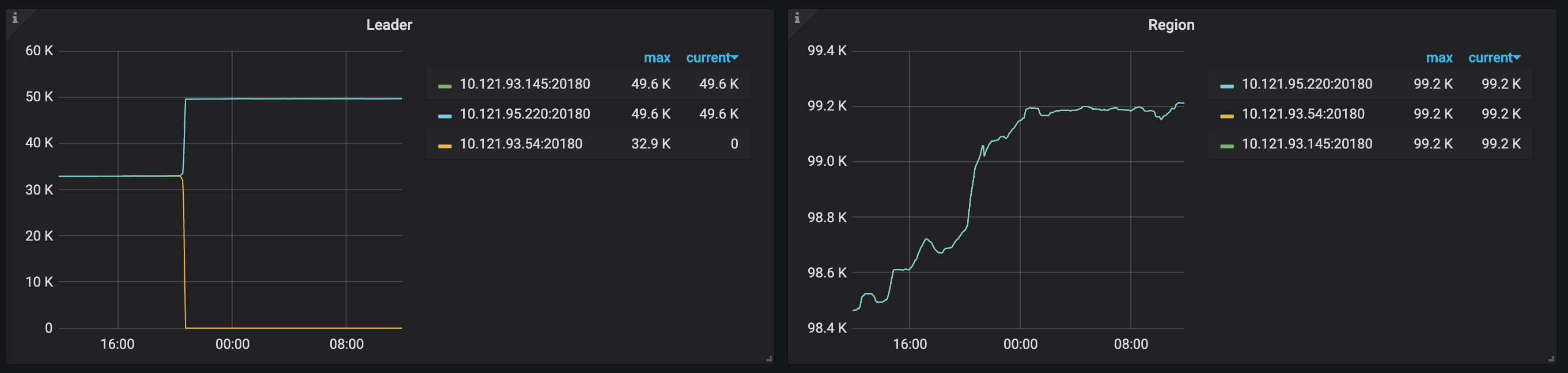
7月6号晚上8点db节点使用有问题,内存异常自动重启,然后似乎leader balance就有点问题了
今天尝试重启所有kv节点和pd节点,似乎认为10.121.93.54节点就不应该有leader一样
7月6号晚上8点db节点使用有问题,内存异常自动重启,然后似乎leader balance就有点问题了
今天尝试重启所有kv节点和pd节点,似乎认为10.121.93.54节点就不应该有leader一样
忘记说了,版本号是4.0 GA
你好,提供下以下信息便于盘查
tiup ctl pd -u http://pdip:pdport config show all
tiup ctl pd -u http://pdip:pdport scheduler show
» config show all
{
“client-urls”: “http://10.155.111.236:2379”,
“peer-urls”: “http://10.155.111.236:2380”,
“advertise-client-urls”: “http://10.155.111.236:2379”,
“advertise-peer-urls”: “http://10.155.111.236:2380”,
“name”: “pd_10.155.111.236”,
“data-dir”: “/home/tidb/deploy/data.pd”,
“force-new-cluster”: false,
“enable-grpc-gateway”: true,
“initial-cluster”: “pd_10.155.111.139=http://10.155.111.139:2380,pd_52-136=http://10.155.111.136:2380,pd_10.155.111.236=http://10.155.111.236:2380”,
“initial-cluster-state”: “new”,
“join”: “”,
“lease”: 3,
“log”: {
“level”: “info”,
“format”: “text”,
“disable-timestamp”: false,
“file”: {
“filename”: “/home/tidb/deploy/log/pd.log”,
“max-size”: 300,
“max-days”: 0,
“max-backups”: 0
},
“development”: false,
“disable-caller”: false,
“disable-stacktrace”: false,
“disable-error-verbose”: true,
“sampling”: null
},
“tso-save-interval”: “3s”,
“metric”: {
“job”: “pd_10.155.111.236”,
“address”: “”,
“interval”: “15s”
},
“schedule”: {
“max-snapshot-count”: 3,
“max-pending-peer-count”: 16,
“max-merge-region-size”: 20,
“max-merge-region-keys”: 200000,
“split-merge-interval”: “1h0m0s”,
“enable-one-way-merge”: “false”,
“enable-cross-table-merge”: “false”,
“patrol-region-interval”: “100ms”,
“max-store-down-time”: “1h0m0s”,
“leader-schedule-limit”: 1,
“leader-schedule-policy”: “count”,
“region-schedule-limit”: 1,
“replica-schedule-limit”: 1,
“merge-schedule-limit”: 8,
“hot-region-schedule-limit”: 2,
“hot-region-cache-hits-threshold”: 3,
“store-limit”: {
“20847613”: {
“add-peer”: 15,
“remove-peer”: 15
},
“20847615”: {
“add-peer”: 15,
“remove-peer”: 15
},
“22290001”: {
“add-peer”: 15,
“remove-peer”: 15
}
},
“tolerant-size-ratio”: 5,
“low-space-ratio”: 0.8,
“high-space-ratio”: 0.6,
“scheduler-max-waiting-operator”: 3,
“enable-remove-down-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“enable-make-up-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-location-replacement”: “true”,
“enable-debug-metrics”: “false”,
“schedulers-v2”: [
{
“type”: “balance-region”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “balance-leader”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “hot-region”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “label”,
“args”: null,
“disable”: false,
“args-payload”: “”
}
],
“schedulers-payload”: {
“balance-hot-region-scheduler”: “null”,
“balance-leader-scheduler”: “{“name”:“balance-leader-scheduler”,“ranges”:[{“start-key”:”",“end-key”:""}]}",
“balance-region-scheduler”: “{“name”:“balance-region-scheduler”,“ranges”:[{“start-key”:”",“end-key”:""}]}",
“label-scheduler”: “{“name”:“label-scheduler”,“ranges”:[{“start-key”:”",“end-key”:""}]}"
},
“store-limit-mode”: “manual”
},
“replication”: {
“max-replicas”: 3,
“location-labels”: “”,
“strictly-match-label”: “false”,
“enable-placement-rules”: “false”
},
“pd-server”: {
“use-region-storage”: “true”,
“max-gap-reset-ts”: “24h0m0s”,
“key-type”: “table”,
“runtime-services”: “”,
“metric-storage”: “http://10.155.111.136:9090”,
“dashboard-address”: “http://10.155.111.136:2379”
},
“cluster-version”: “4.0.2”,
“quota-backend-bytes”: “8GiB”,
“auto-compaction-mode”: “periodic”,
“auto-compaction-retention-v2”: “1h”,
“TickInterval”: “500ms”,
“ElectionInterval”: “3s”,
“PreVote”: true,
“security”: {
“cacert-path”: “”,
“cert-path”: “”,
“key-path”: “”,
“cert-allowed-cn”: null
},
“label-property”: {},
“WarningMsgs”: null,
“DisableStrictReconfigCheck”: false,
“HeartbeatStreamBindInterval”: “1m0s”,
“LeaderPriorityCheckInterval”: “1m0s”,
“dashboard”: {
“tidb_cacert_path”: “”,
“tidb_cert_path”: “”,
“tidb_key_path”: “”,
“public_path_prefix”: “/dashboard”,
“internal_proxy”: false,
“disable_telemetry”: false
},
“replication-mode”: {
“replication-mode”: “majority”,
“dr-auto-sync”: {
“label-key”: “”,
“primary”: “”,
“dr”: “”,
“primary-replicas”: 0,
“dr-replicas”: 0,
“wait-store-timeout”: “1m0s”,
“wait-sync-timeout”: “1m0s”
}
}
}
» scheduler show
[
“balance-hot-region-scheduler”,
“balance-leader-scheduler”,
“balance-region-scheduler”,
“label-scheduler”
]
» store
{
"count": 3,
"stores": [
{
"store": {
"id": 20847613,
"address": "10.121.93.54:20160",
"version": "4.0.2",
"status_address": "10.121.93.54:20180",
"git_hash": "98ee08c587ab47d9573628aba6da741433d8855c",
"start_timestamp": 1594185815,
"last_heartbeat": 1594188873783713369,
"state_name": "Up"
},
"status": {
"capacity": "3.438TiB",
"available": "2.212TiB",
"used_size": "1.209TiB",
"leader_count": 33113,
"leader_weight": 1,
"leader_score": 33113,
"leader_size": 2179559,
"region_count": 99341,
"region_weight": 1,
"region_score": 6520470,
"region_size": 6520470,
"start_ts": "2020-07-08T00:23:35-05:00",
"last_heartbeat_ts": "2020-07-08T01:14:33.783713369-05:00",
"uptime": "50m58.783713369s"
}
},
{
"store": {
"id": 20847615,
"address": "10.121.95.220:20160",
"version": "4.0.2",
"status_address": "10.121.95.220:20180",
"git_hash": "98ee08c587ab47d9573628aba6da741433d8855c",
"start_timestamp": 1594185447,
"last_heartbeat": 1594188878795585456,
"state_name": "Up"
},
"status": {
"capacity": "3.438TiB",
"available": "2.141TiB",
"used_size": "1.206TiB",
"leader_count": 33114,
"leader_weight": 1,
"leader_score": 33114,
"leader_size": 2172022,
"region_count": 99341,
"region_weight": 1,
"region_score": 6520470,
"region_size": 6520470,
"start_ts": "2020-07-08T00:17:27-05:00",
"last_heartbeat_ts": "2020-07-08T01:14:38.795585456-05:00",
"uptime": "57m11.795585456s"
}
},
{
"store": {
"id": 22290001,
"address": "10.121.93.145:20160",
"version": "4.0.2",
"status_address": "10.121.93.145:20180",
"git_hash": "98ee08c587ab47d9573628aba6da741433d8855c",
"start_timestamp": 1594185163,
"deploy_path": "/home/tidb/deploy/bin",
"last_heartbeat": 1594188874125599189,
"state_name": "Up"
},
"status": {
"capacity": "3.438TiB",
"available": "2.096TiB",
"used_size": "1.325TiB",
"leader_count": 33114,
"leader_weight": 1,
"leader_score": 33114,
"leader_size": 2168889,
"region_count": 99341,
"region_weight": 1,
"region_score": 6520470,
"region_size": 6520470,
"start_ts": "2020-07-08T00:12:43-05:00",
"last_heartbeat_ts": "2020-07-08T01:14:34.125599189-05:00",
"uptime": "1h1m51.125599189s"
}
}
]
}
似乎中午升级4.0.2之后好了
» store
{
"count": 3,
"stores": [
{
"store": {
"id": 20847613,
"address": "10.121.93.54:20160",
"version": "4.0.0",
"status_address": "10.121.93.54:20180",
"git_hash": "198a2cea01734ce8f46d55a29708f123f9133944",
"start_timestamp": 1594178987,
"last_heartbeat": 1594183186335502292,
"state_name": "Up"
},
"status": {
"capacity": "3.438TiB",
"available": "2.21TiB",
"used_size": "1.21TiB",
"leader_count": 0,
"leader_weight": 1,
"leader_score": 0,
"leader_size": 0,
"region_count": 99459,
"region_weight": 1,
"region_score": 6515493,
"region_size": 6515493,
"start_ts": "2020-07-07T22:29:47-05:00",
"last_heartbeat_ts": "2020-07-07T23:39:46.335502292-05:00",
"uptime": "1h9m59.335502292s"
}
},
{
"store": {
"id": 20847615,
"address": "10.121.95.220:20160",
"version": "4.0.0",
"status_address": "10.121.95.220:20180",
"git_hash": "198a2cea01734ce8f46d55a29708f123f9133944",
"start_timestamp": 1594179183,
"last_heartbeat": 1594183185987830587,
"state_name": "Up"
},
"status": {
"capacity": "3.438TiB",
"available": "2.14TiB",
"used_size": "1.206TiB",
"leader_count": 49734,
"leader_weight": 1,
"leader_score": 49734,
"leader_size": 3261408,
"region_count": 99459,
"region_weight": 1,
"region_score": 6515493,
"region_size": 6515493,
"start_ts": "2020-07-07T22:33:03-05:00",
"last_heartbeat_ts": "2020-07-07T23:39:45.987830587-05:00",
"uptime": "1h6m42.987830587s"
}
},
{
"store": {
"id": 22290001,
"address": "10.121.93.145:20160",
"version": "4.0.0",
"status_address": "10.121.93.145:20180",
"git_hash": "198a2cea01734ce8f46d55a29708f123f9133944",
"start_timestamp": 1594179921,
"deploy_path": "/home/tidb/deploy/bin",
"last_heartbeat": 1594183183797443275,
"state_name": "Up"
},
"status": {
"capacity": "3.438TiB",
"available": "2.096TiB",
"used_size": "1.324TiB",
"leader_count": 49725,
"leader_weight": 1,
"leader_score": 49725,
"leader_size": 3254085,
"region_count": 99459,
"region_weight": 1,
"region_score": 6515493,
"region_size": 6515493,
"start_ts": "2020-07-07T22:45:21-05:00",
"last_heartbeat_ts": "2020-07-07T23:39:43.797443275-05:00",
"uptime": "54m22.797443275s"
}
}
]
}
这是之前查的
嗯,上面的 store 中 leader count 是比较正常的。
先观察下吧,之前是什么版本呢?
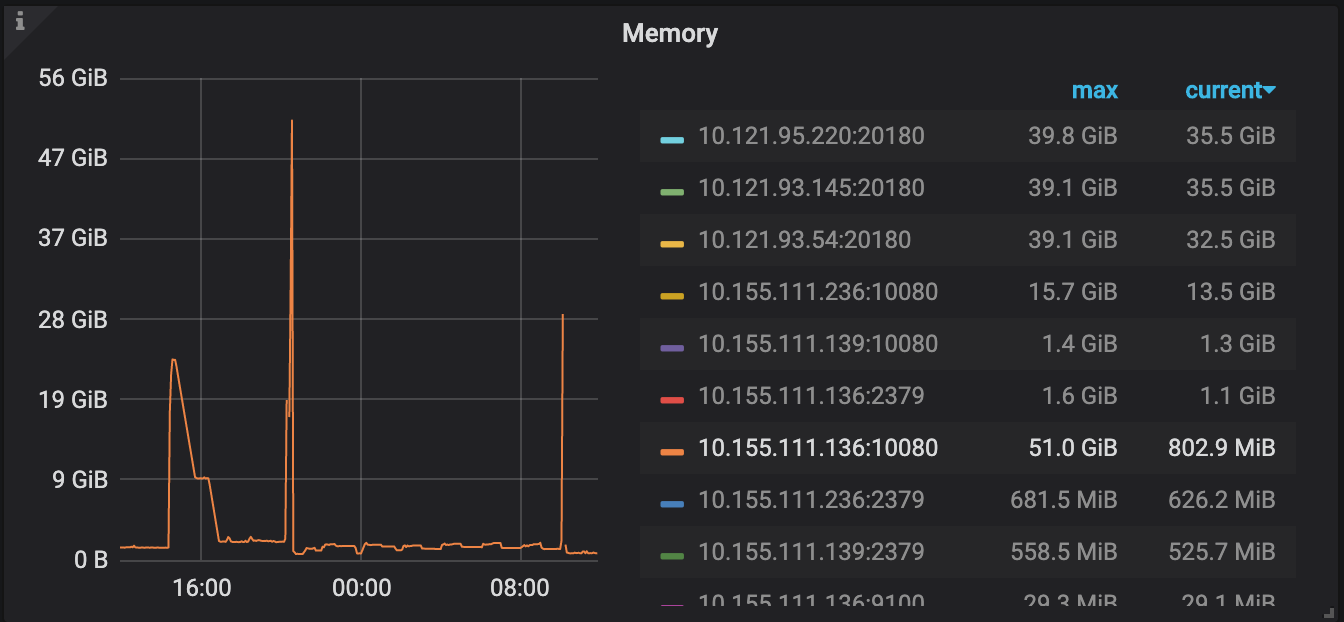
之前是4.0 GA,大概正常运行了一个月,最近有个内部测试的数据任务,造成大量主键冲突的重试,然后观察到3个kv节点中其中两个节点的cpu远高于第三个
这个描述还是比较模糊的,回归到本问题,在升级到 4.0.2 之后再观察下集群状态,看是否会出现 4.0ga 的问题吧
好的,另外我现在监控启不起来了,不知道为什么…
TASK [wait until the prometheus port is up] ********************************************************************************************************************************************
fatal: [10.155.111.136]: FAILED! => changed=false
elapsed: 300
msg: the prometheus port 9090 is not up
to retry, use: --limit @/home/tidb/tidb-ansible-4.0.2_/retry_files/start.retry
PLAY RECAP *****************************************************************************************************************************************************************************
10.121.93.145 : ok=3 changed=0 unreachable=0 failed=0
10.121.93.54 : ok=3 changed=0 unreachable=0 failed=0
10.121.95.220 : ok=3 changed=0 unreachable=0 failed=0
10.155.111.136 : ok=4 changed=0 unreachable=0 failed=1
10.155.111.139 : ok=3 changed=0 unreachable=0 failed=0
10.155.111.236 : ok=3 changed=0 unreachable=0 failed=0
localhost : ok=8 changed=5 unreachable=0 failed=0
ERROR MESSAGE SUMMARY ******************************************************************************************************************************************************************
[10.155.111.136]: Ansible Failed! ==>
changed=false
elapsed: 300
msg: the prometheus port 9090 is not up
这是执行什么命令之后出现的呢,可以去节点上看看 prometheus 进程状态,再看一遍 log 是否有详细信息
/home/tidb/deploy/scripts/run_prometheus.sh: line 13: /home/tidb/deploy/bin/prometheus: Is a directory
/home/tidb/deploy/scripts/run_prometheus.sh: line 13: exec: /home/tidb/deploy/bin/prometheus: cannot execute: Is a directory
我记得出问题的时候是执行了stop.yml和start.yml,然后就启不起来了,然后看到有个方案是备份prometheus2.0.0.data.metrics重新deploy,就按这个流程做了下,这么看似乎路径是调整了?
清理了下deploy目录的prometheus,重新部署了下,现在报错是
level=error ts=2020-07-08T10:28:38.651450737Z caller=notifier.go:481 component=notifier alertmanager=http://10.155.111.136:9093/api/v1/alerts count=0 msg="Error sending alert" err="Post http://10.155.111.136:9093/api/v1/alerts: dial tcp 10.155.111.136:9093: connect: connection refused"
level=error ts=2020-07-08T10:29:59.663722901Z caller=notifier.go:481 component=notifier alertmanager=http://10.155.111.136:9093/api/v1/alerts count=1 msg="Error sending alert" err="Post http://10.155.111.136:9093/api/v1/alerts: dial tcp 10.155.111.136:9093: connect: connection refused"
level=error ts=2020-07-08T10:30:01.8112996Z caller=notifier.go:481 component=notifier alertmanager=http://10.155.111.136:9093/api/v1/alerts count=1 msg="Error sending alert" err="Post http://10.155.111.136:9093/api/v1/alerts: dial tcp 10.155.111.136:9093: connect: connection refused"
level=error ts=2020-07-08T10:30:07.16594252Z caller=notifier.go:481 component=notifier alertmanager=http://10.155.111.136:9093/api/v1/alerts count=12 msg="Error sending alert" err="Post http://10.155.111.136:9093/api/v1/alerts: dial tcp 10.155.111.136:9093: connect: connection refused"
将此报错之后的步骤辛苦说一下,这边不是很清晰。
错误现场应该是没有了,现象是grafana db pd混部的一个节点,在执行ansible-playbook stop.yml -l 10.xx.xx.xx和ansible-playbook start.yml -l 10.xx.xx.xx以后,start失败,卡在启动grafana,之后为了不影响正常业务,执行了 start.yml --tags=tidb,pd,是正常的
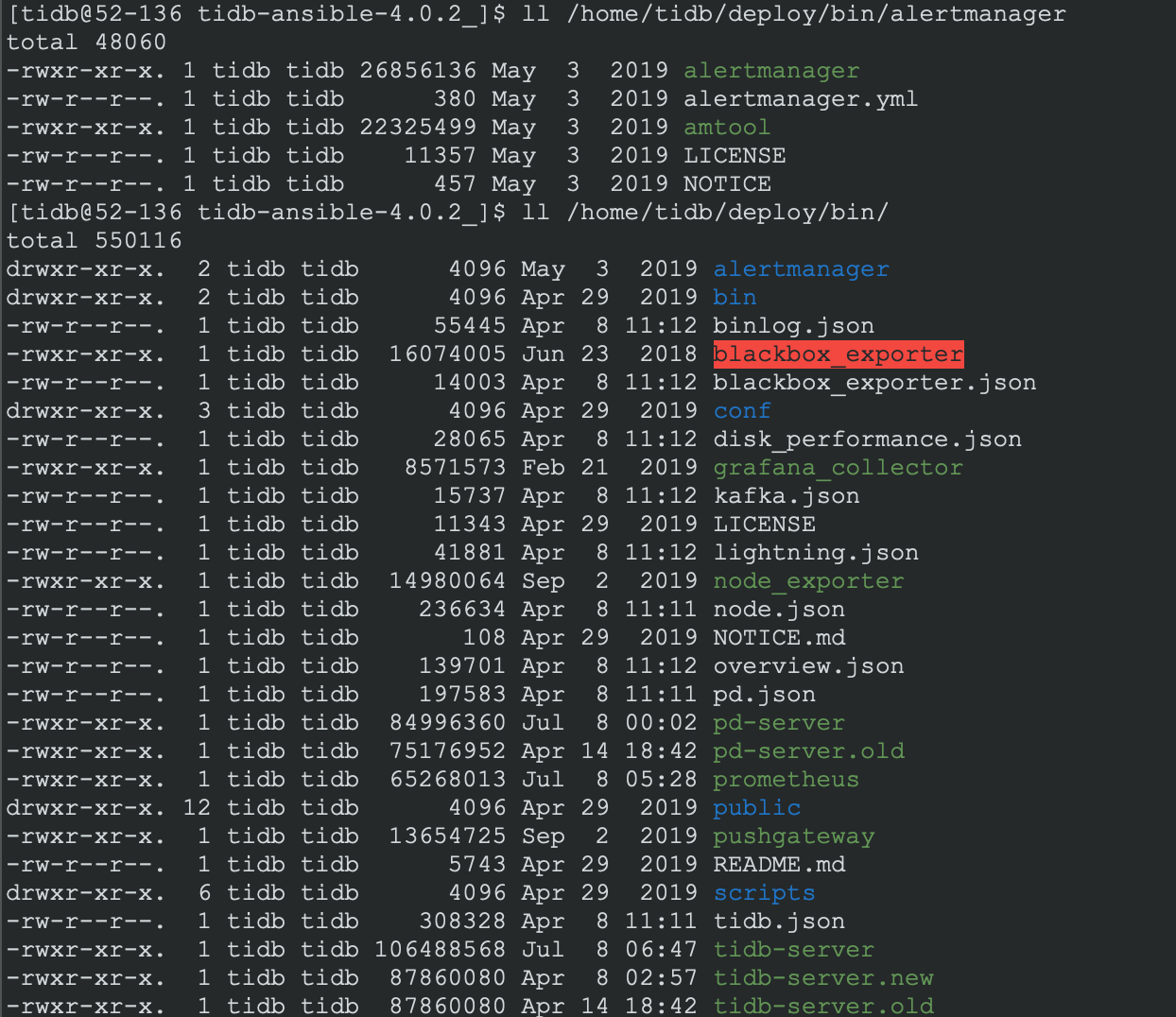
刚通过重新部署的方法把监控起来了,是把grafana alertmanager prometheus目录全部删除,3个全部重新deploy,之前出现/home/tidb/deploy/bin/prometheus: Is a directory应该是因为没有deploy之前没有删除旧文件,导致这个文件被做成了目录,现在目录是这样的
对比下之前的目录,prometheus的截图没有了,只有alertmanager的截图
目前的问题是,Prometheus 启动访问 altermanager 失败,可以看下 9093 起来了没有,可以尝试将 Prometheus 和 altermanager deploy/data dir 删除,重新 deploy 试下。
重新部署已经ok了,暂时也没有出现leader不平衡的问题
OK![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。