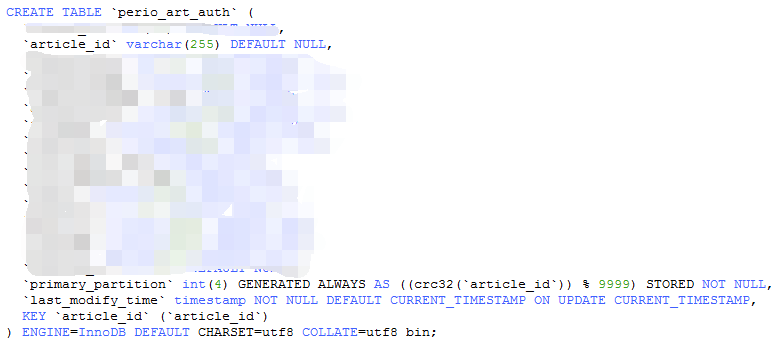
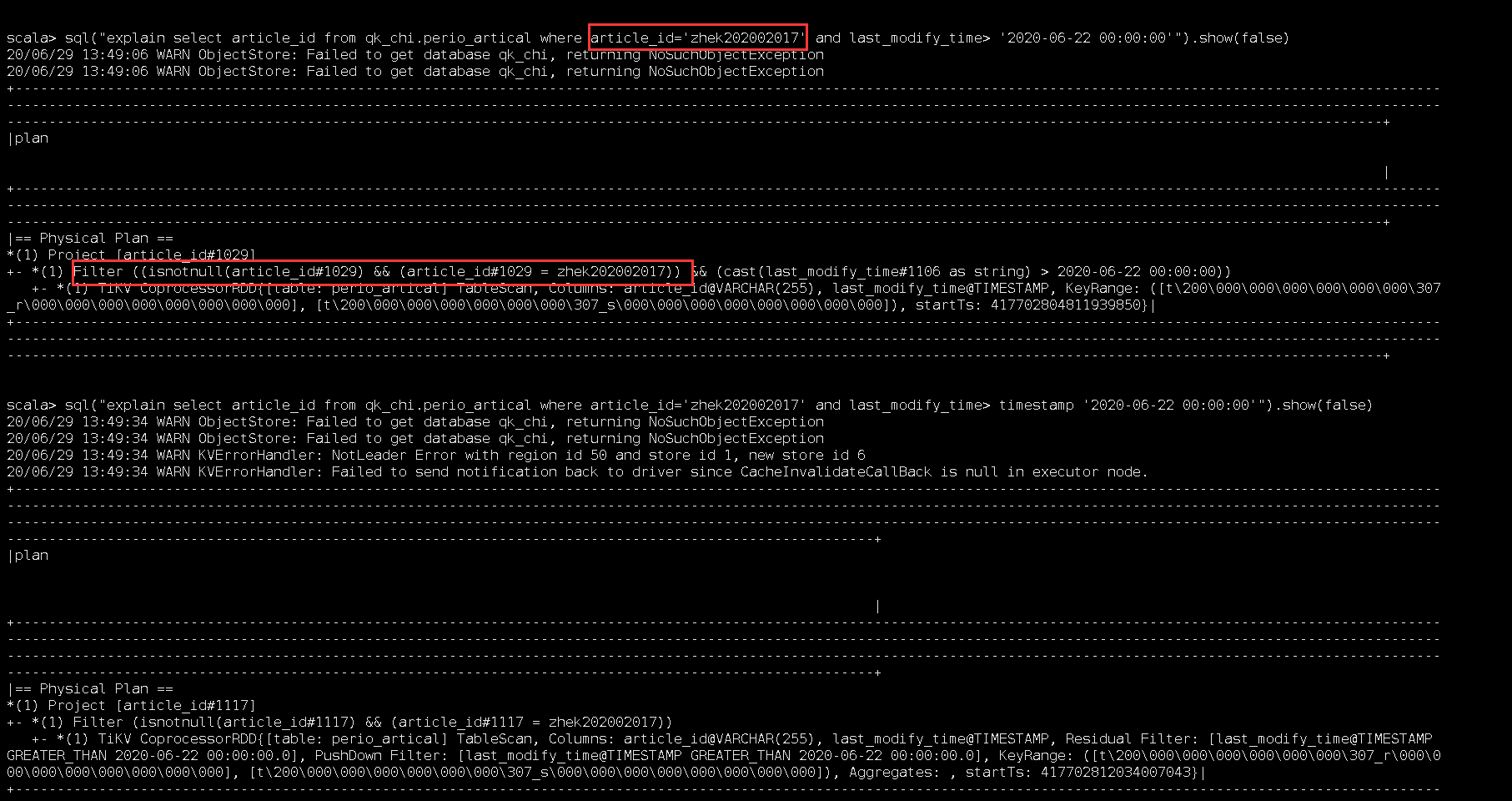
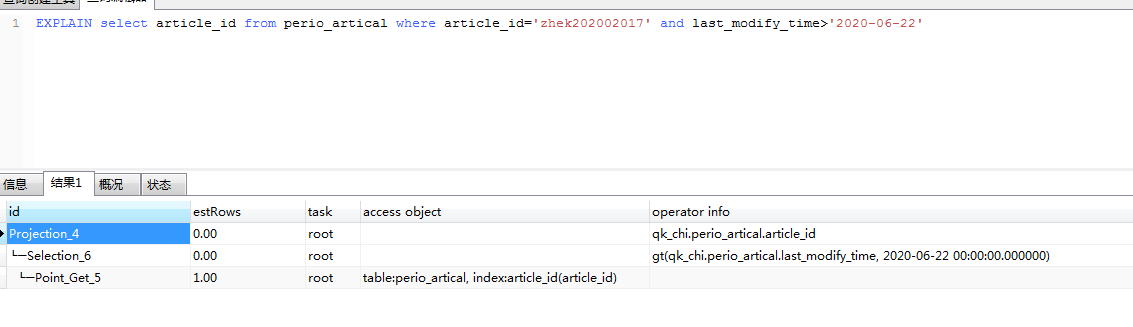
我们的读取语句为:select * from table where primary_partition >= 0 and primary_partition < 10000 and last_modify_time > ‘2020-06-22 14:34:19’ 所有分区大约1.2亿数据,时间过滤之后就很少了也就10几万数据。
在tidb3.x,tispark 2.1时,这样完全没有问题;升级到最新版之后,就报oom。然后把改成:select * from table where primary_partition >= 0 and primary_partition < 5000 and last_modify_time > ‘2020-06-22 14:34:19’ 和
select * from table where primary_partition >= 5000 and primary_partition < 10000 and last_modify_time > ‘2020-06-22 14:34:19’ 分两个批次执行,就可以。
是不是新版tispark这里没有把计算推到存储底层,直接就返回了