sorry,我们测试集群废除了,目前只有一个v4.0的集群,tispark 2.1不能用吧。![]()
索引的问题是不是还没解决?
请先通过tidb运行一下
analyze table ok_chi.perio_artical;
然后再通过tispark运行一下 explain

能否用 tispark-2.1 版本运行一下 explain ?
我刚才把tidb 3.0的测试集群恢复了,分别执行explain如下:
1.扫分区和时间字符串
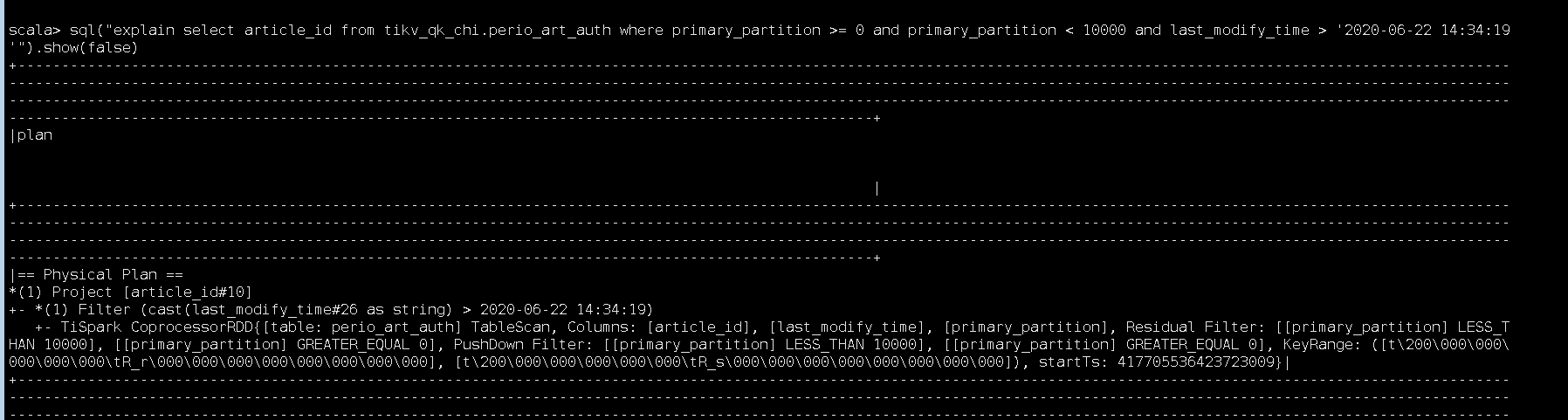
2.扫分区和时间戳

3.过滤索引字段和时间戳
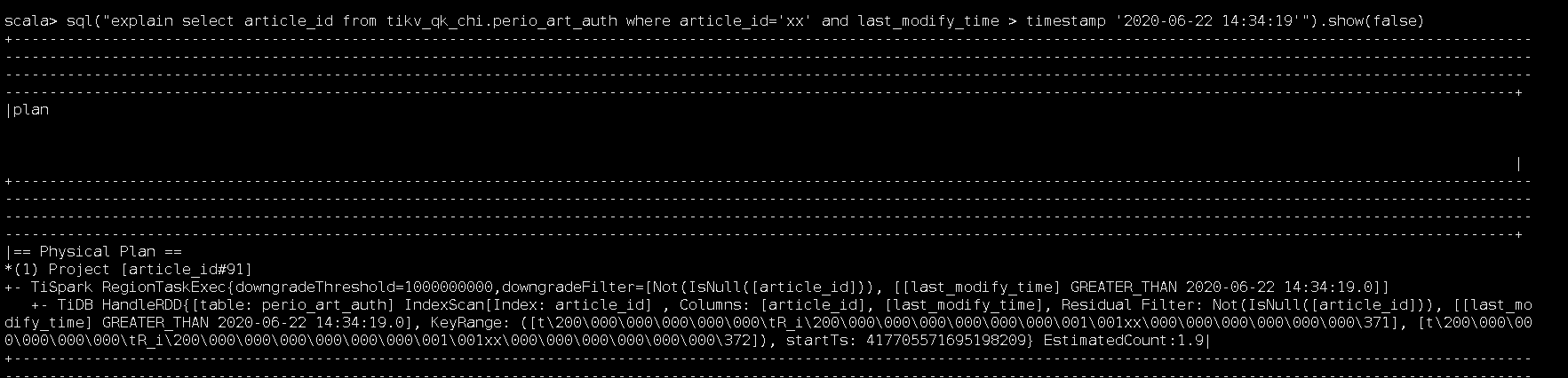
确实就像你说的,时间字符串的问题和tispark的版本没关系。但是这个索引字段确实有关系
多谢 我们查一下问题
能否把warning级别的日志打包一下发我一份?
索引的问题已解决,见 https://github.com/pingcap/tispark/pull/1500
可以下载最新的jar包测试一下
https://download.pingcap.org/tispark-assembly-nightly-linux-amd64.tar.gz
谢谢,我也关注这个issue了。其实我更想解决的是oom的问题。
oom不是已经解决了吗?
刚开始我也以为解决了,后来换了个场景又oom了
请问jvm内存设置多大?
15G,堆外8G。根本不可能溢出的。而且2.1就正常![]()
能否加一下jvm参数,在oom的时候dump一下heap,然后发给我?(可以把内存调小些,例如4G,方便传文件)
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=...
spark.executor.extraJavaOptions和spark.driver.extraJavaOptions都配置了oom dump但是最终都没有打出来,不知道怎么回事![]()
能否把配置发一下?
.setConf(SparkLauncher.DRIVER_EXTRA_JAVA_OPTIONS, “-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/heap-dump-driver.log”)
.setConf(SparkLauncher.EXECUTOR_EXTRA_JAVA_OPTIONS, “-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/heap-dump-exec.log”)
请问一下spark是什么模式?local、standalone 还是 on yarn?能否提供一下命令行提交命令?