为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:
- 【问题描述】:
我从2.1.15升级到3.0.12,在2版本中,执行truncate table,不管表数据量多大,很快就执行结束了,就好像是后台任务似的。但是在3版本中,执行truncate table需要很久的时间,不知道是我系统问题还是新版本在这一方面进行了修改?另外想问一下,tidb4版本可以上生产系统了吗?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
我从2.1.15升级到3.0.12,在2版本中,执行truncate table,不管表数据量多大,很快就执行结束了,就好像是后台任务似的。但是在3版本中,执行truncate table需要很久的时间,不知道是我系统问题还是新版本在这一方面进行了修改?另外想问一下,tidb4版本可以上生产系统了吗?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
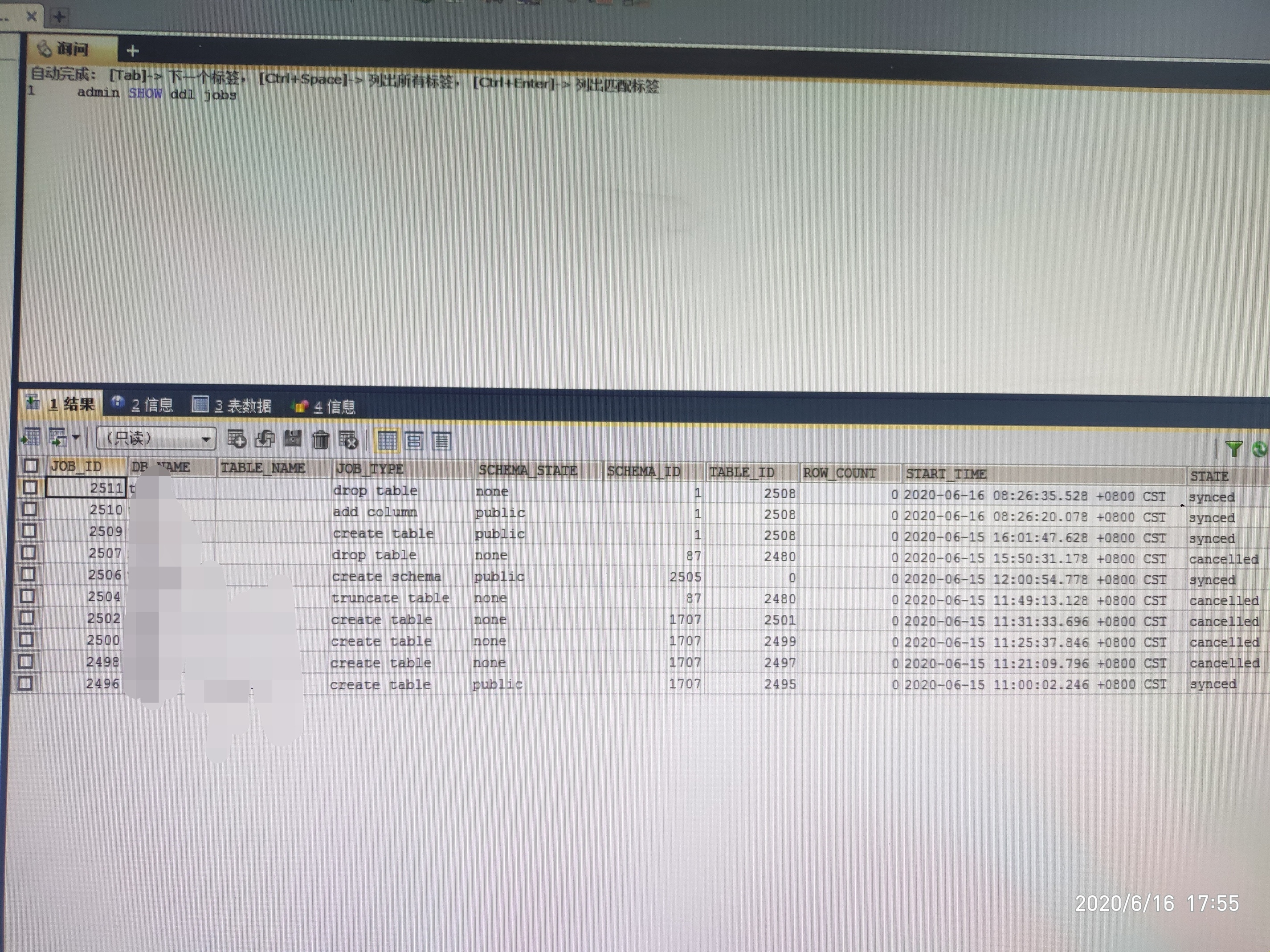
我今天看了一下,貌似所有的ddl语句都没办法执行了,truncate table语句一直没有把表清空。之前是报错, GC life time is shorter than transaction duration,我把tikv_gc_life_time改为了1h,会不会和这个有关系呢?
你好,
truncate table 语句等同于 drop table 和 create table,此操作在 tidb 中执行时不会删除真实的诗句所以返回很快,在 gc 时才会进行数据删除。
提供下以上信息
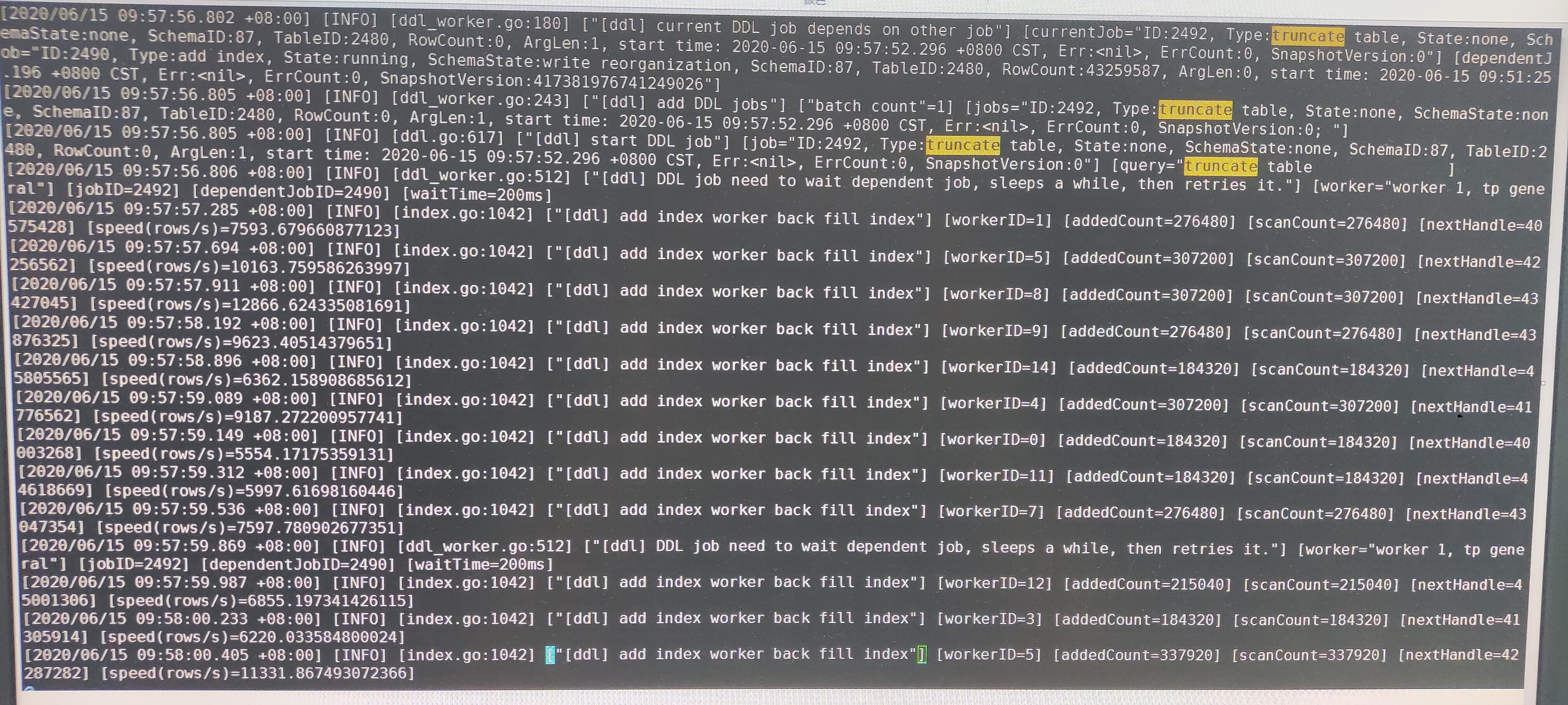
如果相同的表再执行多个DDL操作,是需要排队等待的。比如你有一个大表先执行了添加索引操作,之后又执行了truncate table 操作,这时需要等待添加索引完成后,才会执行truncate table 操作。你可以看下tidb.log 日志,是否是这种情况导致,多谢。
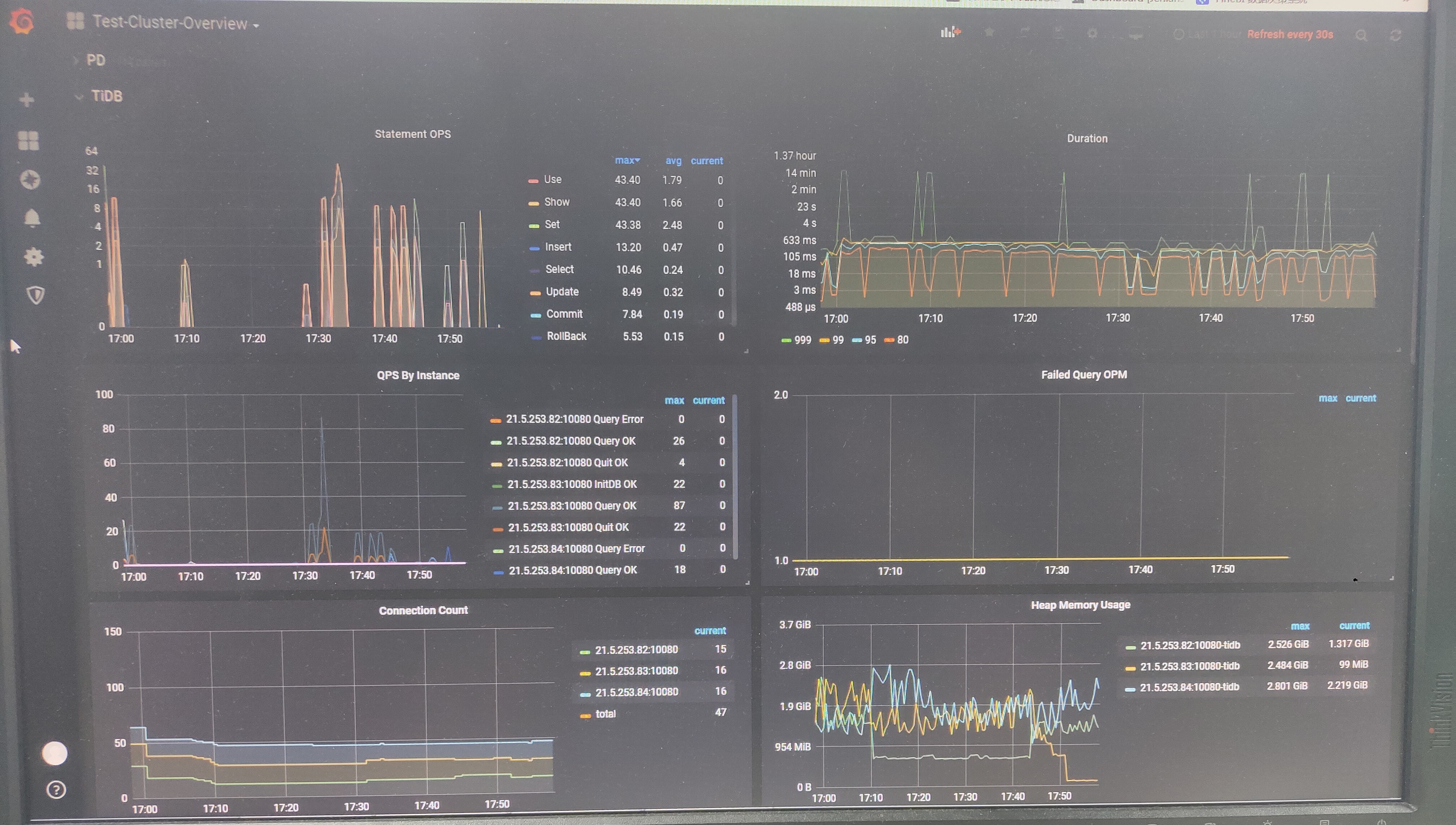
嗯,当时是有这种情况,可能是我操作太快了。我目前是打算拿使用tidb做我们现有数据库集群的备份,由于我们采用分表,所以我在tidb的目标表里,增加了分片表的ip、分片表名和分片表最大id,用来做增量同步。现在我已经同步43亿数据,发现统计单表最大id这一步极其慢,后来才想起来加索引。后来加索引之后,发现还是很慢,不知道哪里出问题了。
是否方便反馈一个查询的执行计划。
explain analyze 多谢。
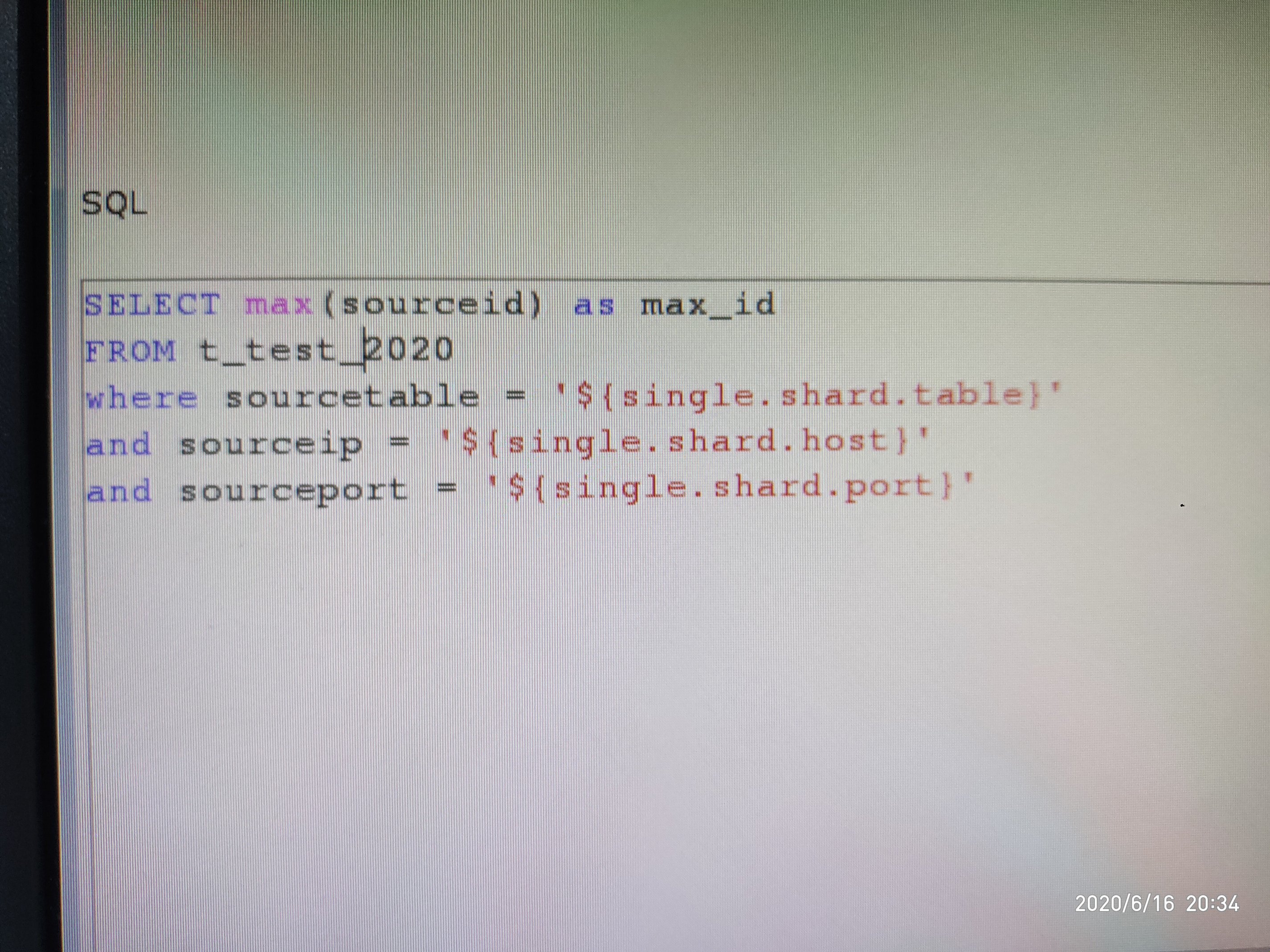
这张表现在已经大概六亿条数据了。我现在在做分片表的数据迁移。我之前用一张中间表记录同步信息,但是同步任务一旦出错,中间表和目标表的数据不一致了,所以我现在才在目标表里加上了分片表的信息,这样以后就可以对每个分片表实现增量同步了。where的三个条件我建立了联合索引,sourceid我也添加了索引,可是为什么还是这么慢呢?
这面的执行计划是否方便把表结构和完整sql发一下?
如果是这个sql,走的是索引sourceid。 按照您说的应该有一个where 条件的联合索引,感觉也不是很合适,没有包含需要查看的列 sourceid。 感觉如果可以联合索引包含 sourceid,可以直接在索引里选择出max值,不需要再回表,应该会快很多。
现在索引有两个,一个是idx_sourceid,一个是idx_table_ip_port,这个语句走的是idx_sourceid这个索引吗?这个执行计划我看不太懂。那我的索引应该怎么改才可以呢?
您可以试下如果索引走idx_table_ip_port会需要多久吗?
https://docs.pingcap.com/zh/tidb/v4.0/optimizer-hints#use_indext1_name-idx1_name--idx2_name-
感谢,查询速度一下子就上去了,秒查,太给力了!
好的,可以收集下统计信息,看看能否自动选择正确的索引,如果收集后也不行,暂时先固定使用索引吧。