我用delete删除1 GB的数据会提示binlog过大,写入tikv的kv size限制理论多大?

大小限制可以看下这里 https://github.com/pingcap/tidb/blob/master/config/config.toml.example#L246
顺便上一个问题,
`但是实际遇到了savepoint被更新了,而且kafka也有数据进来`
如果这个情况发生了,应该是比较严重的 bug , 能帮忙确认下吗?

目前没有其它配置了,txn-total-size-limit 这里限制的是 tidb 往 tikv 写入的大小,如果是 delete 的话,这个大小只统计了 key ,不包含 value, 但是 binlog 这里是包含 value 的,所以会产生大于1G的情况。
现在遇到的问题是卡住过不去了,对吗?
这种情况下就会发生数据丢失
卡住过不去的问题,可以解决,改kafka配置(1G,有点大),或者想办法从上游限制binlog,但是生产出现drainer由于message过大,卡住就算了,结果重启若干次以后出现kafka有数据进来了
这个drainer重启若干次,理论上也不会往kafka发数据,这块如果有 debug 日志的话,我们排查下
生产的kafka已经切换了,复现到会跟帖,那我现在有什么配置去限制binlog大小吗

从监控看,像是没有数据同步到下游,最后是一条直线,实际上只有两个点
最后的直线是正常的,符合预期,但是根据对应时间6/22 12:45 的日志,是有数据到下游的
这里是说 12:45:40 发生了中断之后,还是有数据到下游了吗?监控上看不太出来,最好有日志确认
你好,我这边又发生了binlog同步被跳过的问题,Pump的GC周期是2天,23号有1.0 GB的binlog推送失败,后面一直没有管drainer,也没有放大下游的kafka配置,现在drainer已经正常推送了,按理说应该卡在1.0GB的binlog吧
drainer日志(debug日志不全,由于debug日志输入太多,期间关闭过debug):
链接:https://pan.baidu.com/s/1dYY7y9HOoe9jE70Z4nDYYQ
提取码:2fec
ok,你的问题已收到,链接下载速度较慢,这边分析有进展会及时更新帖子。
pump GC 时间是两天的话,那么可能是情况是 pump GC 掉了 1G 的 binlog, 然后 drainer 重启后更新了 GC 后的 checkpoint, 现在应该是发生了丢失。具体我再看日志确认下。
1 个赞
请问,现在有什么配置能够硬限制binlog产生的大小吗, txn-total-size-limit能够实现?
目前没有了,可以参考之前的回答https://asktug.com/t/topic/35495/45?u=luancheng-pingcap



drainer debug日志
链接:百度网盘-链接不存在
提取码:pd1g
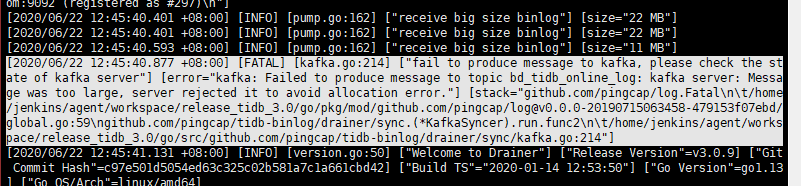
出现这个报错,但是kafka正常有数据进来,drainer不断重启,检查kafka状态正常,topic 配置message大小是1G,日志中附带drainer配置。
你好
- 如果调整 kafka 之后,还是超过了 kafka 的最大 msg 的限制,看是否可以再次调大些
- 否则可以修改程序,减小 drainer 的 msg 的写入大小