为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.1
- 【Operator 版本】:v1.1.1
- 【问题描述】:TiDB弹性扩容后,新扩容的TiKV不能正常进行服务(监控显示CPU利用率接近0),用pd-ctl store命令,发现TiKV已加入集群。用kubectl logs查看tikv和pd日志都有异常信息,具体如下:
PD日志:
[2020/07/14 02:40:24.604 +00:00] [ERROR] [grpclog.go:75] [“transport: Got too many pings from the client, closing the connection.”]
[2020/07/14 02:40:24.604 +00:00] [ERROR] [grpclog.go:75] [“transport: loopyWriter.run returning. Err: transport: Connection closing”]
TiKV日志:
[2020/07/14 07:35:39.987 +00:00] [WARN] [util.rs:194] [“updating PD client done”] [spend=3.685384ms]
[2020/07/14 07:35:39.988 +00:00] [WARN] [status_server.rs:614] [“failed to register addr to pd”] [body=“Ok(”\“component tikv address 0.0.0.0:20180 has already been registered\”\
")"] [“status code”=400]
[2020/07/14 07:35:39.988 +00:00] [WARN] [status_server.rs:614] [“failed to register addr to pd”] [body=“Ok(”\“component tikv address 0.0.0.0:20180 has already been registered\”\
")"] [“status code”=400]
[2020/07/14 07:35:39.989 +00:00] [WARN] [status_server.rs:614] [“failed to register addr to pd”] [body=“Ok(”\“component tikv address 0.0.0.0:20180 has already been registered\”\
")"] [“status code”=400]
[2020/07/14 07:35:39.989 +00:00] [WARN] [status_server.rs:614] [“failed to register addr to pd”] [body=“Ok(”\“component tikv address 0.0.0.0:20180 has already been registered\”\
")"] [“status code”=400]
[2020/07/14 07:35:39.989 +00:00] [WARN] [status_server.rs:624] [“failed to register addr to pd after 5 tries”]
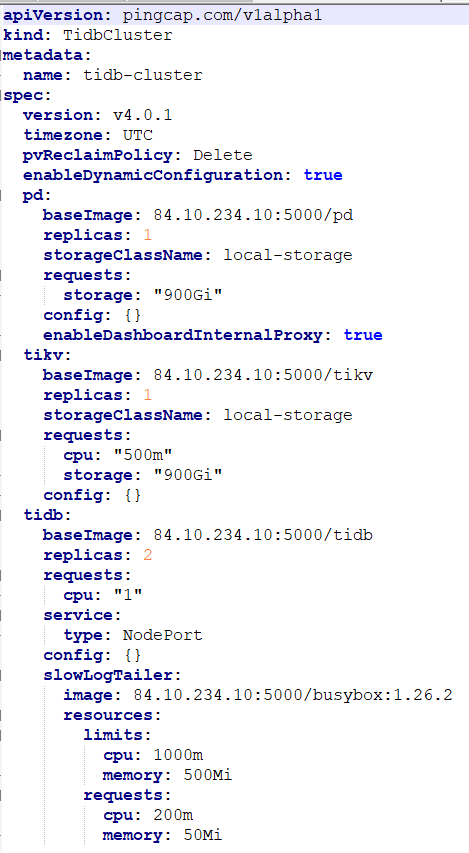
集群配置信息
麻烦配置下 TidbCluster 里面 spec. EnableDynamicConfiguration=true.
尝试配置了这个参数,之前TiKV日志中的报错不出现了,但是新扩容的TiKV还是无法正常工作,且PD日志的错误还存在。是我的配置有错误么?
配置文件如下:
麻烦再帮忙看看,谢谢
TiKV 无法工作具体是什么表现,能拿一下 pd 的 log 和扩容出来的 tikv Pod 的log 吗
麻烦再拿一下 tidb-controller-manager 的 log
从两个方面判定TiKV没有对外服务:
1.给集群进行压力测试,弹性扩容后tps没有明显变化
2.监控上显示新扩容TiKV的CPU Usage几乎为0,而旧TiKV的CPU Usage一直处于比较高的状态
PD的日志为:
pd0.log (2.7 MB)
新扩容两个TiKV的日志:
tikv1.log (23.0 KB) tikv2.log (23.0 KB)
tidb-controller-manager 的 log过大,不方便拿下来,且它输出的基本上是重复内容,下面放一部分输出频率最高的内容:
I0715 07:19:44.983906 1 stateful_set_control.go:81] TidbCluster: [tidb-test/tidb-cluster]'s StatefulSet: [tidb-test/tidb-cluster-pd] updated successfully
I0715 07:19:44.998136 1 stateful_set_control.go:81] TidbCluster: [tidb-test/tidb-cluster]'s StatefulSet: [tidb-test/tidb-cluster-tikv] updated successfully
I0715 07:19:45.287201 1 stateful_set_control.go:81] TidbCluster: [tidb-test/tidb-cluster]'s StatefulSet: [tidb-test/tidb-cluster-tidb] updated successfully
E0715 07:19:45.310827 1 tidbcluster_control.go:71] failed to update TidbCluster: [tidb-test/tidb-cluster], error: Operation cannot be fulfilled on tidbclusters.pingcap.com “tidb-cluster”: the object has
been modified; please apply your changes to the latest version and try again
I0715 07:19:45.337296 1 tidbcluster_control.go:68] TidbCluster: [tidb-test/tidb-cluster] updated successfully
这些都是上午的 log,最新的 log PD 还报错吗?
非常感谢,目前该特性处于实验阶段,欢迎进行测试。
目前 TiKV 的弹性适用于有热点的 workload, 看上面新的 tikv 是正常启动了的,新 TiKV 没有负载过来可能是因为没有热点调度过来。可以检查下 workload 是否比较随机,看 PD 监控的 Hot Region 下面是否有识别出热点。
每次弹性扩容的时候,PD都会报有关grpc的错误,最新的日志也一样
Wilsoncyx
(Wilsoncyx)
10
只有原生的TiKV包含Hot read Region,新的TiKV并没有这方面内容。
我注意到Pods Info监控里面会出现监控曲线不连续的情况,结合之前PD报的错误,是否可能与网络有关?
PD 的 gRPC 那个错误没有影响,4.0.2 已经修复了那个报错。 可以上传下扩容后 PD 的日志和和 pdctl>>store 的输出给我们分析下。
Wilsoncyx
(Wilsoncyx)
12
扩容后PD的日志如下:
pd.log (39.2 KB)
pd-ctl store的输出如下:
store.txt (3.1 KB)
请帮忙看看,谢谢
Wilsoncyx
(Wilsoncyx)
13
通过升级到4.0.2解决了新扩容的TiKV不服务的问题,但是目前已经停掉负载1小时左右,通过弹性伸缩得到的TiKV分别为offline状态和up状态,弹性扩容的TiKV无法正常进行缩容。
查看pd-ctl store发现TiKV的label与之前有所差别,输出如下:
store1.txt (3.0 KB)
查看tidb-controller-manager日志,发现有如下几个频繁输出的信息:
I0716 19:15:41.305244 1 tikv_scaler.go:116] tikv scale in: delete store 7014 for tikv tidb-test/tidb-cluster-tikv-2 successfully
I0716 19:15:41.329280 1 tidbcluster_control.go:68] TidbCluster: [tidb-test/tidb-cluster] updated successfully
I0716 19:15:41.329322 1 tidb_cluster_controller.go:297] TidbCluster: tidb-test/tidb-cluster, still need sync: TiKV tidb-test/tidb-cluster-tikv-2 store 7014 still in cluster, state: Up, requeuing
I0716 19:15:41.706483 1 stateful_set_control.go:93] : [tidb-test/tidb-cluster]'s StatefulSet: [tidb-test/tidb-cluster-pd] updated successfully
I0716 19:15:42.103646 1 tikv_scaler.go:91] scaling in tikv statefulset tidb-test/tidb-cluster-tikv, ordinal: 2 (replicas: 2, delete slots: [])
I0716 19:15:42.128062 1 tidbcluster_control.go:68] TidbCluster: [tidb-test/tidb-cluster] updated successfully
I0716 19:15:42.128088 1 tidb_cluster_controller.go:297] TidbCluster: tidb-test/tidb-cluster, still need sync: TiKV tidb-test/tidb-cluster-tikv-2 store 7014 still in cluster, state: Offline, requeuing
I0716 19:15:42.505800 1 stateful_set_control.go:93] : [tidb-test/tidb-cluster]'s StatefulSet: [tidb-test/tidb-cluster-pd] updated successfully
I0716 19:15:42.903998 1 tikv_scaler.go:91] scaling in tikv statefulset tidb-test/tidb-cluster-tikv, ordinal: 2 (replicas: 2, delete slots: [])
I0716 19:15:42.930333 1 tidbcluster_control.go:68] TidbCluster: [tidb-test/tidb-cluster] updated successfully
请帮忙看看这个问题,谢谢
Wilsoncyx
(Wilsoncyx)
15
按照你的方法试了一下,min replicas设为3,max repilicas设为4,它出现的错误和之前几乎一样,tidb-controller-manager日志还是报我之前发的错误,只不过是副本数不一样了,第四个副本在无压力的情况下只是进入了offline状态,不能正常被删除。
所以不能正常删除TiKV应该不是副本数量的问题,有没有可能是TiKV的一个BUG?
等了多长时间了?数据量多大,offline 代表正在下线
Wilsoncyx
(Wilsoncyx)
17
已经过了5天,PV监控显示每个TiKV只用了2G的存储,而且从测试到现在无任何数据的增删。正常情况下,TiKV的迁移应该早都做完了,不应该还在offline状态吧
嗯,是,麻烦用 pd-ctl 看下当前 stores 的状态
Wilsoncyx
(Wilsoncyx)
19
pd-ctl store输出如下:
store2.txt (2.8 KB)
store只剩三个TiKV,但是现在有4个TiKV的Pod在跑,有点奇怪