链接:https://pan.baidu.com/s/1ggTGBDnQ8nzaXd_uYNH0Bw
提取码:oyso
@户口舟亢
你好,该页面不存在,请核实下。
ok,已收到
你好,
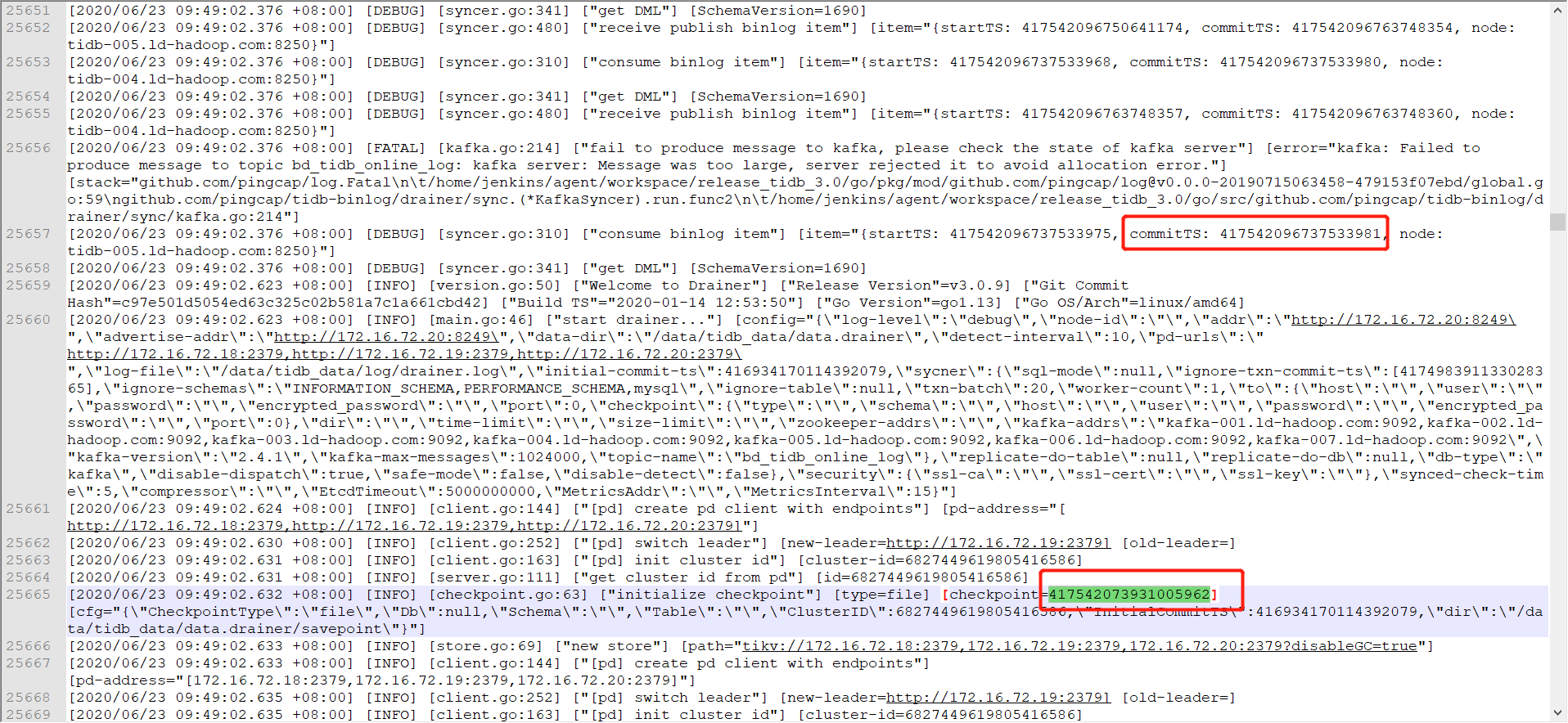
drainer 重启之后会根据 checkpoint 开始 5min 的 safe mode 插入数据,从日志中,
红色框代表重启前的 commit ts > 绿色框代表重启后初始化的 commit ts ,是预期的。目前 drainer 在不断的重启,原因是:
[error=“kafka: Failed to produce message to topic bd_tidb_online_log: kafka server: Message was too large, server rejected it to avoid allocation error.”]
所以需要调整 kafka message 大小,
https://docs.pingcap.com/zh/tidb/v4.0/handle-tidb-binlog-errors

好的,感谢
ok。
绿色框是从savepoint文件中读取的?
对于 kafka 下游来说,是从 pb 文件中读取的
我最后梳理下,因为一条message过大了,目前可以通过kafka放开限制解决,但是如果过大的导致drainer不断重试,最后会退出,systemd会重新拉起drainer,这时候按照上述,会读取pb文件tso,并以此为基准做最近5分钟的safe mode数据插入,请问是这样的吗
但是目前遇到savepoint在有过大binlog未同步过去(drainer不断重启)的时候,还是被更新的情况,正常否,会是啥原因导致的;针对kafka类型的下游,safe mode机制是不生效的,这个我在测试中也没有复现(先插入、update,然后调小kafka message配置,导致大binlog没有同步的报错后,drainer重试重启都没有发现有五分钟前的数据进入kafka)
假设 fatal commit ts 为 100,drainer 重启后会从一个早的 checkpoint 开始同步,到了 100 ts 又会中断.
这边出现fatal报错后,但是仍然能够继续同步数据到kafka,这会是什么情况; 如你所说,我也验证了一下,首先,正常生成binlog并从kafka去消费,然后调小kafka message后,出现一条fatal告诉你message过大,记录savepoint到文件,无论是重试还是重启drainer,根据drainer日志和下游kafka最新消费,发现都不会有历史(更早的一段时间 ts)数据产生
drainer重启之后,我认为的是有savepoint文件记录的tso肯定权重高于drainer配置的initial_ts,如果这时候
从更早时间开始同步,是否也会去更新这个文件呢
此为 replace int 覆盖插入,会重新获取 commit ts,不会有新的数据插入。
是的,当找不到 checkpoint ,则会从 init ts 拉取数据。
这里的更早的时间指的是什么操作
指的是 早一点的savepoint开始同步
这里说的safe mode是对kafka不生效的,这一点明确了,我也测试验证了,但是就是想知道明明日志已经提示fatal message过大,drainer重启重试也罢,这里理应卡住在这个savepoint,但是实际遇到了savepoint被更新了,而且kafka也有数据进来
这是卡住的时间点

这是savepoint的时间(期间drainer不断重启重试,savepoint没有手动更新过)
drainer日志
链接:百度网盘-链接不存在
提取码:4md3
从这个日志中看到,06/24 00:24 的时候 drainer 就已经不断重启,卡在 checkpoint 417566177481982008 这里了,直到 06/24 10:30 checkpoint 都没更新过。理论上没有数据发送才对。
`但是实际遇到了savepoint被更新了,而且kafka也有数据进来`
这里能不能给这个不断重启的 drainer 开启 debug 日志,如果这个 drainer 给 kafka 发送了消息,就会打印一个 debug 日志。关键字 get success msg from producer。就能表明是这个 drainer 发送了消息。