
tidb添加配置proxy-protocol.networks: “*” 配置,haproxy添加 send-proxy配置后,tidb日志报错
你好,
参考下下面的帖子看是否有帮助
传透生效了,但还是有报错提醒,networks已经设置为*,haproxy配置也修改了,请问可能会是什么原因造成的
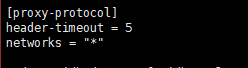 在配置文件中添加的
在配置文件中添加的
你好,
- tidb 的版本和 haproxy 版本提供下
- tidb.log 中的报错信息希望提供的再多一些,譬如上下 20 行。
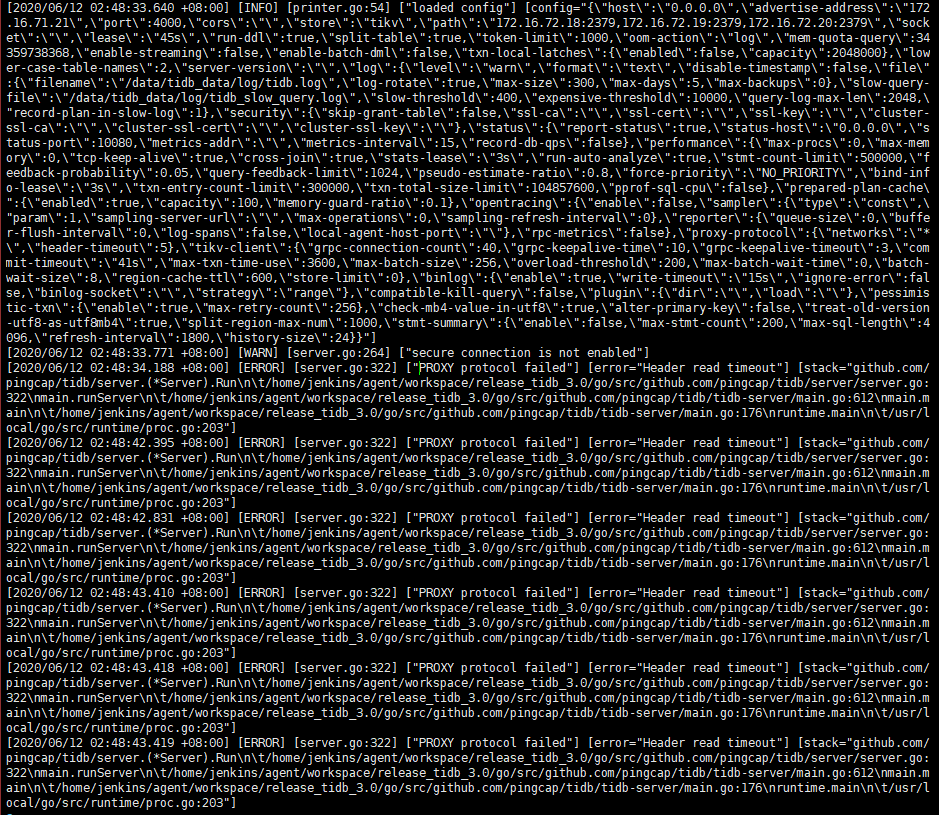
你好,目前的问题是,透传连接能够建立成功和工作,但是 tidb log 里面总是有 read header timeout 的报错对么?
你好,目前是的
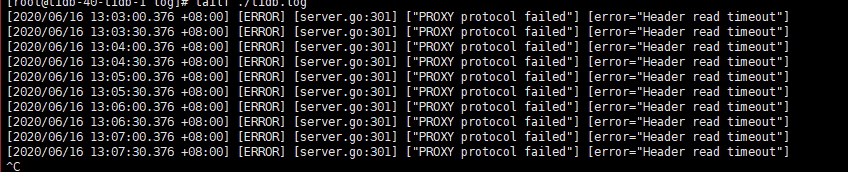
本地没复现出来,可否把配置文件去掉关键信息上传一下。另外客户端连接数大概有多少,会并发很多么?
TiDB Configuration.
compatible-kill-query = false
enable-streaming = false
host = “0.0.0.0”
lease = “45s”
lower-case-table-names = 2
oom-action = “log”
run-ddl = true
socket = “”
split-table = true
store = “tikv”
token-limit = 1000
[log]
disable-timestamp = false
expensive-threshold = 10000
format = “text”
level = “warn”
query-log-max-len = 2048
slow-threshold = 1000
[log.file]
log-rotate = true
max-backups = 0
max-days = 5
max-size = 300
[security]
cluster-ssl-ca = “”
cluster-ssl-cert = “”
cluster-ssl-key = “”
ssl-ca = “”
ssl-cert = “”
ssl-key = “”
[status]
report-status = true
[performance]
cross-join = true
feedback-probability = 0.05
force-priority = “NO_PRIORITY”
max-procs = 0
pseudo-estimate-ratio = 0.8
query-feedback-limit = 1024
run-auto-analyze = true
stats-lease = “3s”
stmt-count-limit = 500000
tcp-keep-alive = true
[proxy-protocol]
header-timeout = 5
networks = “*”
[prepared-plan-cache]
capacity = 100
enabled = true
memory-guard-ratio = 0.1
[opentracing]
enable = false
rpc-metrics = false
[opentracing.reporter]
buffer-flush-interval = 0
local-agent-host-port = “”
log-spans = false
queue-size = 0
[opentracing.sampler]
max-operations = 0
param = 1.0
sampling-refresh-interval = 0
sampling-server-url = “”
type = “const”
[tikv-client]
commit-timeout = “41s”
grpc-connection-count = 40
grpc-keepalive-time = 10
grpc-keepalive-timeout = 3
max-batch-size = 256
max-txn-time-use = 3600
[txn-local-latches]
capacity = 2048000
enabled = false
[binlog]
ignore-error = false
write-timeout = “15s”
[pessimistic-txn]
enable = true
max-retry-count = 256
ttl = “30s”
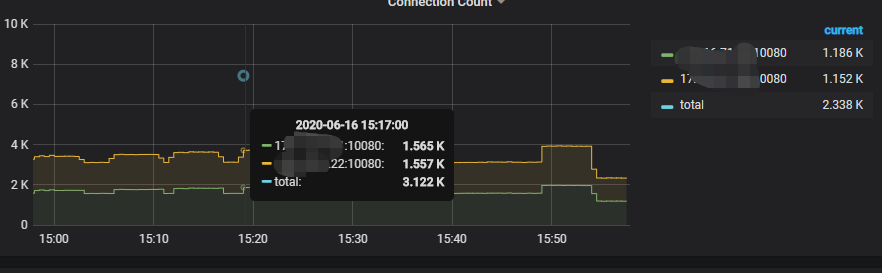
你好,这是目前的并发连接情况
检查一下 TiDB 集群是否有其他 没有使用 protocol-proxy 协议来连接 TiDB 集群的应用程序,如果使用通常的 mysql 协议直连 开启 protocol-proxy 协议的 TiDB 集群,会得到如下报错
[ERROR] [server.go:301] ["PROXY protocol failed"] [error="Header read timeout"]
开了proxy-protocol之后,来4000端口的连接会报这个问题,如果来自haproxy代理的连接不会有问题,是这样吧?
对,TiDB 开启了 proxy-protocol 协议之后,只能处理来自 haproxy 的连接

如果觉得是内部的,可以停掉haproxy和业务,看下是否还有报错日志,多谢。
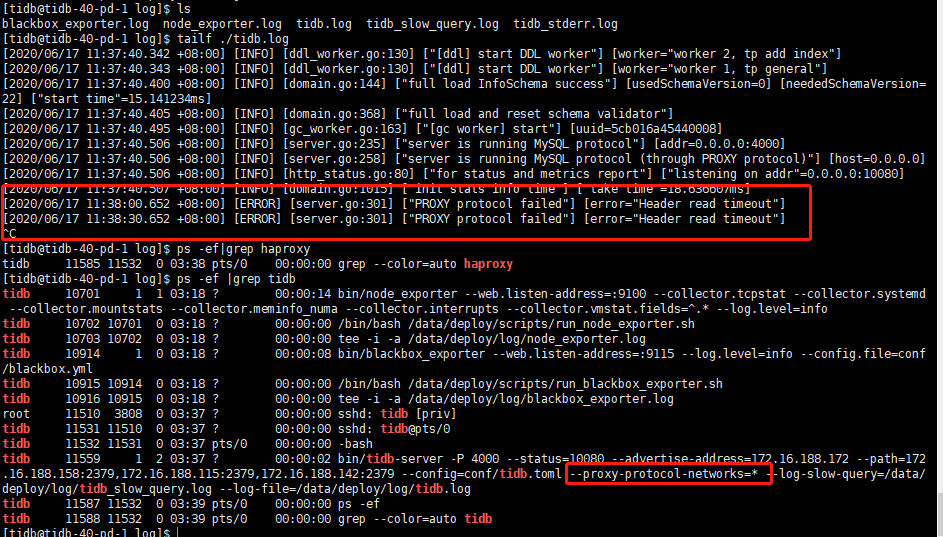
有可能是 TiDB 4.0 DASHBOARD 直连 TiDB
这个 proxy-protocol-networks 的作用是:
- 对 ip 列表里的连接者必须使用 proxy 协议
- 对于不再 ip 列表里的链接者不能使用 proxy 协议但可以直接连接
你这配置了 * , 所以效果就是要求所有人必须用 proxy 协议走 proxy。。。
解决办法是不配置 *, 只需要把你的 haproxy ip 配置到列表里即可
对, 按照目前这个配置 dashboard 是会不可用