tikv 删除大量数据后几个小时后, 磁盘已经降下来了, scan 已删除的数据, 最后结果也为空,但是中间会扫描到大量已删除的数据,导致 scan 速度很慢, 这个有办法处理么
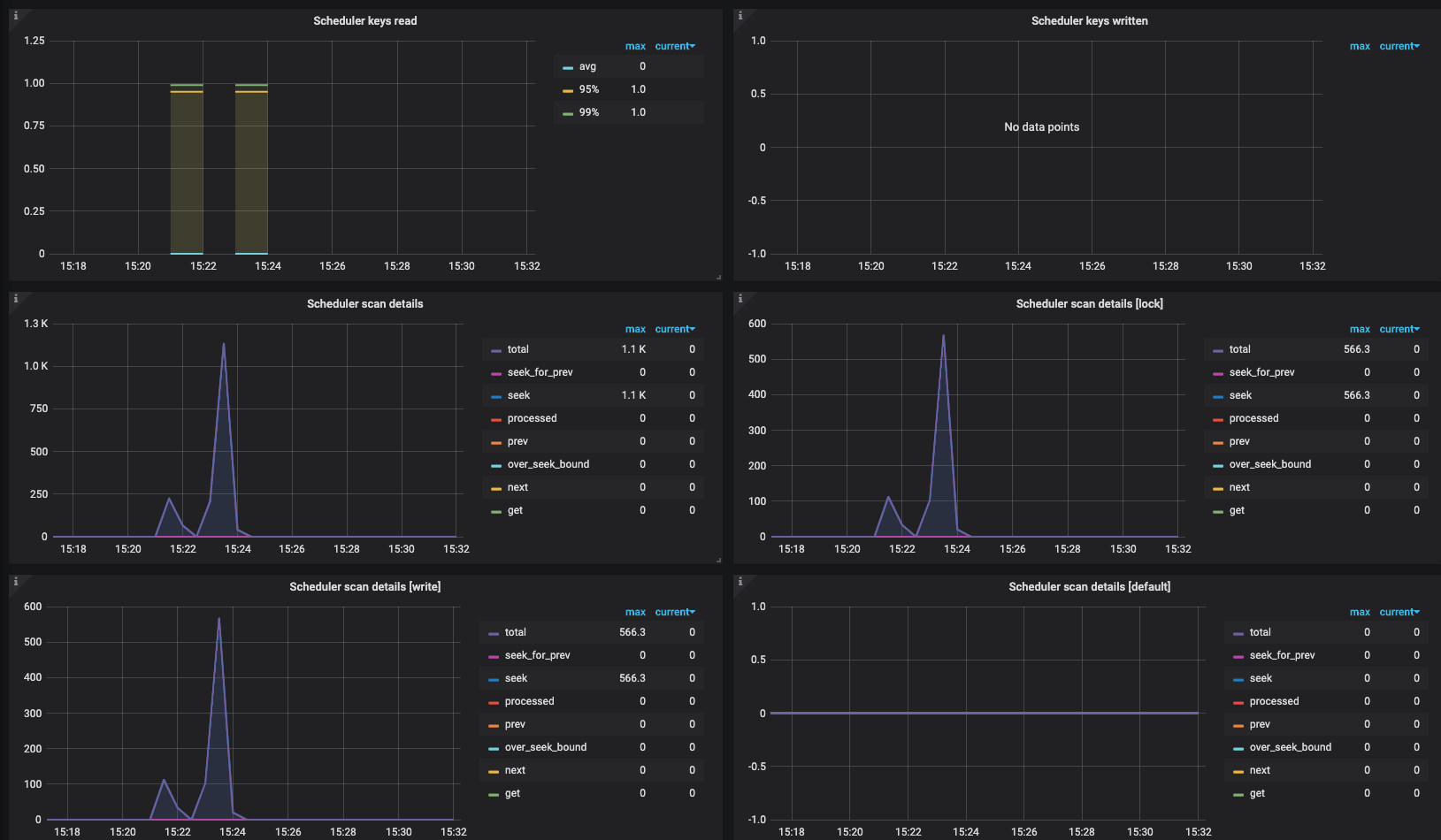
scan debug 日志如下:(图中只是很长 scan debug 日志中的一部分)
当前版本:
Release Version: 4.0.1
相关配置:
region-compact-check-interval 是默认值, 5min
region-compact-check-step 是默认值,100
是不是意味着每个 5 分钟会有 100 个 region 尝试 compact, 但是为何好几个小时后已删除的数据没有 compact 掉
直接使用的 tikv 没有使用 tidb, 但会有程序每隔 10 分钟发送新的 safepoint 给 tikv
用的是 raw kv 还是 txn kv?txn scan 意思是 txn kv 吗?
扫描到大量已删除数据是如何发现的?是从监控的 processed keys 吗?
- 如果用的是 txn kv。txn scan 后 delete 其实是写入 tombstone,不会删除掉数据,真正删除数据的是 GC。
- UnsafeDestroyRange 会直接删除数据,要注意这个不会通过 raft 同步,需要往所有 tikv 发送。
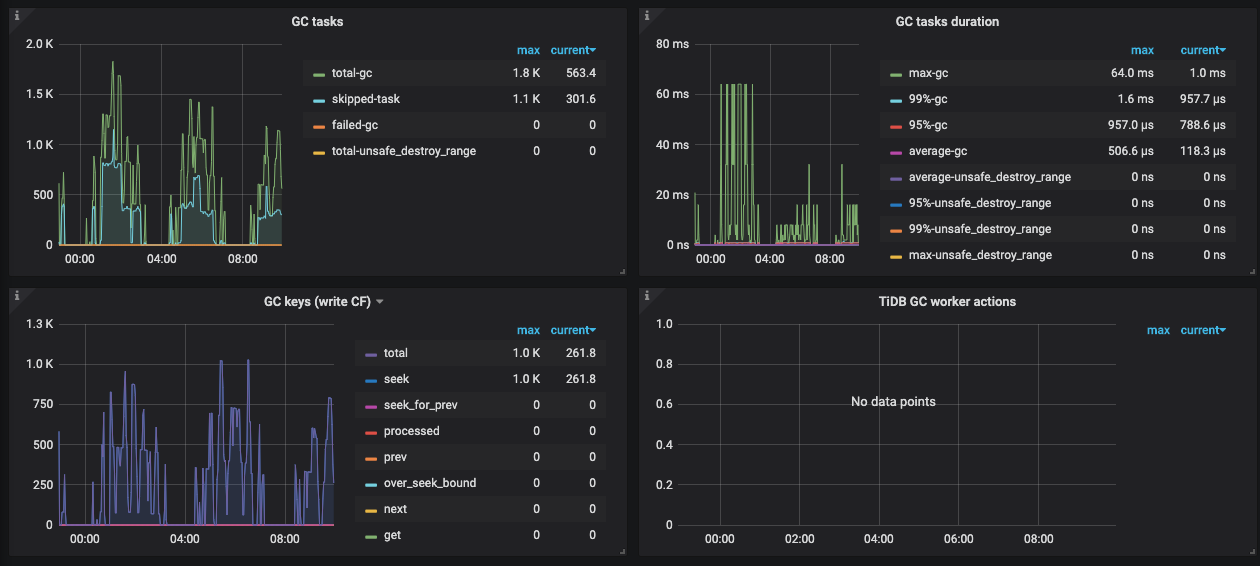
scan 慢的话怀疑是 gc 跟不上导致版本积累,麻烦看一下 gc 的进度。safepoint 一直在更新只能说明要 gc 之前的版本,tikv gc 不一定能跟上。。
用的 txn kv
扫描到大量已删除数据是如何发现的
因为 debug 日志一直开着,可以看到扫描已删除范围的时候, 一直出现上面的第一张图, 不停在 txn getData, 过了好几分钟后会 scan 完毕,返回空列表(因为已删除)
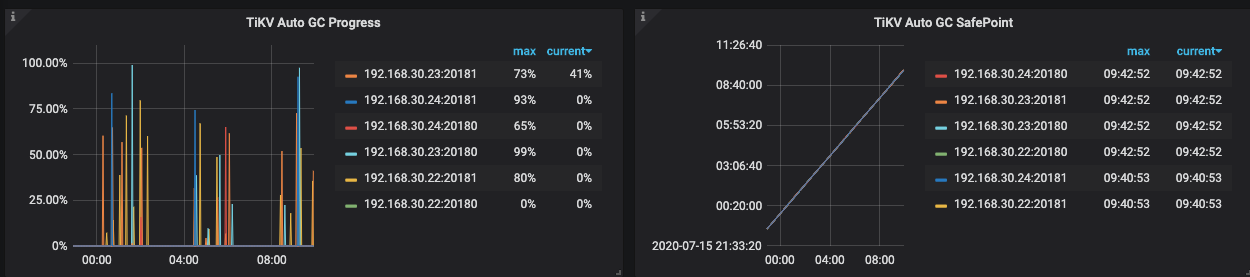
gc 的进度
进度是这个? process 的百分比是一阵阵显示(每一阵结束说明当前的 gc 已完成?), 删除操作的时间在截图之前(昨天)
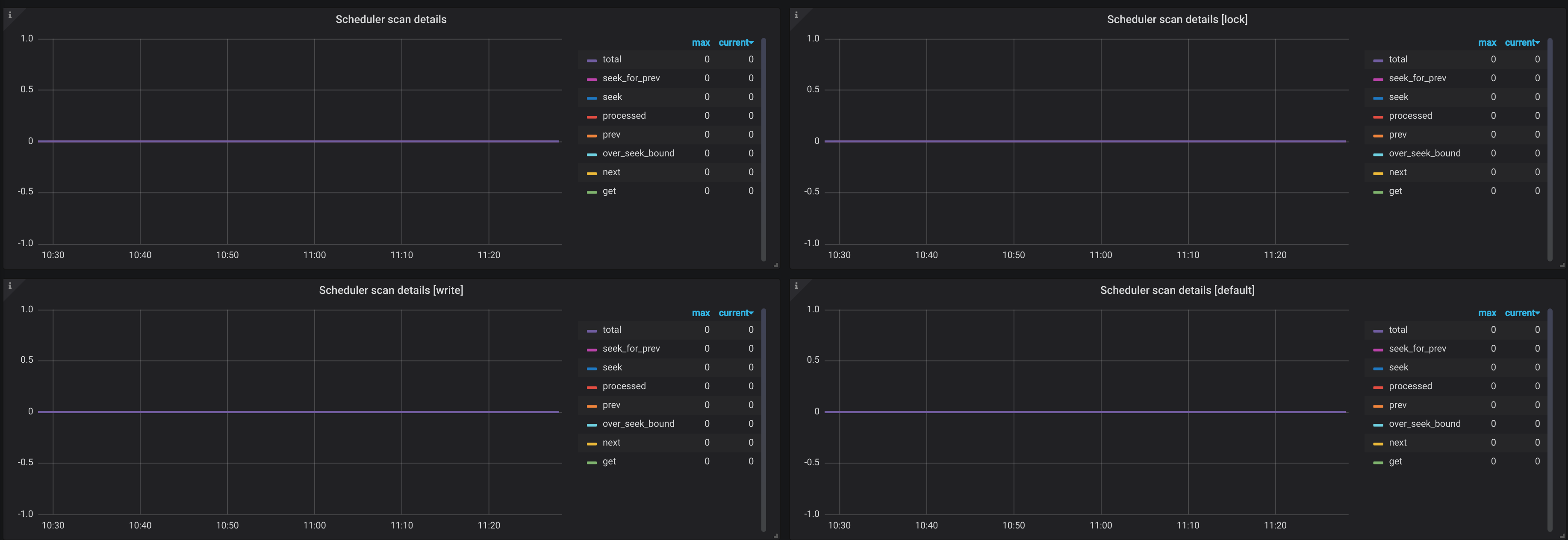
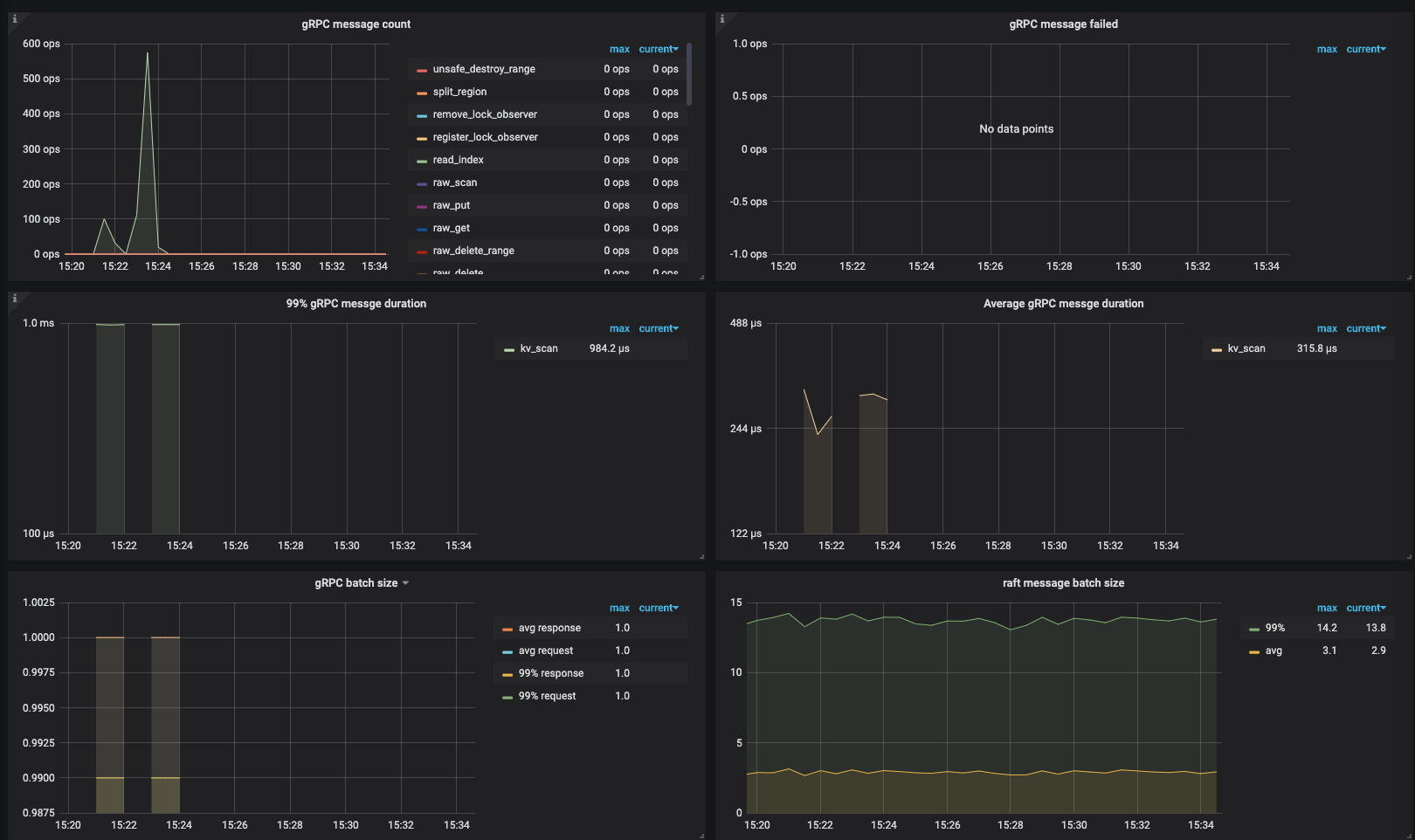
gc 应该是正常的,而且数据量不多。麻烦看一下 tikv grpc kv_scan 的延迟还有,scheduler scan 的监控:
huangnauh
(Huangnauh)
10
手动请求了两次昨天删除的范围,都是 1分钟以后再返回的
huangnauh
(Huangnauh)
12
有时候事务没有开启 follow-reader, 却会报 tikv reports RegionNotFound in follow-reader" 的错误, 这个也是因为批量删除导致的?
从 TiKV 处理延迟来看,速度很快。怀疑和客户端使用方式有关,看 log 好像是串行每次 scan 64个 key 的范围,可以用整个要 scan 的 key range 除以 64 算一下需要多少次 scan,每次 scan 就算 1ms 就能知道大致需要多长时间了。TiDB 内部这种大范围的 scan 都是并行发送给 TiKV 的,所以延迟只有 1 次 RTT。
huangnauh
(Huangnauh)
14
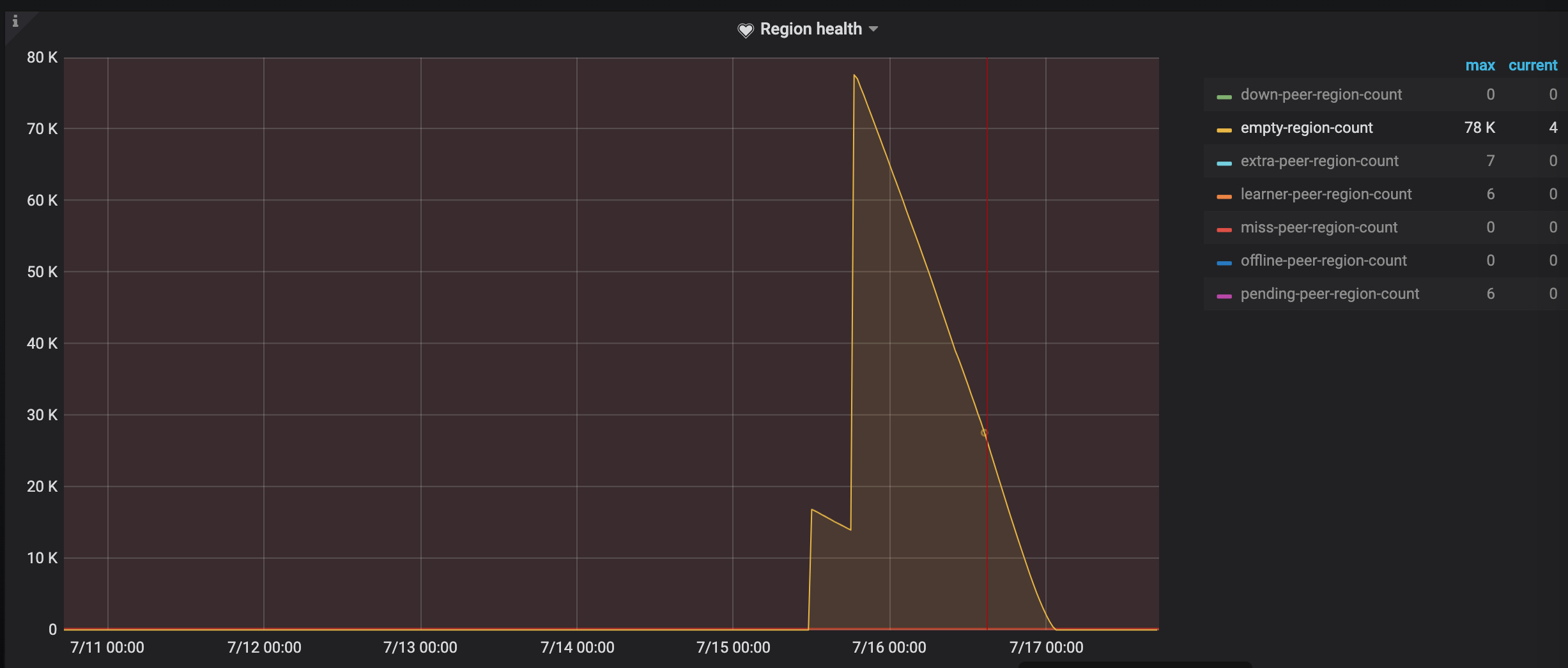
那照理说 scan 一个已经删除的范围,应该只要一次 scan 就可以了吧, 是因为 region 大量为空,但本身没有被删除,所以被清空的 region 还是需要 scan 一次来查询?
说明空 region 被清理的太慢了?
对的。空 region 要等 region merge 清理,可以查一下官网有加速 region merge 的参数。
system
(system)
关闭
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。