因为想测试TiDB集群的性能所以搭了一套TiDB的集群,目前在看了一部分的tidb文档,总结下来现在有3个问题求解惑:
1.Raft group region为多数表决协议下的产物,请问空间使用率可否用下述的方法估算?
假设有n个tikv节点,配置完全相同,那么存储x大小的数据所需的磁盘空间为:(floor(n/2)+1)*x,假设单台存储空间为常数S,那么空间占用率为: (floor(n/2)+1)x/(nS),随着节点数增多空间使用率并无大的变化(有微小的提升),但是其绝对值几乎是线性上涨的。
官网文档又提到:“默认配置是 3 副本(相应参数为max-replicas)”,为何可以手动设置replica数量,如果7节点我把max-replicas数量设置为3,那么如果有3个节点宕机的话那么可能出现某个region缺失的情况,所以这个值必须综合考量空间利用率和集群能允许的最大宕机数来考虑?如果7tikv node的集群max-replicas为3且宕机了3台,那么万一出现某些region彻底丢失怎么处理?
2.MVCC通过版本号实现并发无冲突更新,请问这个version具体是什么格式的(TSO还是普通的时间戳)?
关于MVCC的解释中官方手册还说当会话指定了version时会触发MVCC机制,多个行记录的多个versions会带来额外的空间开销?如果行版本过多会不会导致region大小超过阈值?
此外如果客户端未指定version参数(可能是通过set session tidb_snapshot指定?)那么tidb会自动设置一个时间戳作为version号以便利用MVCC特性吗?如果不加那么默认读取哪一个一个version?
3.索引的key中indexPrefixSep中的Sep是什么的缩写?
感谢大佬抽时间解惑,谢谢。
空间使用率是向你描述的那样,但是也反映出数据写入量是一直上涨的。否则在数据量不变的情况下,通过扩容 tikv 节点可以达到分摊计算压力和存储数据量的目的
似的,在多副本的情况下都需要考虑当丢失了半数以上副本的情况。这种问题需要配合 tikv 和 pd 的 label 进行调度,将同一个 raft group 上不同 peer 分布在不同的 label 上。
如果出现丢失半数以上副本及时 tikv 节点可以对外提供服务,当请求访问到该 region 时,将出现报错,这种情况需要具体分析,可以联系 pingcap 或者 asktug 提帖子这边帮助一起分析。
这个我说下我的理解,目前 tidb 可以通过 api 搜索当前值的 mvcc,对应的值可以看下链接和图片
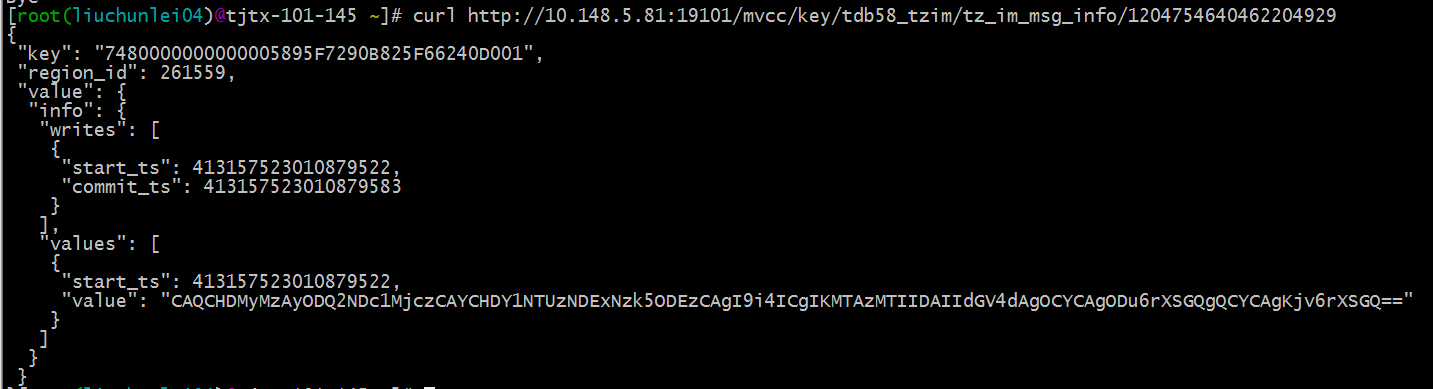
- tidb/docs/tidb_http_api.md at master · pingcap/tidb · GitHub
还有 tidb 中有 snapshot ,可以通过设置 snapshot 来查看对应时间的数据版本
以上都是基于 GC 时间范围内做的。

- mvcc 的实现与事务也是息息相关的,可以看下 asktug 中的技术文章来帮助理解:https://asktug.com/t/topic/1350
seperate 分隔符,indexPrefixSep 其实就是特殊的字符常量,上面 asktug 的技术文章和 tidb in action 有提到。可以先看下。
谢谢 [户口舟亢]的回复和链接。
3个问题初步搞清了,mvcc的version应该使用一个全局单调递增的start_ts类似oracle scn的东西来标识的。Sep应该只是一个对索引做区分的常量值。
刚才在测试一个analyze table语句的时候卡住了,tikv pd tikv的日志都没什么新增,系统资源也没什么变化,会话kill也没什么反应,ctrl-c退出重登show processlist发现analyze语句的会话好像还在,对应的表也可以增删改查,这是个什么状况,好奇怪啊。
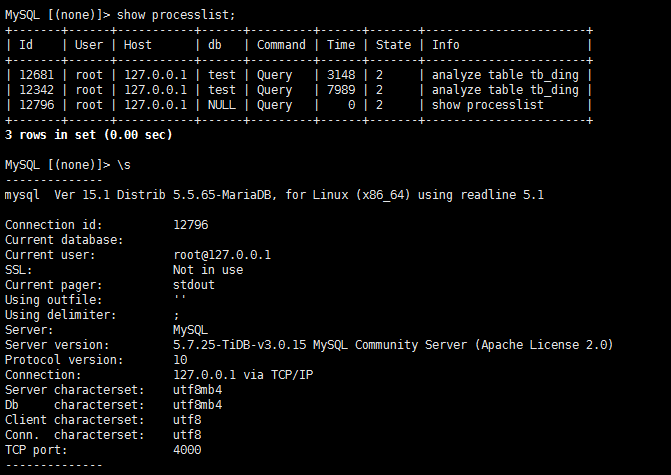
如果表很大,执行时间长是预期的,ctrl-c 之后会在后台继续运行,如果此命令已经下推到 tikv 执行,将不会被 kill
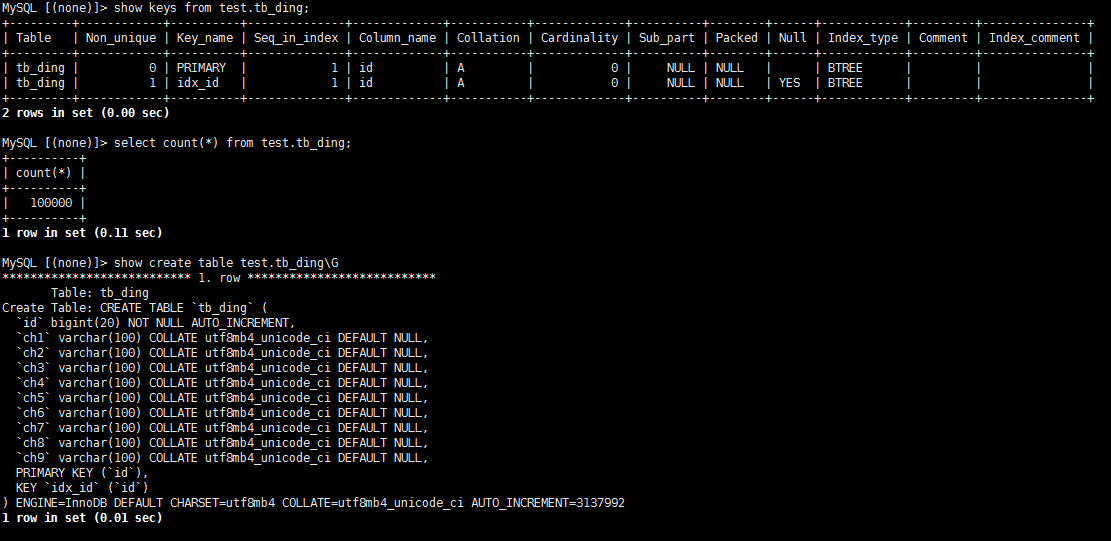
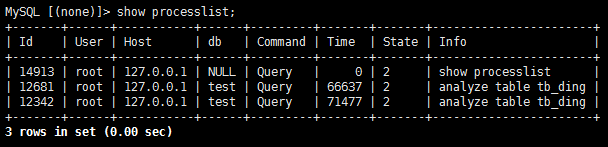

SHOW ANALYZE STATUS 返回结果看下,

你好,
看来 对 tb_ding 执行过两次 analyze table 。可能是卡主了,可以重启下 tidb-server 应该可以解决。 restart -R tidb
谢谢,我kill -9相关的tidb-server然后使用ansible-playbook start.yml启动了被杀的tidb-server
如果前端有 LB,使用 rolling_update 会好些,
目前的问题解决了吗
已解决谢谢。
ok,有问题欢迎开新帖继续讨论
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。