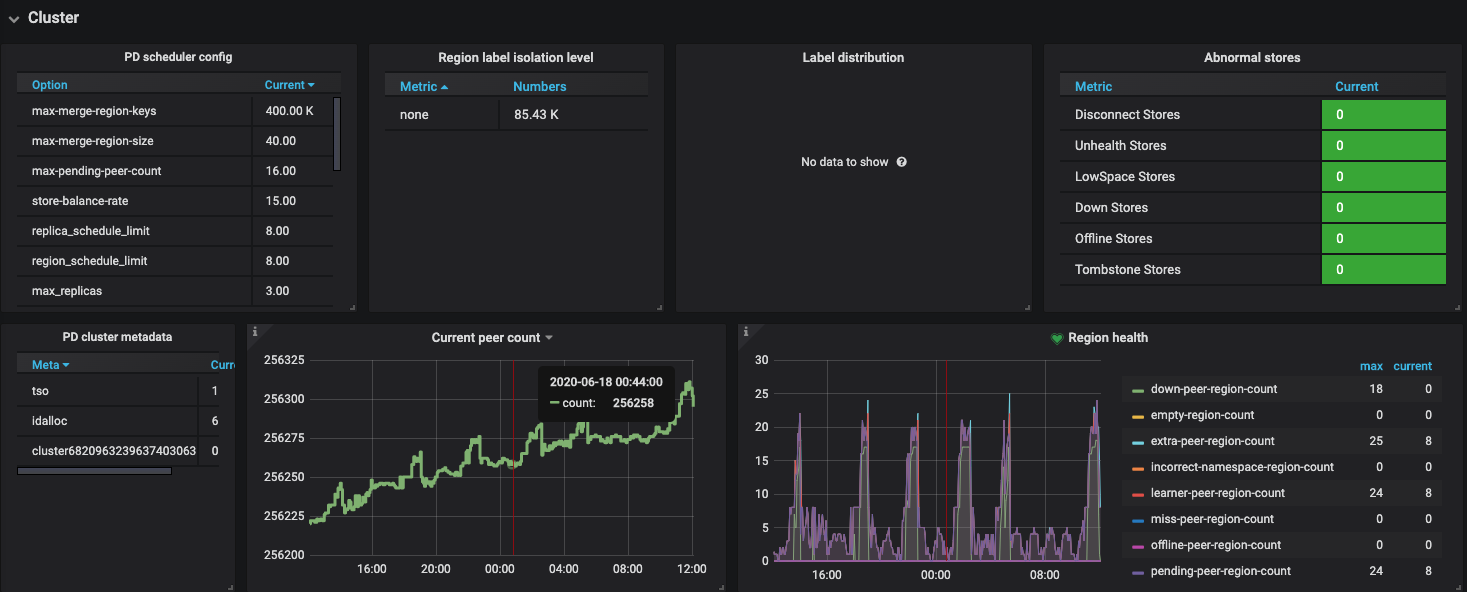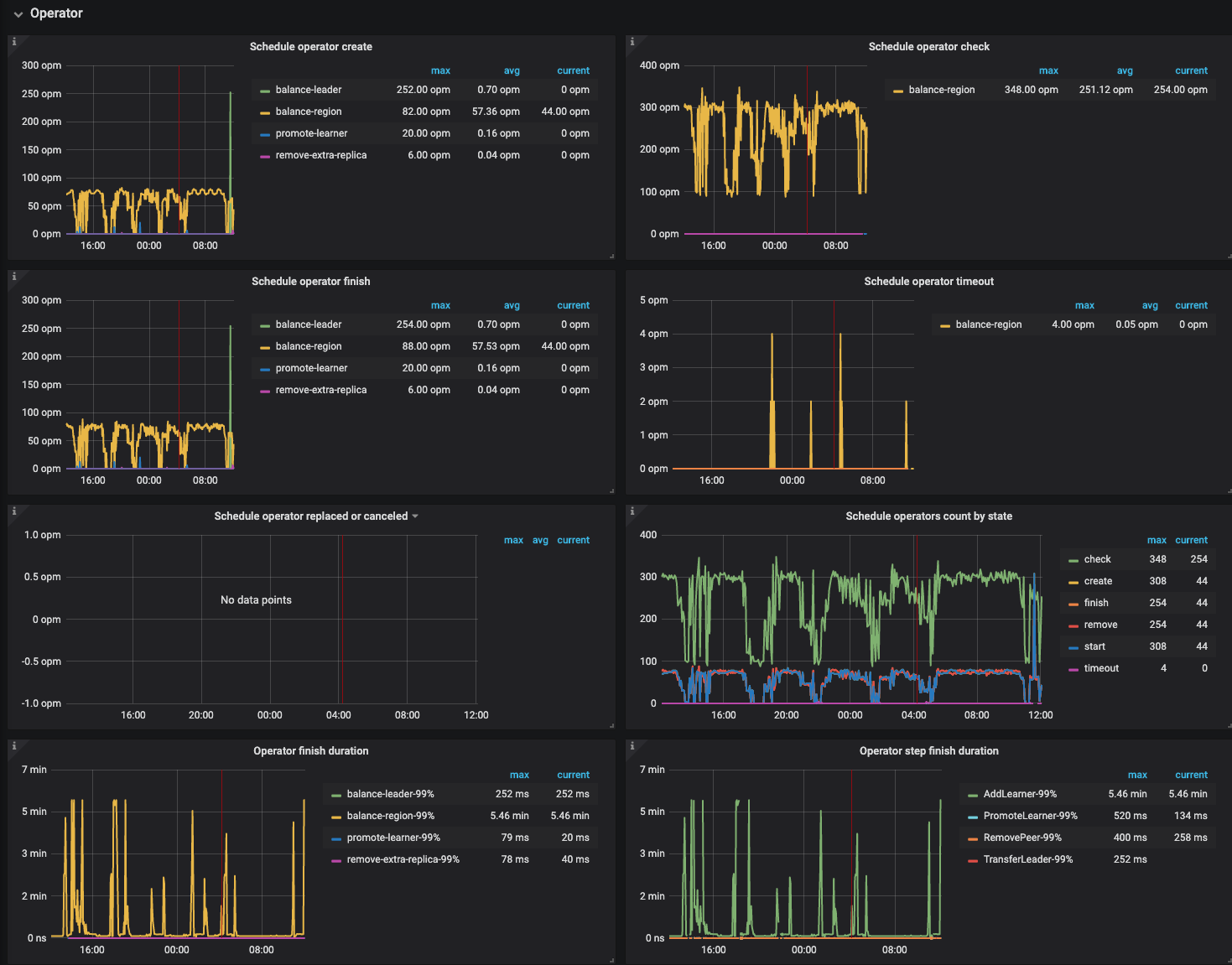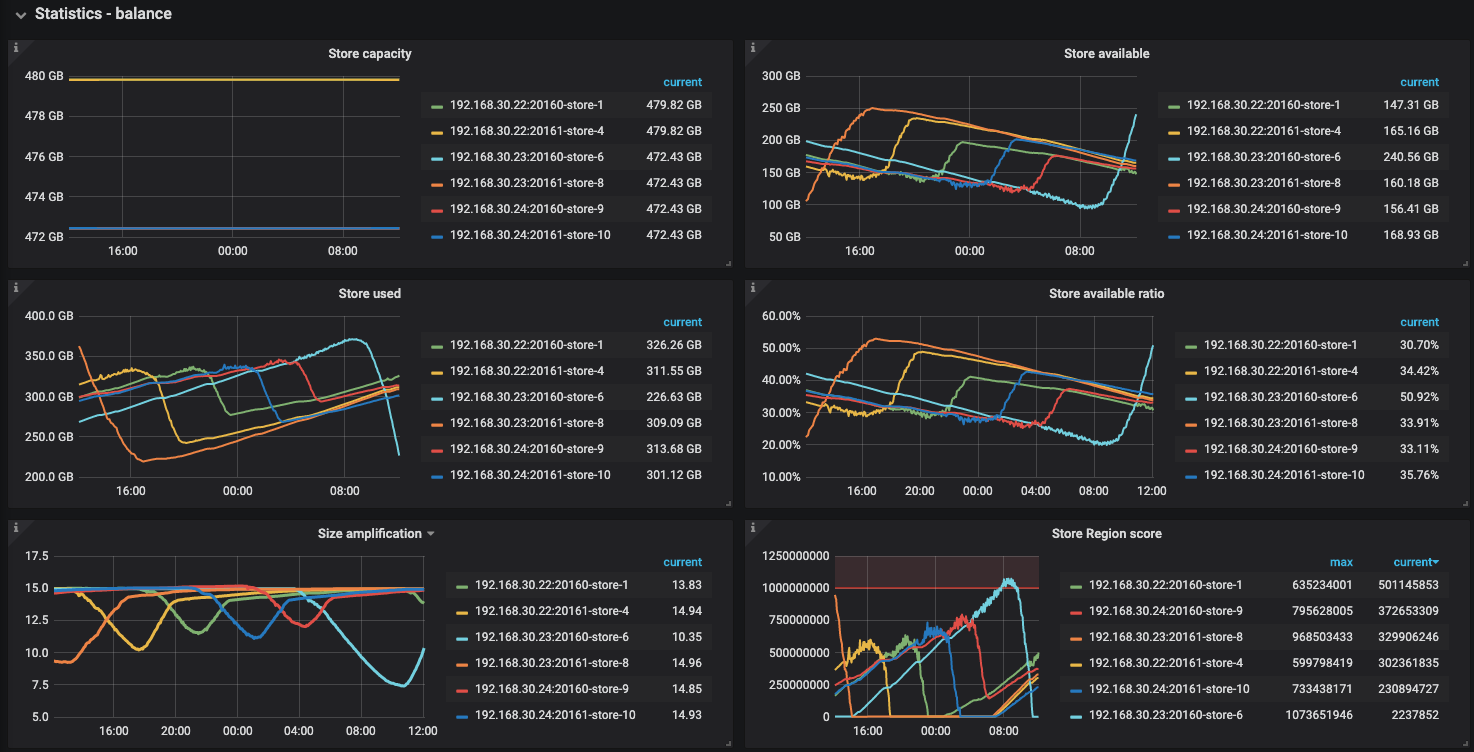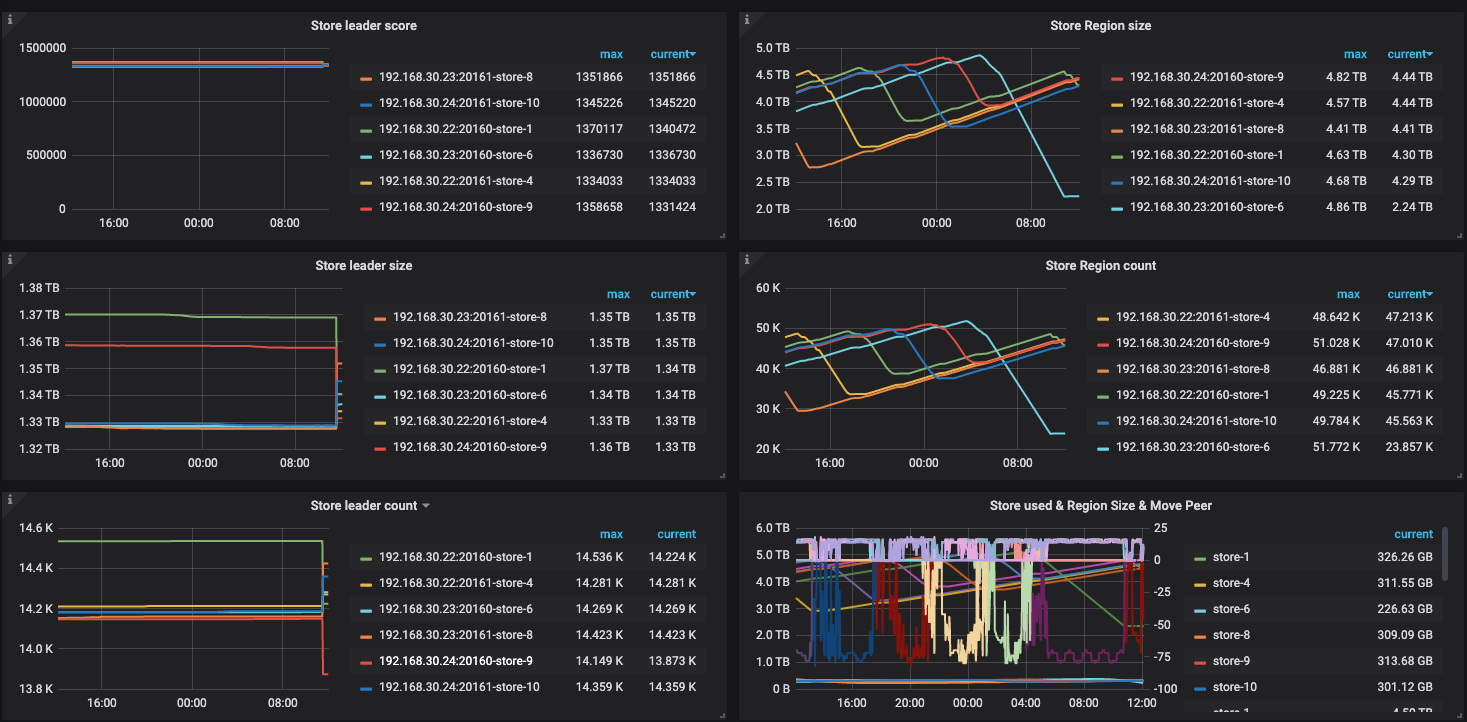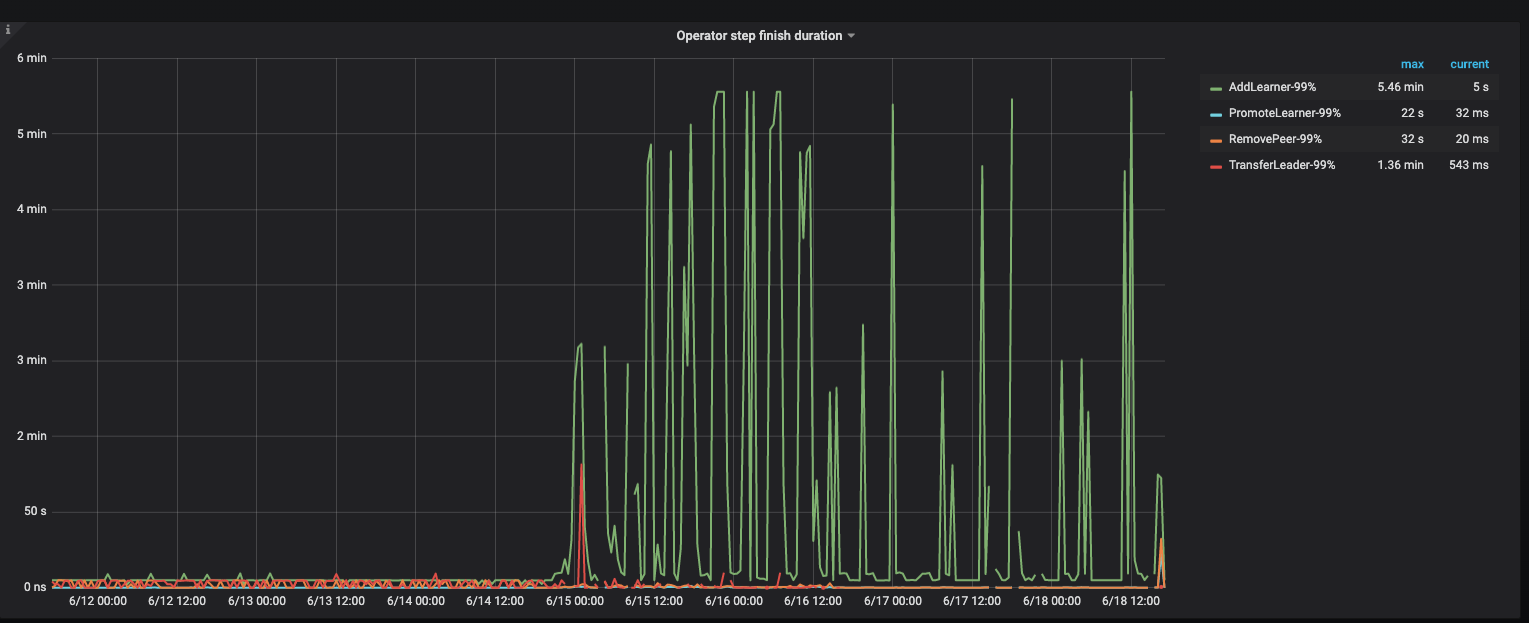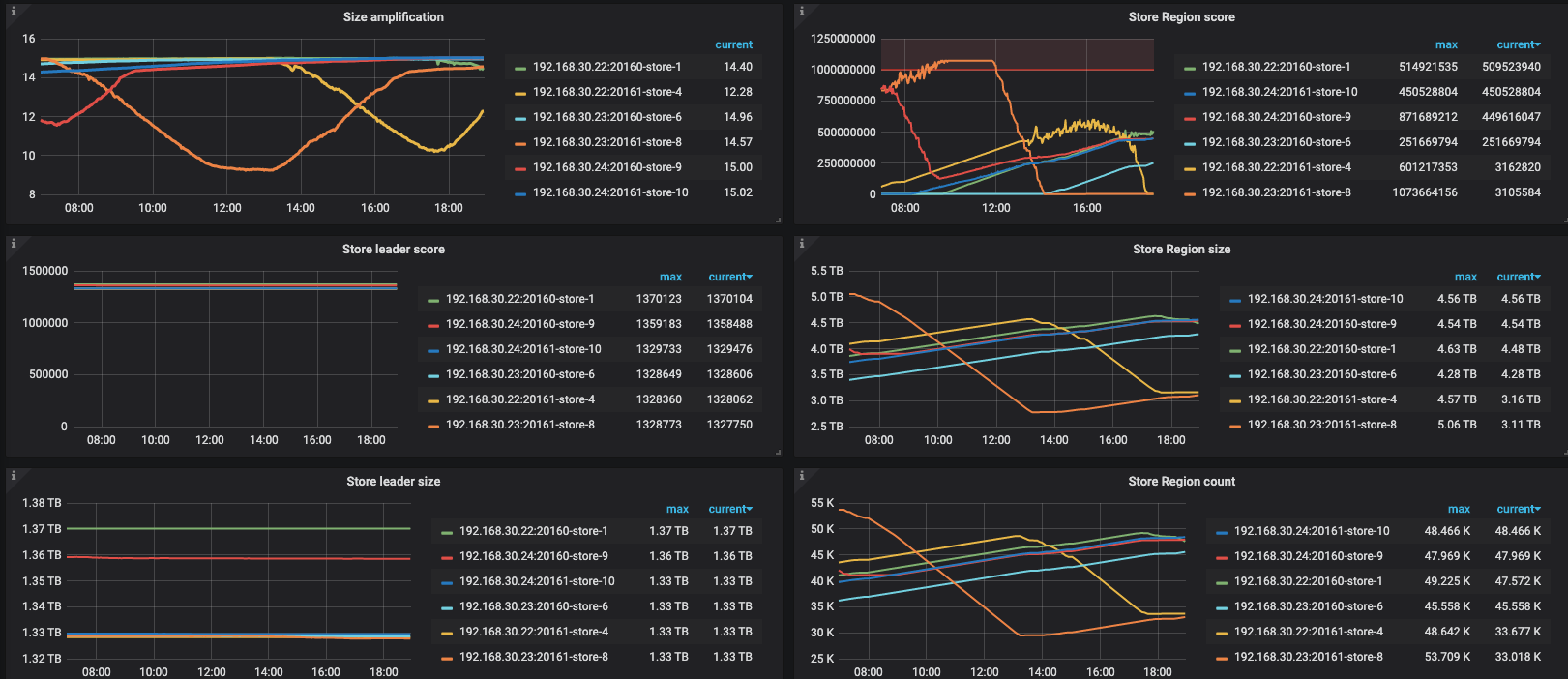
最近 12 小时的监控,没有数据写入和访问, region 不停变化
最近一个礼拜一直在持续的写入数据(100 worker 左右, 每个 worker key 顺序写入, 会写入同一个 key ), 最近写入了变慢一个数量级, 看了下从 15 号开始 region 不平衡, 16 号下午开始把访问数据的访问和写入都切掉了, 但 socre 的震荡还是一直在持续, 请问下这个是什么原因
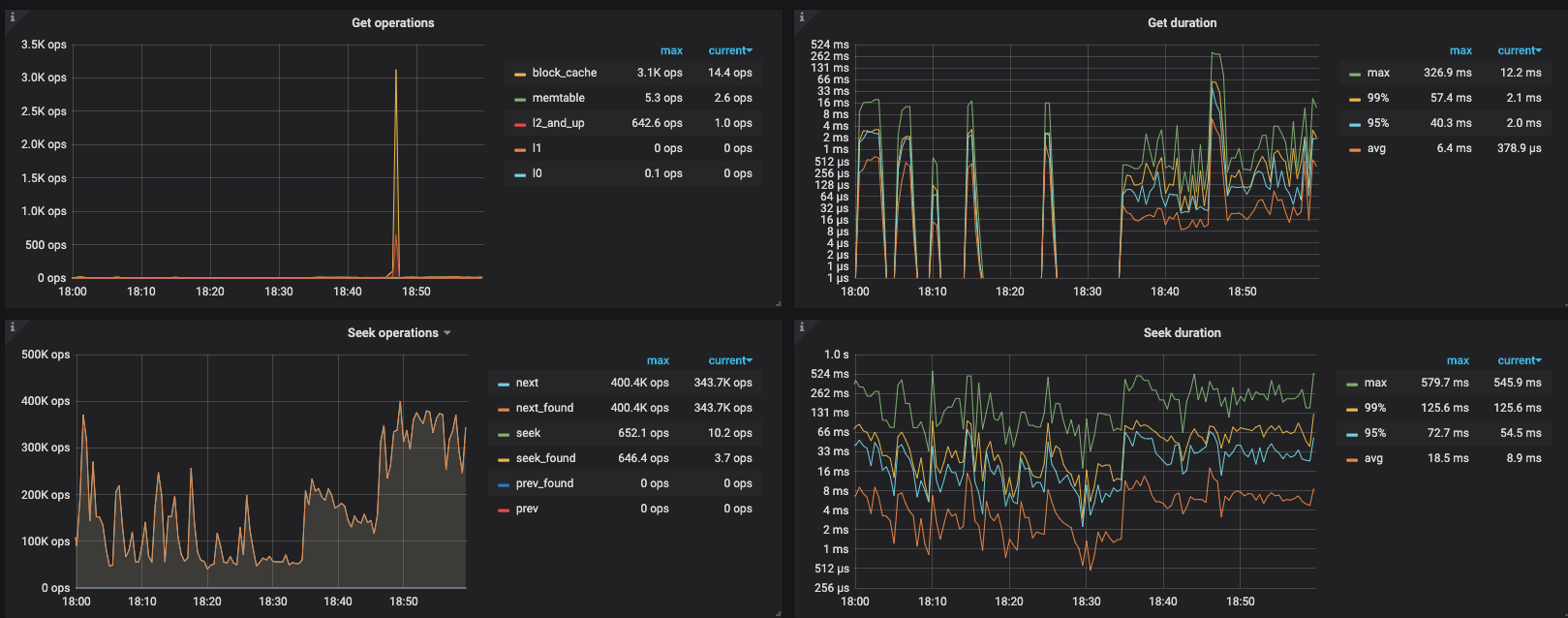
测试对应的 key 会发现,访问比之前变慢一个数量级
最近 12 小时的监控,没有数据写入和访问, region 不停变化
最近一个礼拜一直在持续的写入数据(100 worker 左右, 每个 worker key 顺序写入, 会写入同一个 key ), 最近写入了变慢一个数量级, 看了下从 15 号开始 region 不平衡, 16 号下午开始把访问数据的访问和写入都切掉了, 但 socre 的震荡还是一直在持续, 请问下这个是什么原因
测试对应的 key 会发现,访问比之前变慢一个数量级
很多 key 有过一次重复写入, 不知道这个有没有影响
1.pd-ctl 麻烦反馈 store 信息
2. 请检查pd 和 tikv 监控是否有很多empty region
3.停止了写入,是否还有DDL操作?
pd-ctl store
{
"count": 6,
"stores": [
{
"store": {
"id": 4,
"address": "192.168.30.22:20161",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "446.9GiB",
"available": "160.1GiB",
"leader_count": 14213,
"leader_weight": 1,
"leader_score": 1327651,
"leader_size": 1327651,
"region_count": 46185,
"region_weight": 1,
"region_score": 226976994.71655273,
"region_size": 4342376,
"start_ts": "2020-06-10T16:45:40+08:00",
"last_heartbeat_ts": "2020-06-18T10:23:52.085565812+08:00",
"uptime": "185h38m12.085565812s"
}
},
{
"store": {
"id": 6,
"address": "192.168.30.23:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "440GiB",
"available": "122.8GiB",
"leader_count": 14182,
"leader_weight": 1,
"leader_score": 1328526,
"leader_size": 1328526,
"region_count": 25452,
"region_weight": 1,
"region_score": 650252567.7834144,
"region_size": 2385935,
"start_ts": "2020-06-10T16:57:57+08:00",
"last_heartbeat_ts": "2020-06-18T10:23:48.426604269+08:00",
"uptime": "185h25m51.426604269s"
}
},
{
"store": {
"id": 8,
"address": "192.168.30.23:20161",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "440GiB",
"available": "155.3GiB",
"leader_count": 14160,
"leader_weight": 1,
"leader_score": 1327679,
"leader_size": 1327679,
"region_count": 45866,
"region_weight": 1,
"region_score": 255583800.11687088,
"region_size": 4315971,
"start_ts": "2020-06-10T16:57:49+08:00",
"last_heartbeat_ts": "2020-06-18T10:23:52.157645579+08:00",
"uptime": "185h26m3.157645579s"
}
},
{
"store": {
"id": 9,
"address": "192.168.30.24:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "440GiB",
"available": "149.4GiB",
"leader_count": 14149,
"leader_weight": 1,
"leader_score": 1357732,
"leader_size": 1357732,
"region_count": 46014,
"region_weight": 1,
"region_score": 327307175.9844165,
"region_size": 4349493,
"start_ts": "2020-06-10T16:44:22+08:00",
"last_heartbeat_ts": "2020-06-18T10:23:52.3974021+08:00",
"uptime": "185h39m30.3974021s"
}
},
{
"store": {
"id": 10,
"address": "192.168.30.24:20161",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "440GiB",
"available": "162.8GiB",
"leader_count": 14186,
"leader_weight": 1,
"leader_score": 1328751,
"leader_size": 1328751,
"region_count": 44519,
"region_weight": 1,
"region_score": 164377415.5195179,
"region_size": 4189403,
"start_ts": "2020-06-10T16:44:32+08:00",
"last_heartbeat_ts": "2020-06-18T10:23:52.325809492+08:00",
"uptime": "185h39m20.325809492s"
}
},
{
"store": {
"id": 1,
"address": "192.168.30.22:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "446.9GiB",
"available": "145.9GiB",
"leader_count": 14536,
"leader_weight": 1,
"leader_score": 1369013,
"leader_size": 1369013,
"region_count": 48242,
"region_weight": 1,
"region_score": 397143881.27116966,
"region_size": 4534878,
"start_ts": "2020-06-10T16:45:32+08:00",
"last_heartbeat_ts": "2020-06-18T10:23:51.597570185+08:00",
"uptime": "185h38m19.597570185s"
}
}
]
}
region health 的情况如下
3.停止了写入,是否还有DDL操作?
没有了外部操作,也没有部署 tidb, 只有 pd 和 tikv
查看region size,store": { “id”: 6, “address”: “192.168.30.23:20160” 差距较大,但是可用空间和其他实例差不多,麻烦查看下这个实例的安装目录下,是否有其他文件占用了空间,多谢。

如果没有,麻烦上传完整的pd监控,多谢。
麻烦您上传下store 6 即23 这个tikv.log 日志,多谢。一段时间的即可,看下再做什么操作。
请问这个是什么版本,可以帮忙把 pdctl>> config show all 配置发一下
版本是 3.0.12 , 担心这个版本是不是有问题, 刚滚动升级到了最近的版本, 但因为刚升级还没看出来是否还存在这个问题
配置升级的时候没做修改
{
"client-urls": "http://192.168.30.22:2379",
"peer-urls": "http://192.168.30.22:2380",
"advertise-client-urls": "http://192.168.30.22:2379",
"advertise-peer-urls": "http://192.168.30.22:2380",
"name": "pd02",
"data-dir": "/pd02",
"force-new-cluster": false,
"enable-grpc-gateway": true,
"initial-cluster": "pd02=http://192.168.30.22:2380,pd03=http://192.168.30.23:2380,pd04=http://192.168.30.24:2380",
"initial-cluster-state": "new",
"join": "",
"lease": 3,
"log": {
"level": "info",
"format": "text",
"disable-timestamp": false,
"file": {
"filename": "/log/pd.log",
"max-size": 300,
"max-days": 0,
"max-backups": 0
},
"development": false,
"disable-caller": false,
"disable-stacktrace": false,
"disable-error-verbose": true,
"sampling": null
},
"tso-save-interval": "3s",
"metric": {
"job": "pd02",
"address": "",
"interval": "15s"
},
"schedule": {
"max-snapshot-count": 3,
"max-pending-peer-count": 16,
"max-merge-region-size": 40,
"max-merge-region-keys": 400000,
"split-merge-interval": "1h0m0s",
"enable-one-way-merge": "false",
"enable-cross-table-merge": "false",
"patrol-region-interval": "100ms",
"max-store-down-time": "30m0s",
"leader-schedule-limit": 2,
"leader-schedule-policy": "count",
"region-schedule-limit": 8,
"replica-schedule-limit": 8,
"merge-schedule-limit": 2,
"hot-region-schedule-limit": 2,
"hot-region-cache-hits-threshold": 3,
"store-balance-rate": 15,
"tolerant-size-ratio": 0,
"low-space-ratio": 0.8,
"high-space-ratio": 0.6,
"scheduler-max-waiting-operator": 3,
"enable-remove-down-replica": "true",
"enable-replace-offline-replica": "true",
"enable-make-up-replica": "true",
"enable-remove-extra-replica": "true",
"enable-location-replacement": "true",
"enable-debug-metrics": "false",
"schedulers-v2": [
{
"type": "balance-region",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "balance-leader",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "hot-region",
"args": null,
"disable": false,
"args-payload": ""
},
{
"type": "label",
"args": null,
"disable": false,
"args-payload": ""
}
],
"schedulers-payload": {
"balance-hot-region-scheduler": "null",
"balance-leader-scheduler": "{\"name\":\"balance-leader-scheduler\",\"ranges\":[{\"start-key\":\"\",\"end-key\":\"\"}]}",
"balance-region-scheduler": "{\"name\":\"balance-region-scheduler\",\"ranges\":[{\"start-key\":\"\",\"end-key\":\"\"}]}",
"label-scheduler": "{\"name\":\"label-scheduler\",\"ranges\":[{\"start-key\":\"\",\"end-key\":\"\"}]}"
},
"store-limit-mode": "manual"
},
"replication": {
"max-replicas": 3,
"location-labels": "",
"strictly-match-label": "false",
"enable-placement-rules": "false"
},
"pd-server": {
"use-region-storage": "true",
"max-gap-reset-ts": "24h0m0s",
"key-type": "table",
"runtime-services": "",
"metric-storage": "",
"dashboard-address": "http://192.168.30.24:2379"
},
"cluster-version": "4.0.1",
"quota-backend-bytes": "8GiB",
"auto-compaction-mode": "periodic",
"auto-compaction-retention-v2": "1h",
"TickInterval": "500ms",
"ElectionInterval": "3s",
"PreVote": true,
"security": {
"cacert-path": "",
"cert-path": "",
"key-path": "",
"cert-allowed-cn": []
},
"label-property": {},
"WarningMsgs": null,
"DisableStrictReconfigCheck": false,
"HeartbeatStreamBindInterval": "1m0s",
"LeaderPriorityCheckInterval": "1m0s",
"dashboard": {
"tidb_cacert_path": "",
"tidb_cert_path": "",
"tidb_key_path": "",
"public_path_prefix": "",
"internal_proxy": false
},
"replication-mode": {
"replication-mode": "majority",
"dr-auto-sync": {
"label-key": "",
"primary": "",
"dr": "",
"primary-replicas": 0,
"dr-replicas": 0,
"wait-store-timeout": "1m0s",
"wait-sync-timeout": "1m0s"
}
}
}
是什么时候升级的呢,升级之后是什么版本还有这个现象呢?
麻烦看下私信,多谢。
这个问题有结果么?数据量过了磁盘60%之后无法正常balance。完全停不下来。