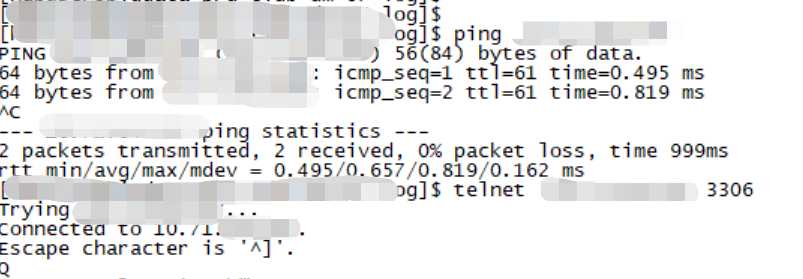
通过ansbile的方式安装了DM,集群有6个worker,其中5个正常连接,第六个worker连接报错:

通过启动任务,报错如下
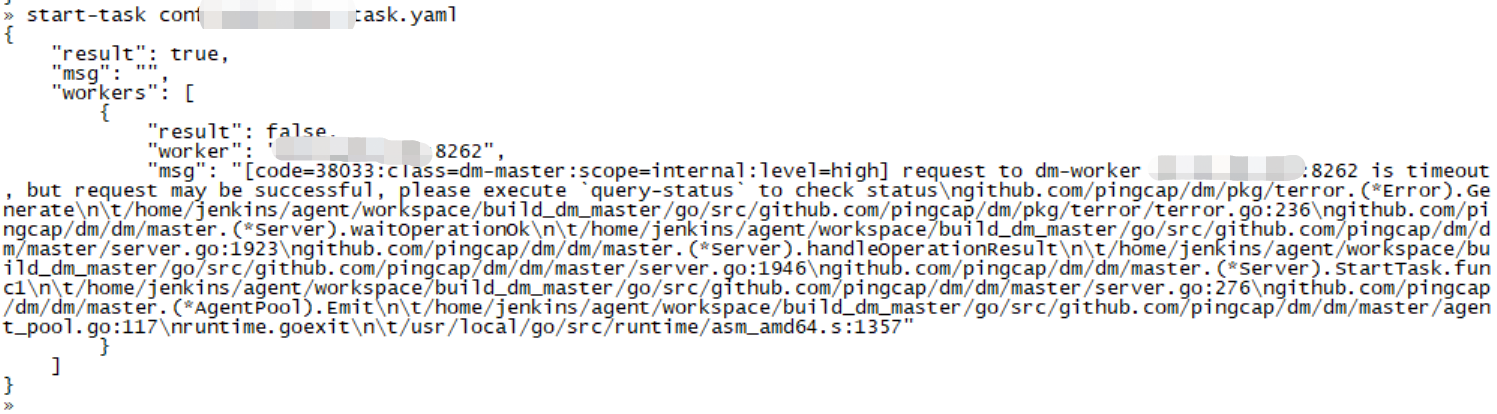
PS:在批量部署DM的时候,第六个worker密码一开始是错误的,后来部署完成后,是直接修改第六个dm-worker.yaml中的加密密码,还请帮忙看下原因,谢谢。
通过ansbile的方式安装了DM,集群有6个worker,其中5个正常连接,第六个worker连接报错:
通过启动任务,报错如下
PS:在批量部署DM的时候,第六个worker密码一开始是错误的,后来部署完成后,是直接修改第六个dm-worker.yaml中的加密密码,还请帮忙看下原因,谢谢。
尝试的方法一
1、修改 inventory.ini 中worker6的密码
2、 ansible-playbook stop.yml 关闭集群
3、ansible-playbook start.yml 重启集群
后继续报错
尝试的方法二
直接进入work6所在机器kill进程后,重启work6
nohup dm-worker -config conf/dm-worker.toml &
但还是报错
你好,
下发密码是 ansible-playbook deploy -l dm-worker6 这么执行吗?
其实我已经去work6所在机器修改了mysql的密码了
最终还是需要使用 dm-ansible 进行运维部署的,所以需要执行 deploy 操作,执行完成可以确认下节点上是否已经更新了密码
之前莫名其妙恢复了,今天晚上该worker又有问题,确认不是上游mysql的问题。重启master、worker后还是报错,看日志应该是master连接worker失败了,如下,还请帮忙确认下问题,谢谢。
master日志
[2020/07/09 20:41:18.203 +08:00] [INFO] [printer.go:54] [“Welcome to dm-master”] [“Release Version”=v1.0.6] [“Git Commit Hash”=eaf2683c05ab44143bfb286bfbbc3ba157c555cc] [“Git Branch”=release-1.0] [“UTC Build Time”=“2020-06-17 10:22:15”] [“Go Version”=“go version go1.13 linux/amd64”]
[2020/07/09 20:41:18.203 +08:00] [INFO] [main.go:54] [“dm-master config”="{“log-level”:“info”,“log-file”:"/data/dm-deploy/log/dm-master.log",“log-rotate”:"",“rpc-timeout”:“30s”,“rpc-rate-limit”:10,“rpc-rate-burst”:40,“master-addr”:":8261",“deploy”:{“mysql-replica-01”:“xx.xx.xx.114:8262”,“mysql-replica-02”:“xx.xx.xx.214:8262”,“mysql-replica-03”:“xx.xx.xx.223:8262”,“mysql-replica-04”:“xx.xx.xx.151:8262”,“mysql-replica-05”:“xx.xx.xx.238:8262”,“mysql-replica-06”:“xx.xx.xx.246:8262”},“config-file”:“conf/dm-master.toml”}"]
[2020/07/09 20:41:18.204 +08:00] [INFO] [server.go:190] [“listening gRPC API and status request”] [address=:8261]
[2020/07/09 20:41:30.245 +08:00] [INFO] [server.go:497] [payload=] [request=QueryStatus]
[2020/07/09 20:41:38.205 +08:00] [ERROR] [server.go:1308] [“create FetchDDLInfo stream”] [worker=xx.xx.xx.246:8262] [error="[code=38008:class=dm-master:scope=internal:level=high] grpc request error: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: timed out waiting for server handshake"]
worker日志
[2020/07/09 20:47:09.596 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=broker_client_history] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:09.989 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=c_customer_followup] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:10.148 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=g_signin_record] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:10.436 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=client] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:11.510 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=broker1] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:11.992 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=c_customer_detail] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:13.028 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=c_customer] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:13.688 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=broker_invite_registe_info] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:13.836 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=checkpoint_lox] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
[2020/07/09 20:47:14.265 +08:00] [ERROR] [syncer.go:2077] [“fail to get master status”] [task=broker_approve] [unit=“binlog replication”] [error="[code=10003:class=database:scope=not-set:level=high] database driver: invalid connection"]
任务也无法查看:
check-task conf/broker-task.yaml
{
“result”: false,
“msg”: “[code=38008:class=dm-master:scope=internal:level=high] fetch config of worker xx.xx.xx.246:8262: grpc request error: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: timed out waiting for server handshake\ngithub.com/pingcap/dm/pkg/terror.(*Error).Delegate\
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/pkg/terror/terror.go:271\ngithub.com/pingcap/dm/dm/master/workerrpc.callRPC\
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/dm/master/workerrpc/rawgrpc.go:124\
github.com/pingcap/dm/dm/master/workerrpc.(*GRPCClient).SendRequest\
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/dm/master/workerrpc/rawgrpc.go:64\ngithub.com/pingcap/dm/dm/master.(*Server).getWorkerConfigs.func3\
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/dm/master/server.go:1756\ngithub.com/pingcap/dm/dm/master.(*AgentPool).Emit\
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/dm/master/agent_pool.go:117\
runtime.goexit\
\t/usr/local/go/src/runtime/asm_amd64.s:1357”
}
master worker 互 ping 一下看是否通,telnet dm-master 和 dm-worker 的端口也行,反馈下操作截图,感谢
两边的ip和端口肯定是没问题的,因为我们的同步任务最近一直再跑,只是昨天在没有任何人工操作的时候发现出了问题。
以下是2边的telnet情况
telnet worker
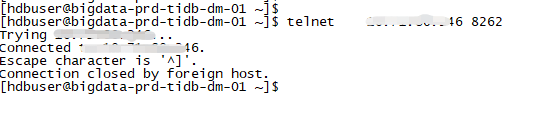
telnet dm-master

今天想连接上游mysql,发现已经超过最大连接数,上次出问题的时候也存在这种情况,请帮忙确认下是否和最大连接数有关?
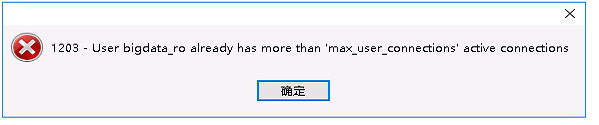
dm-worker 是需要 连接到上游 MySQL 作为从库拉取binlog 的,所以如果连接上游 MySQL 超过最大连接数的话会连接失败
麻烦确认一下:
之前的最大连接数是1000
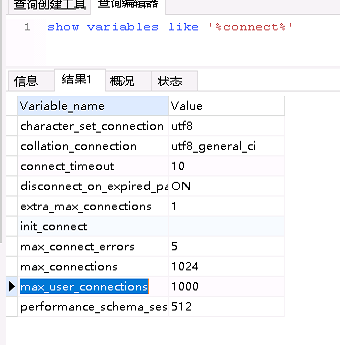
早上dba已经把连接都杀了,所以现在查看实际连接数已经没有意义。
从早上杀了账号 bigdata_ro 的连接数,我这边重启worker后,已经恢复正常。
所以现在的问题是,在什么样的情况下会导致我们 bigdata_ro 的连接数激增?
另外:早上我查看TIDB的实际连接数,该worker的连接数也已经达到了接近800(现在看该worker的连接数大概在400左右),这个连接数这么大也不清楚是否正常。
bigdata_ro 账户是只有 dm-worker 会使用么
关于 TiDB 中的连接数,默认每个 task 会起 16 个连接连接到下游 TiDB 进行数据同步的,这个可以通过修改 task 配置中 syncer.worker-count 进行修改,TiDB 的连接数是否因为有多个 task 同步任务导致的,另外会有应用来连接 TiDB 进行查询吗,应用会有多少连接到 TiDB?

1、这个worker启动了16个task,–所以连接数应该是16*16,问题不大
2、刚刚确定清楚,是上游mqsql磁盘空间异常,导致myqsl的连接数满了–这应该就是根本原因了。
谢谢各位专家的解答!!
好的,后续还有问题的话,欢迎开帖提问
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。