一、背景
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一,特别在疫情这段时间内,业务增长近3-4倍。伴鱼慢日志系统对于帮助我们及时发现数据库性能问题和预防数据库性能风险,起到了很大的作用。
目前,伴鱼有10套TiDB数据库,20+套mongodb数据库,200+数据库实例。日常数据库性能问题处理,由于慢日志分散在多台机器,面临日志查询/分析/统计等各种不便。因此,我们的慢日志系统,需要满足以下几个要求:
1)慢日志集中准实时收集
2)日志查询/分析/统计可视化
3)慢日志报表功能
4)慢日志及时告警
下面主要介绍下伴鱼慢日志系统以及系统给我们带来的实实在在的效果。
二、慢日志系统详解
我们认为数据库的性能问题,绝大部分原因都是由慢SQL导致的,当然像数据库bug、业务异常流量等情况,在伴鱼还是比较少见的。所以,我们如何准实时收集分布式TiDB的慢日志、如何快速的做分析统计以及如何及时的告警,对于快速解决线上问题,甚至将性能风险扼杀在摇篮里至关重要。
1)如何准实时收集慢日志
我们采用了业界比较成熟的开源日志采集、分析、存储和展示架构,很好的解决了我们对慢日志的处理需求。
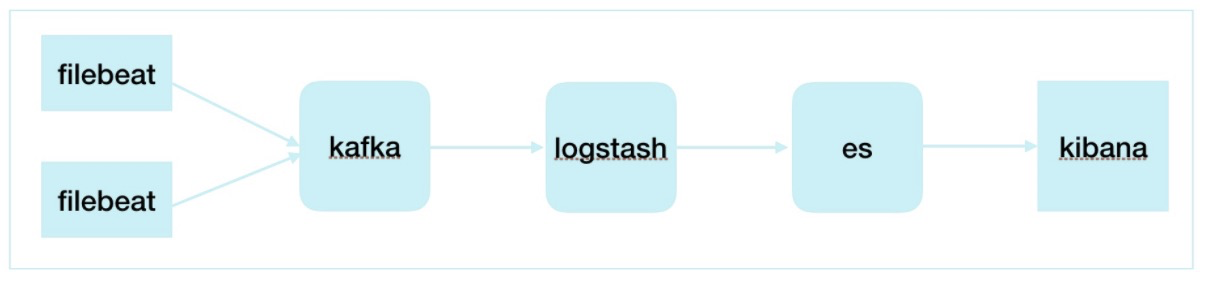
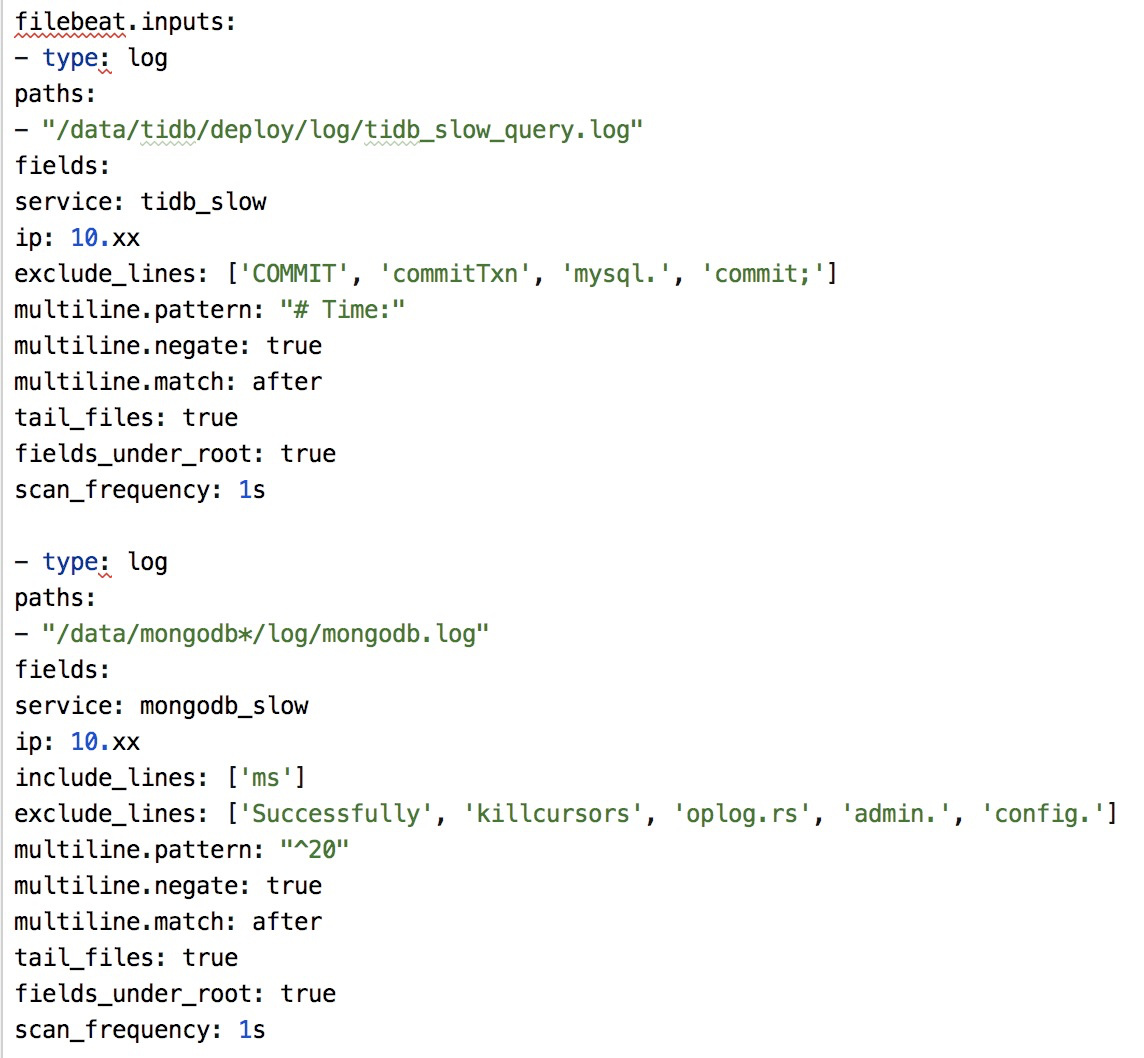
在上图中,filebeat负责增量收集TiDB产生的慢日志,由于filebeat比较轻量,对线上性能基本无影响。采集配置如下,其中service用于区分数据来源,在logstash解析阶段会用到;ip在filebeat部署阶段自动补上,主要用于分析阶段识别日志来源机器;exclude_lines排除掉非增删改查语句,便于后续解析。
原始慢日志(见下图)经过filebeat采集阶段简单处理后,存储到kafka。存储到kafka的慢日志内容格式,如下图所示。
原始日志格式

采集后的日志格式

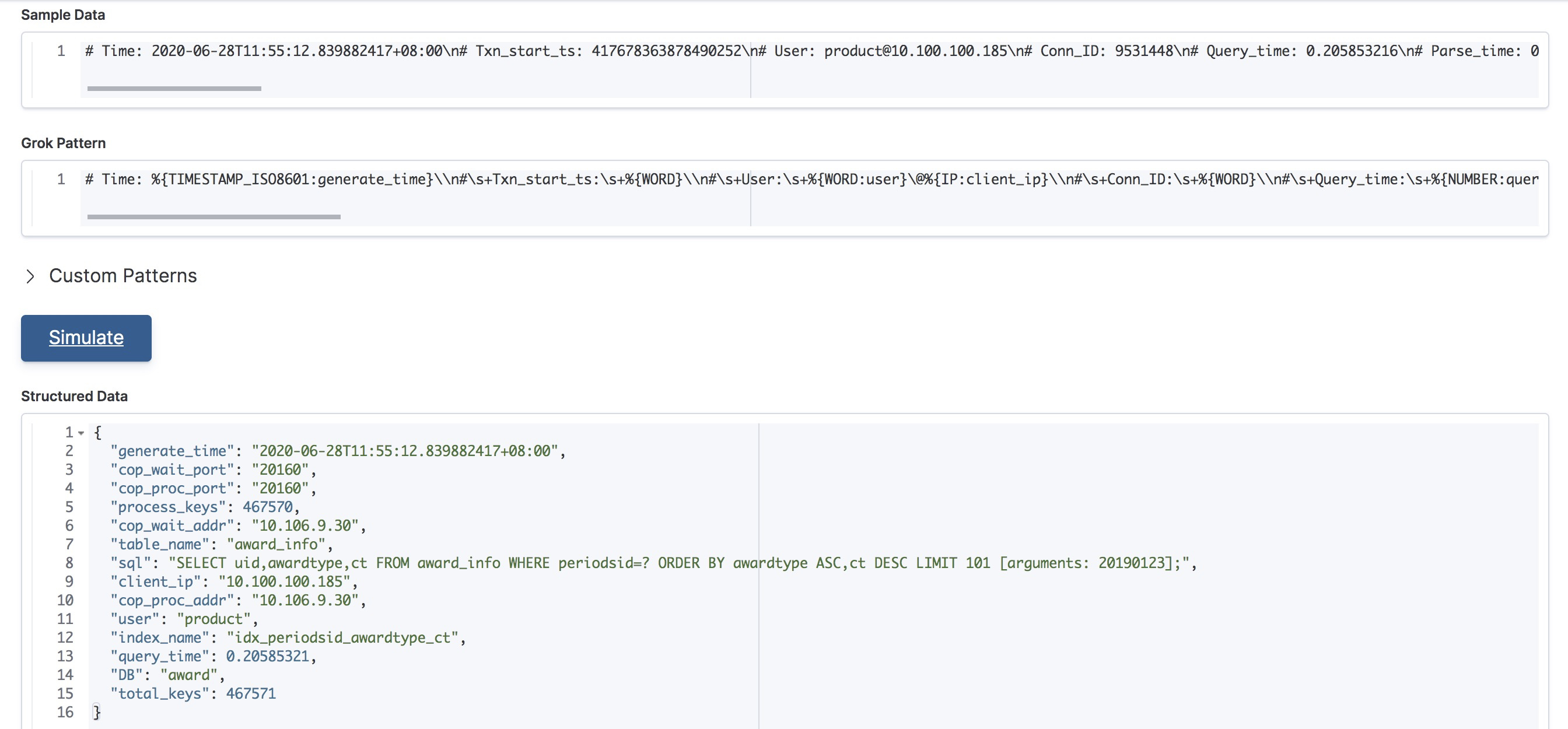
然后logstash负责读取kafka中的慢日志并进行解析,转换成我们想要的kv键值对,如下图所示。
最后解析后的数据入到es,供kibana查询分析统计。
对于TiDB的慢日志,我们重点关注慢日志中的某些特定字段,比如:
index_name: 语句执行过程中是否用到索引
DB:表示执行语句时使用的database。
query_time:表示执行这个语句花费的时间。
total_keys:表示Coprocessor扫过的key的数量。
process_keys:表示Coprocessor处理的key的数量。相比total_keys,processed_keys不包含 MVCC的旧版本。
sql:执行的sql语句
2) 如何对慢日志进行分析统计
慢日志通过logstash解析后入到es,通过kibana,我们可以利用解析的字段作为查询和聚合的条件,很方便的对数据进行分析统计。
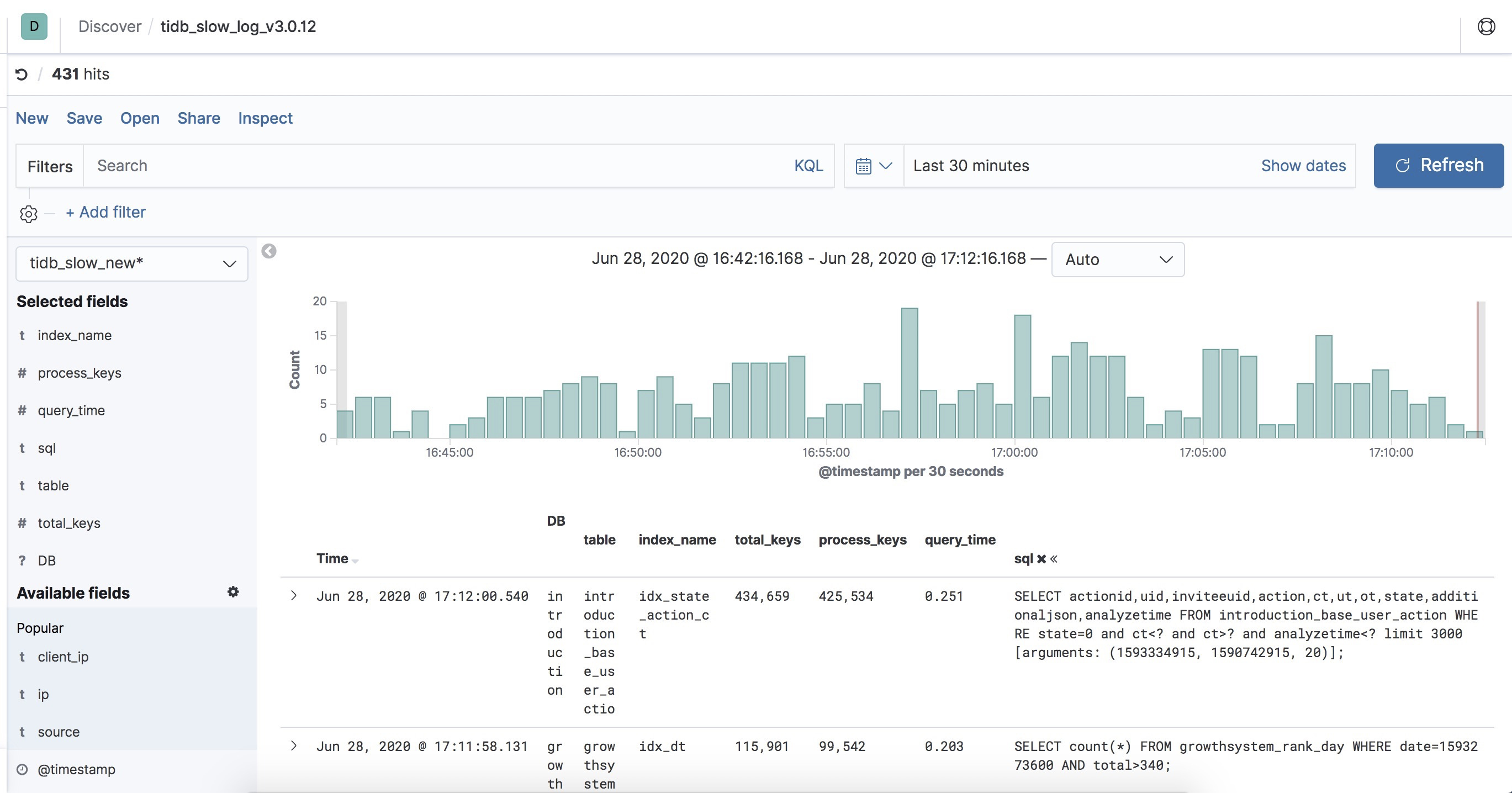
比如我们经常有如下操作:
1)30分钟内,慢请求分别按照db和table聚合
2)30分钟内,Process_keys大于5000的慢请求
3)30分钟内,query_time大于500ms的请求
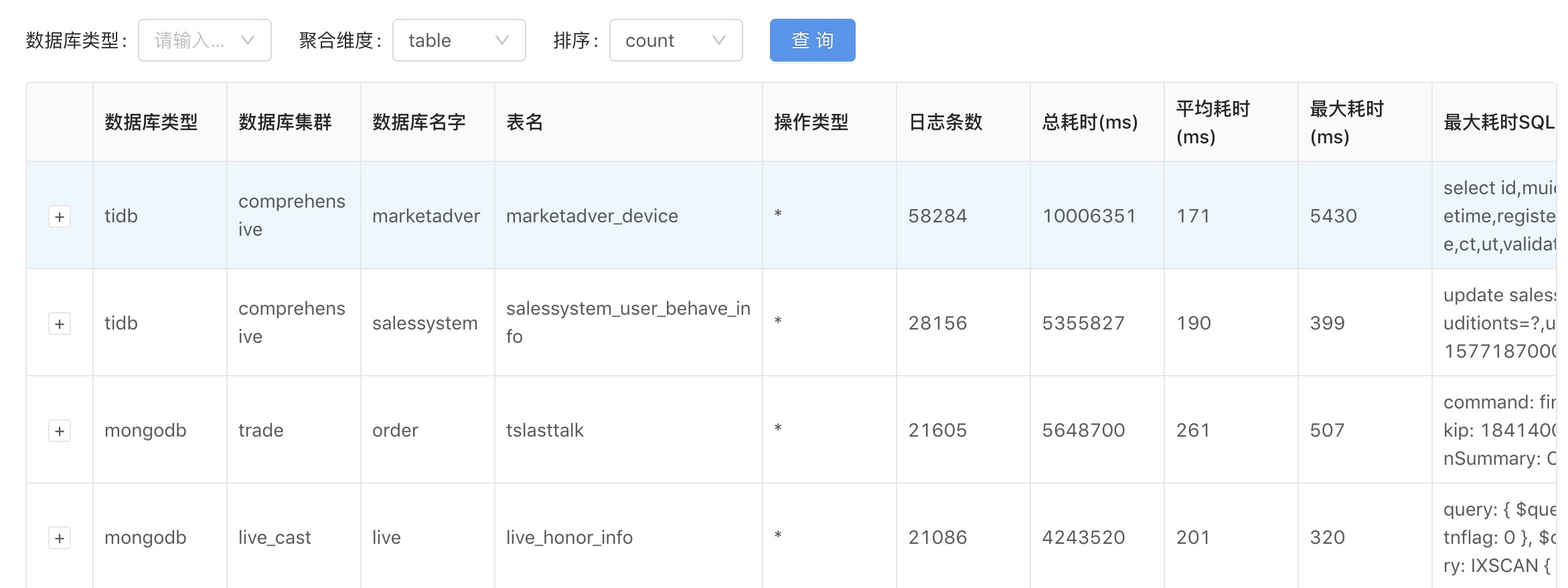
当然分析统计远不止这些,研发同学还可以在平台上定制所属业务db的趋势图和告警等。同时基于慢日志数据,我们还开发了慢日志分析报表平台,从多种维度,比如集群、库、表、操作类型、慢日志数量、执行总时间、平均响应时间以及最大耗时等维度对慢日志进行分析统计,并产生报表定时发送给研发同学。
3)如何对慢日志进行告警
在伴鱼,一个db对应一个服务,所以告警都是在特定db下设置规则。目前,我们告警粒度是一分钟,主要基于以下三类默认规则告警。
a) 某个db下的请求时间达到100ms且慢日志达到一定数量则告警
b) 某个db下的请求时间达到500ms且慢日志达到一定数量则告警
c) 某个db下的请求Process_keys大于5000且慢日志达到一定数量则告警
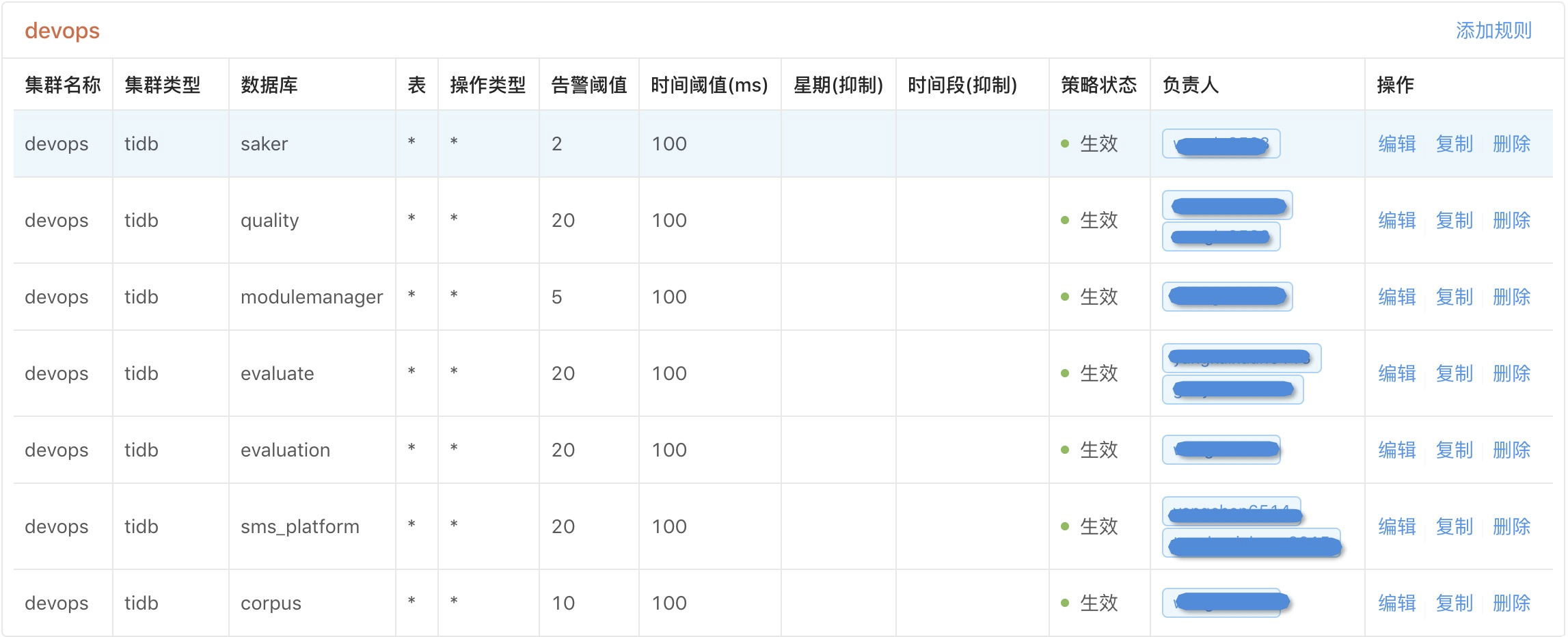
当然告警规则的设置不是一蹴而就的,需要根据不同的业务场景,dba和研发不断的调整,最终达到一个比较合理的阀值。
三、慢日志系统给伴鱼带来的收益
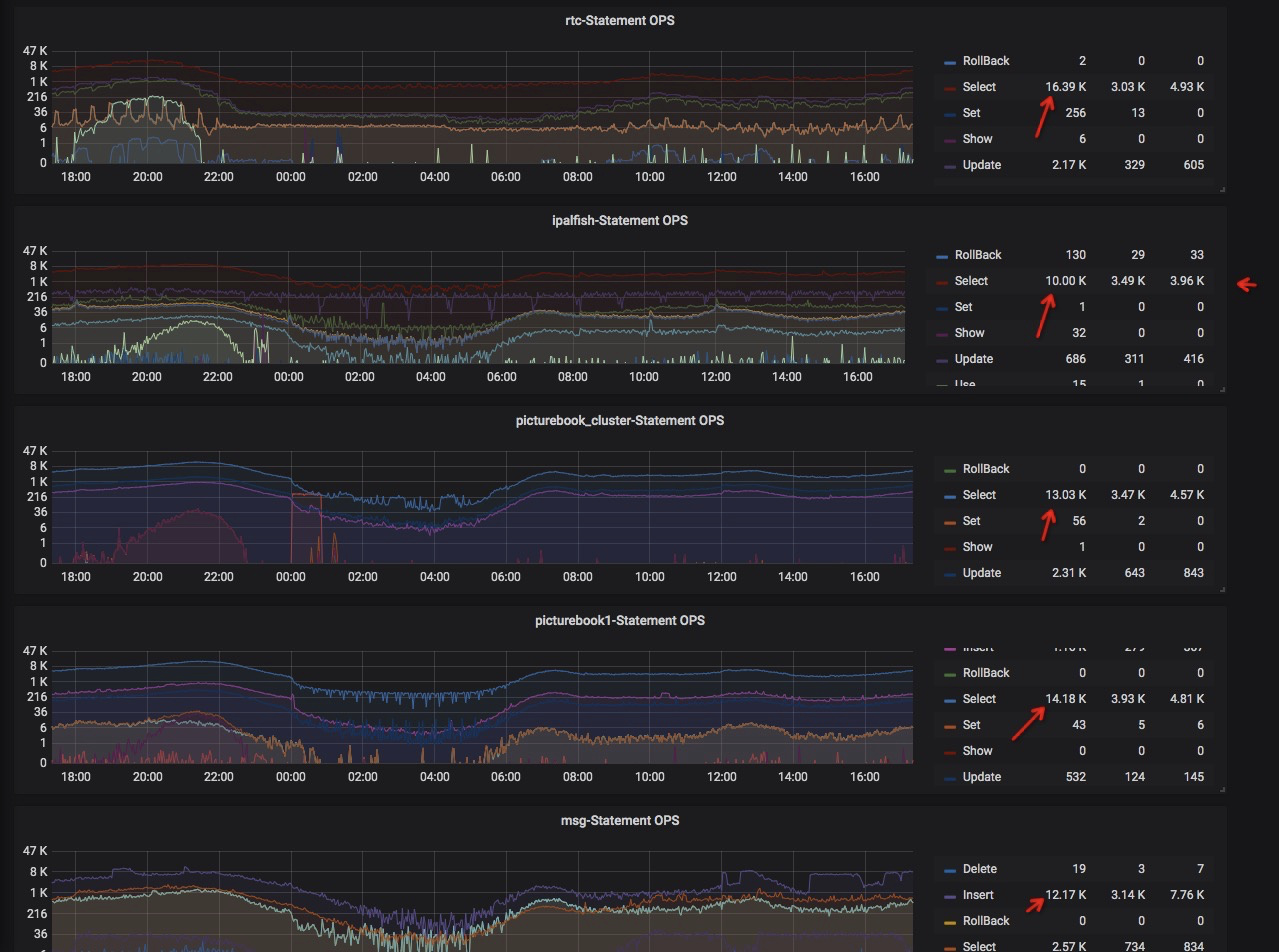
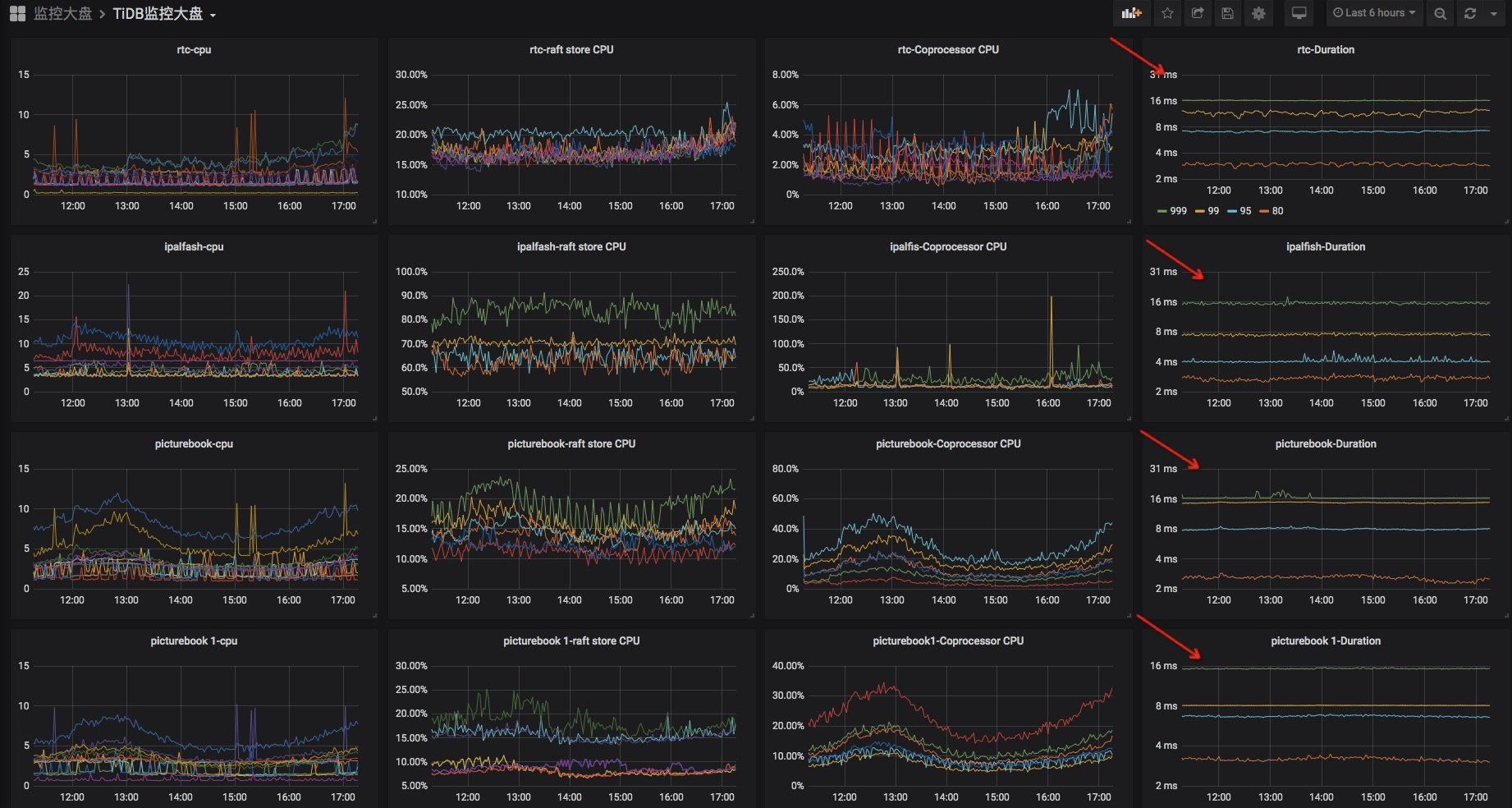
目前,我们10个TiDB集群,有6个核心集群请求过万,见下图。慢日志系统运行到现在,主要给我们带来3个收益。
1)延时低,6个请求过万核心集群999线基本维持在16ms左右,见下图
2)慢日志越来越少,tidb所有集群的慢日志(大于200ms),30分钟内,高峰期条数基本维持在500以内
3)故障少,除一次tidb优化器bug导致大表查询故障,影响线上近10分钟。近半年没有tidb引发的线上故障。
总结,慢日志系统在预防性能风险和发现性能问题确实起到了很重要的作用。