该sql没进入慢sql。当时的指标看起来除了其中一台TiDB报错暂时未发现问题。
[2020/07/13 09:29:07.278 +08:00] [WARN] [conn.go:684] [“dispatch error”] [conn=2773633] [connInfo="id:2773633, addr:10.204.9.202:52650 status:1, collation:utf8_general_ci, user:uic
“] [command=Query] [status=“inTxn:1, autocommit:0”] [sql=“update uic_user\
SET extend_attr = ‘{“defaultPaymentType”:“1”,“boxShowModeTipTimes”:“1”,“courier_growth_
score”:“7854”,“courier_feature_rank”:“1”,“courier_effective_time”:“20200808”,“boxShowMode”:“2”,“real_name_flag”:“1”,“courier_growth_rank”:“4”,“showBoxTypeMo
dePage”:“1”,“boxShowModeGray”:“2”}’,\
\
\
\
\
\
\
\
\
update_
time = ‘2020-07-13 09:30:13.436’ \
where id = 246881774439772160”] [err=”[tikv:9006]GC life time is shorter than transaction duration, transaction starts at 2020-07-13 09:1
5:03.041 +0800 CST, GC safe point is 2020-07-13 09:19:31.441 +0800 CST
监控时间与报错时间不相符哦~
暂时建议调大 gc life time 并观察会不会再次出现该问题
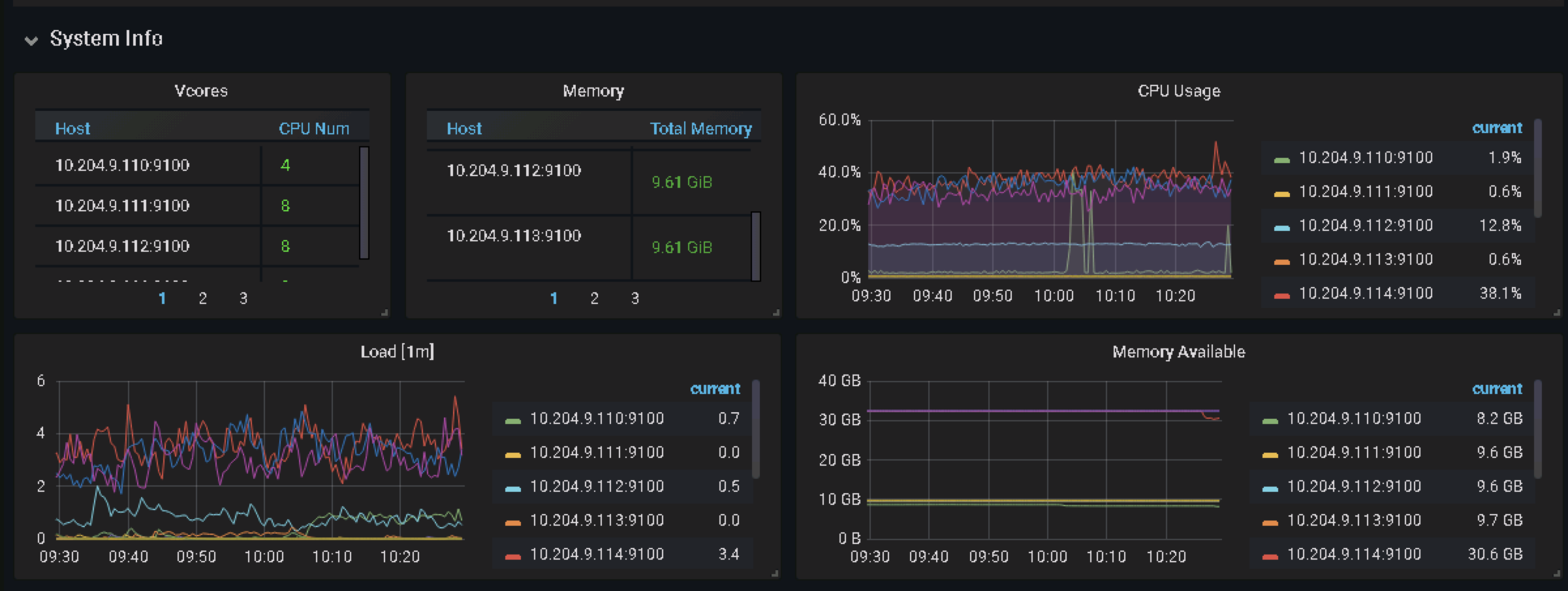
9:29是这是报错的时间,9:30是业务生成该sql执行的时间。图表中报错也有个9:30在报错。时间是相符的,只是不太明白为什么会拿到9:15的事物时间。这里是有问题的,而且3台TiDB中只有一台会这样。
报错显示 7-13 9:15 获取的 start ts ,当前监控时 7-14 日的监控
[err="[tikv:9006]GC life time is shorter than transaction duration, transaction starts at 2020-07-13 09:1
5:03.041 +0800 CST, GC safe point is 2020-07-13 09:19:31.441 +0800 CST\
可以看下这个 tidb 的时区与其他服务器是否相符。
相符,检查过PD ,TiDB ,TiKV的所有时间,都是通过NTP去获取服务器的时间。至少我查的时候是一样的
暂时建议调大 gc life time 先观察下是否还会出现该问题吧
调大肯定会减少,这个不能解决问题吧。毕竟目前还是测试集群。
调大 gc 时解决此问题的办法,gc 是 tidb 垃圾回收机制,如果不回收会有太多的版本信息需要存储,反之如果回收的过快,会产生类似的问题,调整 gc 也是运维优化 tidb 的手段之一。
https://docs.pingcap.com/zh/tidb/stable/garbage-collection-overview
刚看了下报错,这个错拿开始时间会到50分钟之前,而且还是一批的,就算把gc life time调大了,甚至会拿错时间,这个挺可怕的。比如12:20select拿到的却是11:40的数据,这个在逻辑上是直接错了的,目前正在翻代码看下能不能找出来为啥会拿错时间的问题。
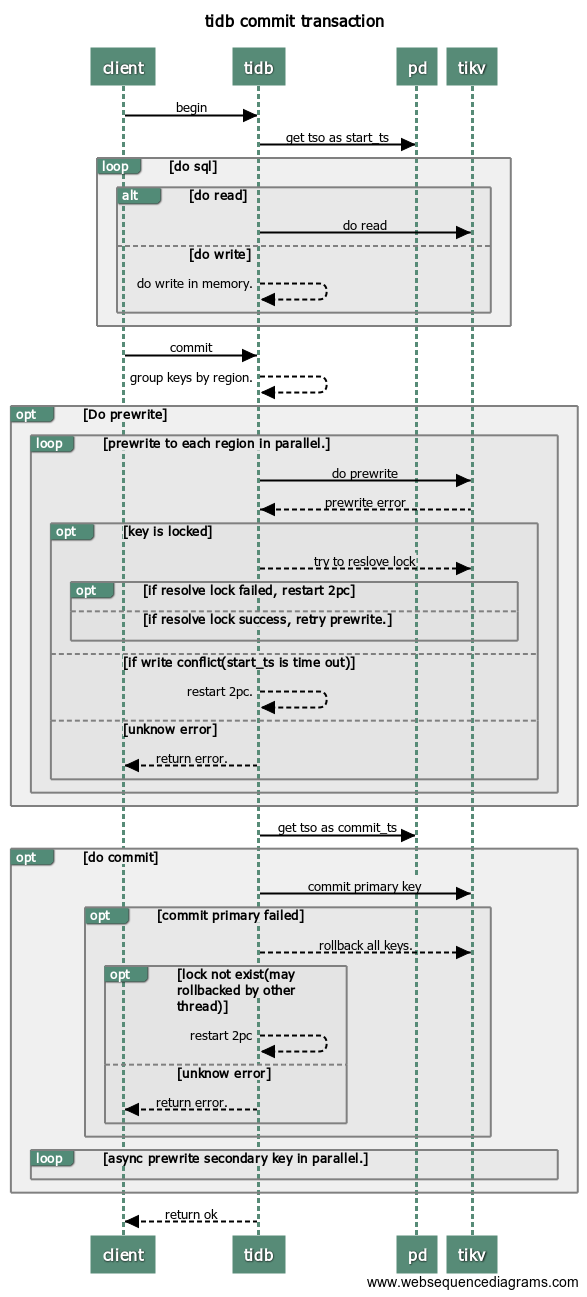
 对的呀,就是这个意思,这里是12点20生成sql结果拿到了的start ts是11点40的,而且12点到12点25之间有6万多条sql都拿的start ts是11点40的
对的呀,就是这个意思,这里是12点20生成sql结果拿到了的start ts是11点40的,而且12点到12点25之间有6万多条sql都拿的start ts是11点40的
如果这些 sql 在一个 begin (事务中),start ts 是相同的,sql 执行时间超过了 gc 的时间,就会被清理掉。可以根据业务看下将 gc life time 设置为 72h?48h?
gc时间是 10分钟,这个是录制出来的流量,不是真实的事物。有可能是begin了之后。commit的语句被分发到其他TiDB了。
所有的报错都是,
status=“inTxn:1, autocommit:0”
理论上autocommit是1。
这是第一条报错
[2020/07/14 12:00:15.448 +08:00] [err="[tikv:9006]GC life time is shorter than transaction duration, transaction starts at 2020-07-14 11:40:24.741 +0800 CST, GC safe point is 2020-07-14 11:49:31.441 +0800 CST
这是最后一条报错
[2020/07/14 12:25:01.101 +08:00] [err="[tikv:9006]GC life time is shorter than transaction duration, transaction starts at 2020-07-14 11:40:24.741 +0800 CST, GC safe point is 2020-07-14 12:09:31.441 +0800 CST
根据日志确认了就是因为begin了之后没关闭导致的。
检查了下,猜想基本准确,同一个连接id为2777161中最早2020-07-14 11:40:24.741附近被改成了状态为inTxn:1, autocommit:0的,之后到11:50还有 一条,而该连接11:50~12:00之间是没有请求进来,所以不存在拿不到数据而报错的。到12点钟进来了之后就发生了。
12:25分最后一条报错之后,该连接在日志中消失,有可能是该连接关闭或者接收到了commit。又能正常执行了
回放时,事务是不是出现变化的,他也不会将一个事务拆分成多个
对的,网卡录制,只能还原独立的语句,无法还原带事务的语句
确定吗,begin commit 语句是怎么回放的?
现象是,中间隔了层nginx,我在检查是不是断开之后nginx复用链接了
可以检查下,但是对于线上业务 begin commit 属于同一个事务,在 tidb 中,是有一致性保障的,回归到本贴的问题。还是需要修改 gc 来解决
嗯,不会有这么大的事物的,也不允许跑这么大事物。这个应该是意外来的
已私信,判断可能是网卡流量回放问题,当前问题需要调整 tikv_gc_life_time 来解决,感谢反馈,如有新的问题欢迎开新帖继续讨论。