环境说明
版本:TIDBv4.0.0
环境说明:3TiDB+3TiPD+3TiKV+1TiFlash
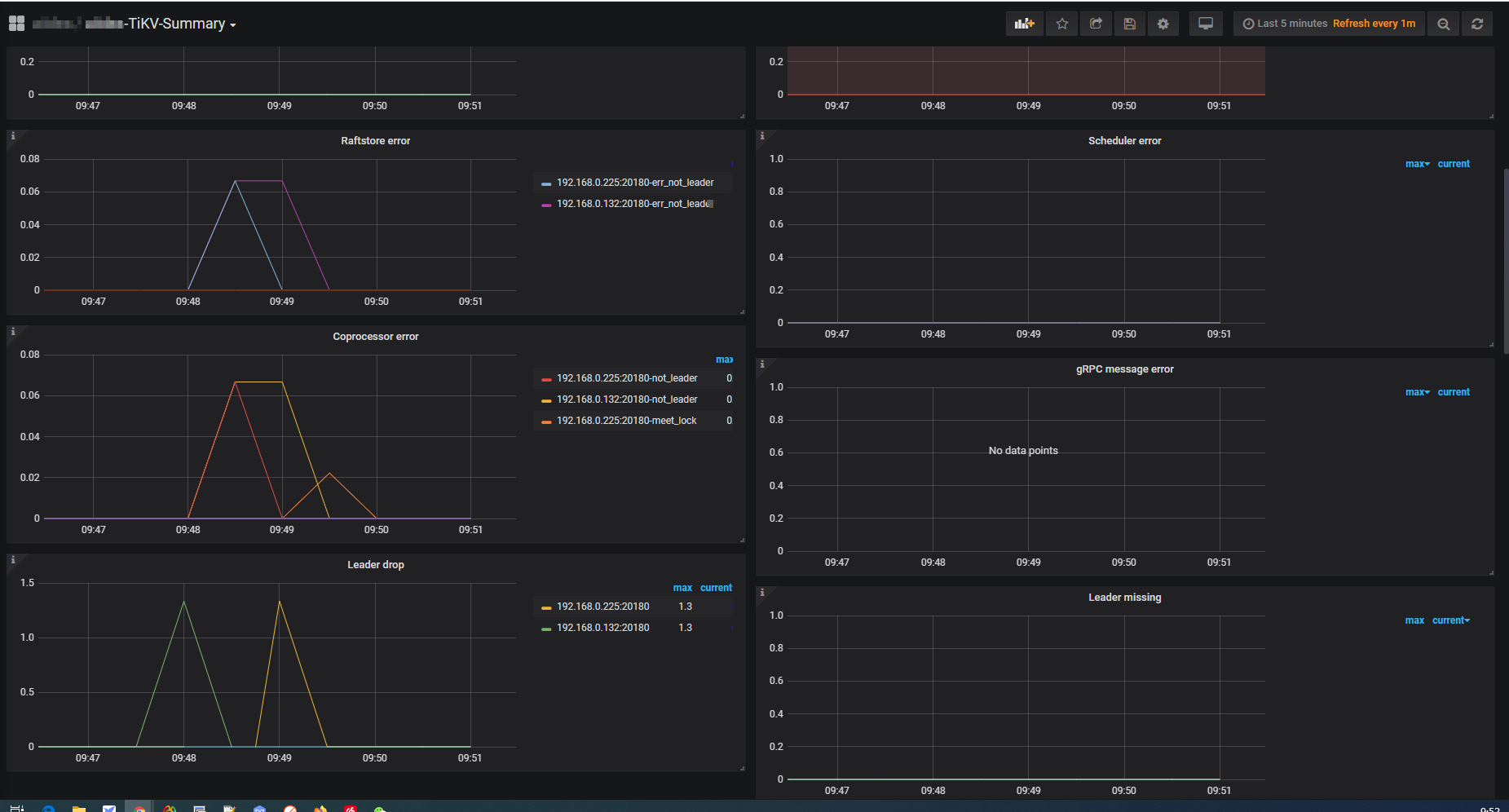
故障说明:tikv三个节点均报以下错误
-------------------------------日志开始-----------------------------------------
[2020/07/09 09:21:02.016 +08:00] [WARN] [endpoint.rs:527] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 28, leader may Some(id: 29 store_id: 2)" not_leader { region_id: 28 leader { id: 29 store_id: 2 } }”]
[2020/07/09 09:21:02.128 +08:00] [WARN] [endpoint.rs:527] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 28, leader may Some(id: 29 store_id: 2)" not_leader { region_id: 28 leader { id: 29 store_id: 2 } }”]
[2020/07/09 09:21:02.136 +08:00] [WARN] [endpoint.rs:527] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 28, leader may Some(id: 29 store_id: 2)" not_leader { region_id: 28 leader { id: 29 store_id: 2 } }”]
---------------------日志结束-----------------------------------------------
监控报错截图如下: