind=link}