为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:4.0.1
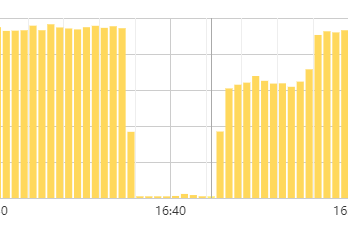
- 【问题描述】:dm_worker 有异常日志,监控的qps 出现抖动,但是query-status 未看到异常信息

若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
在 tidb 服务器上执行 dmesg | grep -i oom,看下 tidb-server 是否在改时间点出现重启。
tidb-server 未重启过,好像是LB 的连接问题,我再排查 下看看
OK,希望得到反馈
好像是在创建索引的时候报错了:如下—
[“execute statement failed”] [task=test]
[unit=“binlog replication”]
[query=“CREATE INDEX k_7 ON test_sbtest.sbtest7 (k)”] [argument="[]"]
[error=“invalid connection”]
[“rollback failed”] [task=test] [unit=“binlog replication”]
[query=“CREATE INDEX k_7 ON test_sbtest.sbtest7 (k)”] [argument="[]"] [error=“invalid connection”]
[“execute statements failed after retry”] [task=test] [unit=“binlog replication”]
创建索引时就是链接,可以看下 qps 掉底时间点的 tidb log 是否存在 welcom 字样日志
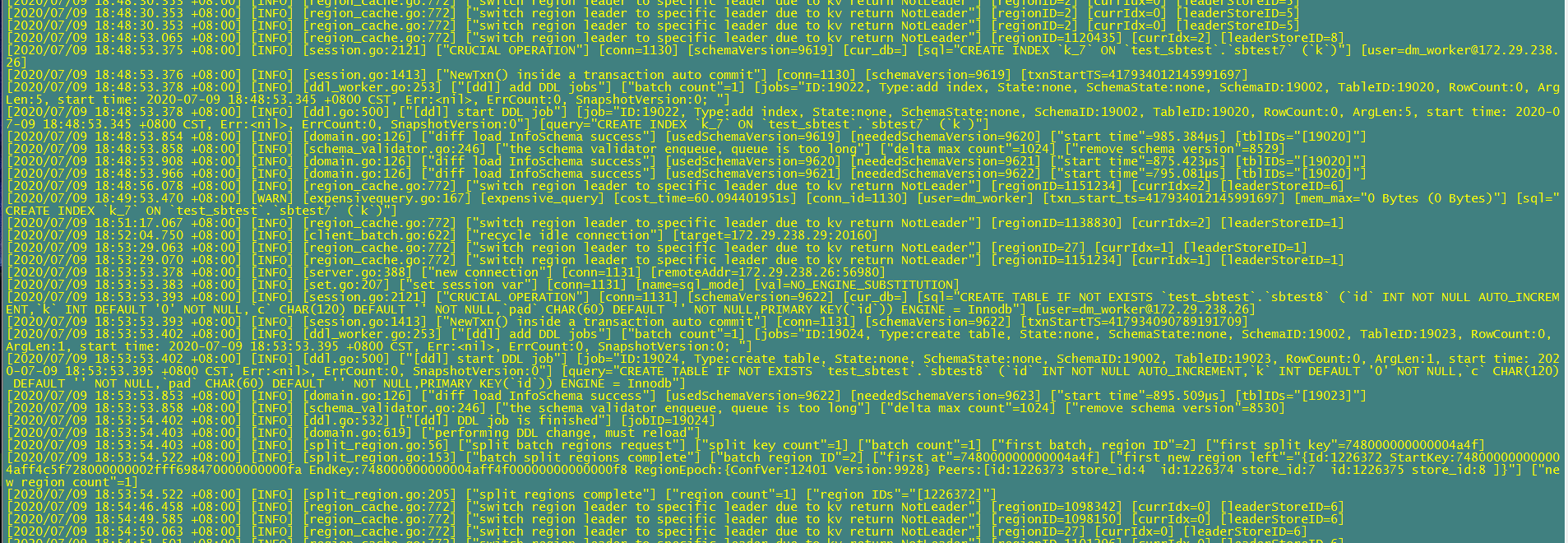
你好,如下是tidb-server 当时加索引时的日志:
[2020/07/09 18:48:53.375 +08:00] [INFO] [session.go:2121] [“CRUCIAL OPERATION”] [conn=1130] [schemaVersion=9619] [cur_db=] [sql=“CREATE INDEX k_7 ON test_sbtest.sbtest7 (k)”] [user=dm_worker@172.29.238.26]
[2020/07/09 18:48:53.376 +08:00] [INFO] [session.go:1413] [“NewTxn() inside a transaction auto commit”] [conn=1130] [schemaVersion=9619] [txnStartTS=417934012145991697]
[2020/07/09 18:48:53.378 +08:00] [INFO] [ddl_worker.go:253] ["[ddl] add DDL jobs"] [“batch count”=1] [jobs=“ID:19022, Type:add index, State:none, SchemaState:none, SchemaID:19002, TableID:19020, RowCount:0, ArgLen:5, start time: 2020-07-09 18:48:53.345 +0800 CST, Err:, ErrCount:0, SnapshotVersion:0; “]
[2020/07/09 18:48:53.378 +08:00] [INFO] [ddl.go:500] [”[ddl] start DDL job”] [job=“ID:19022, Type:add index, State:none, SchemaState:none, SchemaID:19002, TableID:19020, RowCount:0, ArgLen:5, start time: 2020-07-09 18:48:53.345 +0800 CST, Err:, ErrCount:0, SnapshotVersion:0”] [query=“CREATE INDEX k_7 ON test_sbtest.sbtest7 (k)”]
[2020/07/09 18:48:53.854 +08:00] [INFO] [domain.go:126] [“diff load InfoSchema success”] [usedSchemaVersion=9619] [neededSchemaVersion=9620] [“start time”=985.384µs] [tblIDs="[19020]"]
[2020/07/09 18:48:53.858 +08:00] [INFO] [schema_validator.go:246] [“the schema validator enqueue, queue is too long”] [“delta max count”=1024] [“remove schema version”=8529]
[2020/07/09 18:48:53.908 +08:00] [INFO] [domain.go:126] [“diff load InfoSchema success”] [usedSchemaVersion=9620] [neededSchemaVersion=9621] [“start time”=875.423µs] [tblIDs="[19020]"]
[2020/07/09 18:48:53.966 +08:00] [INFO] [domain.go:126] [“diff load InfoSchema success”] [usedSchemaVersion=9621] [neededSchemaVersion=9622] [“start time”=795.081µs] [tblIDs="[19020]"]
[2020/07/09 18:48:56.078 +08:00] [INFO] [region_cache.go:772] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=1151234] [currIdx=2] [leaderStoreID=6]
[2020/07/09 18:49:53.470 +08:00] [WARN] [expensivequery.go:167] [expensive_query] [cost_time=60.094401951s] [conn_id=1130] [user=dm_worker] [txn_start_ts=417934012145991697] [mem_max=“0 Bytes (0 Bytes)”] [sql=“CREATE INDEX k_7 ON test_sbtest.sbtest7 (k)”]
[2020/07/09 18:51:17.067 +08:00] [INFO] [region_cache.go:772] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=1138830] [currIdx=2] [leaderStoreID=1]
[2020/07/09 18:52:04.750 +08:00] [INFO] [client_batch.go:622] [“recycle idle connection”] [target=172.29.238.29:20160]
[2020/07/09 18:53:29.063 +08:00] [INFO] [region_cache.go:772] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=27] [currIdx=1] [leaderStoreID=1]
[2020/07/09 18:53:29.070 +08:00] [INFO] [region_cache.go:772] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=1151234] [currIdx=1] [leaderStoreID=1]
[2020/07/09 18:53:53.378 +08:00] [INFO] [server.go:388] [“new connection”] [conn=1131] [remoteAddr=172.29.238.26:56980]
[2020/07/09 18:53:53.383 +08:00] [INFO] [set.go:207] [“set session var”] [conn=1131] [name=sql_mode] [val=NO_ENGINE_SUBSTITUTION]
dm woker log 文本,完整上传一下吧,和一楼截图中 4000 端口对应 ip 的 tidb log
一楼的那个地址是LB 的地址。
我重新梳理下信息:
我在上游的MySQL 中用sysbench 创建了8张表同步到tidb。表结构为
Create Table: CREATE TABLE sbtest7 (
id int(11) NOT NULL AUTO_INCREMENT,
k int(11) NOT NULL DEFAULT 0,
c char(120) NOT NULL DEFAULT ‘’,
pad char(60) NOT NULL DEFAULT ‘’,
PRIMARY KEY (id),
KEY k_7 (k)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin AUTO_INCREMENT=50070010
报错时间是在每次数据同步完加索引的时候发生的:
1.dm-worker-stderr.log 对应的信息如下:(26是worker ip,34是LB的地址)
18:53:53 packets.go:36: read tcp xxxx.238.26:45878->xxxxx.238.34:4000: i/o timeout
此时还有其他的worker 在同步其他实例,并未发生如上的情况。
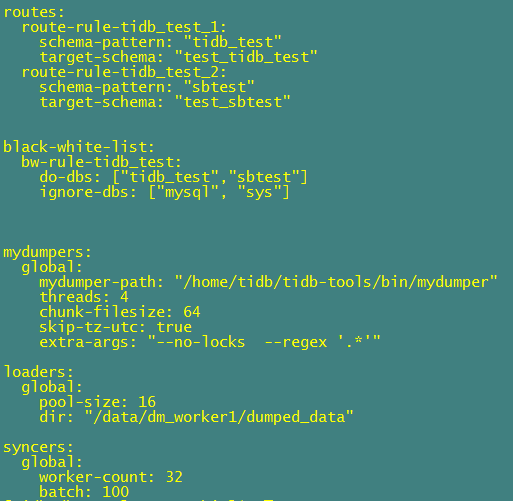
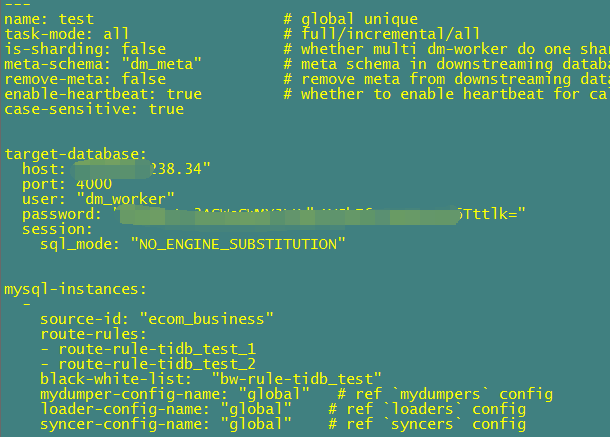
1.task 配置如下:未使用shard 模式
我又测试一下手动加索引:CREATE INDEX k_2 ON test_sbtest.sbtest1 (k);
tidb-server 日志如下,未看到之前的报错情况:
task 重新 stop start 之后可以继续同步吗?
还是说这个 invalid connect 是同步的时候必然发生的现象?无法恢复
我只是发现了报错,几乎在每次sbtest 表数据同步完, 然后最后加索引的时候都会发生这个错误,但是task 好像没有终止,还是继续运行的。表上的索引也是创建成功了。
我再重新启动新的 worker 然后再搞几个表试试看吧。
task 继续运行,是因为 dm 遇到部分错误是会进行重试的
嗯,可以再测试看下,如果可以稳定复现这个问题的话,麻烦再反馈一下