云集财务业务TiDB实践
作者:皮雪锋 丁凌风
摘要:MySQL、HybridDB for MySQL、TiDB,是什么原因让我们不断变更财务数据库选型,TiDB为我们带了什么变革,本文将为你揭秘云集TiDB在云集的落地经历。
背景介绍
- 背景
- 财务业务上线: 公司在15-17年业务成爆发式增长,18年初开始做财务系统的规划,起初日均生成的财务数据量在10-20+万在小活动期间会翻2-3倍,大型活动翻4-5倍。
- 技术选型: 事务需求加上技术栈积累选用的是MySQL,根据财务商家结算维度做分表键分64张表存储。18年4月份预上线,5月份正式投入财务结算使用。
- 痛点: 18年Q4季度开始,日均数据量上升到40-50万+,加上分表维度是按商家维度存在热点数据,MySQL已经出现单表千万级数据量的超级大表。
- 方案探索:
- 冷热分离: 本来提出过冷热数据分离的方案,但是由于是18年初新建的财务系统,其他地方根本没有完整的数据,仅此一份孤本既提供给结算业务同时又提供给报表业务,两边对数据的需求完全不一样,需冷热分离的数据维度不同,结算对已结算的数据可以做冷数据分离,而报表又要以月度维度进行冷数据分离,导致冷热分离一直没有办法动工,除非做数据异构解耦两份数据。
- 数据异构: 但是数据异构又会带来非常大的研发成本,每存在一种业务场景需要异构一份财务数据,维护多份数据、保证多份数据的数据一致性,都会带来非常多新的工作量,这都是高昂的维护、开发成本
- 诉求: 所以急需一个可以应对多变业务、处理大数据量、带有事务能力的解决方案。
- 发展到19年初时的MySQL架构
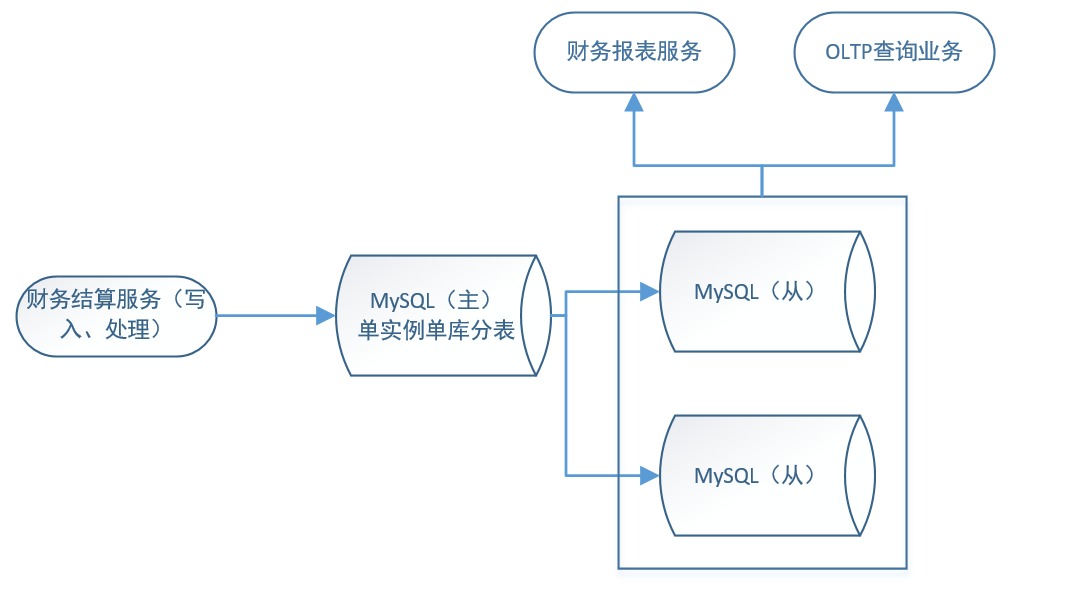
- 统计需求业务场景
| 业务场景 | 数据量 | 事务需求 | 数据时效性 | 冷热分离维度 |
|---|---|---|---|---|
| 结算OLTP业务 | 月均3000W+ | √ | T+1 | 已结算/未结算 |
| 财务月报、月度分析等OLAP业务 | 月均3000W+ | x | 低 | 月份 |
| 年度审计 | 年均3亿+ | x | 低 | 年份 |
| 对账平台 | 视接入业务而定,总量超过结算OLTP业务 | √ | T+1 | 月份 |
- 调研: 在这样的背景之下,我们从社区上了解到分布式数据库的存在,进行了分布式数据库的尝试与调研
数据库技术选型
基于这个业务背景下,考虑到当时公司一直用着阿里云的服务,我们首先选择的是阿里云的HybridDB for MySQL(下文简称HDB):是同时支持海量数据在线事务(OLTP)和在线分析(OLAP)的HTAP关系型数据库。
- 架构发展为
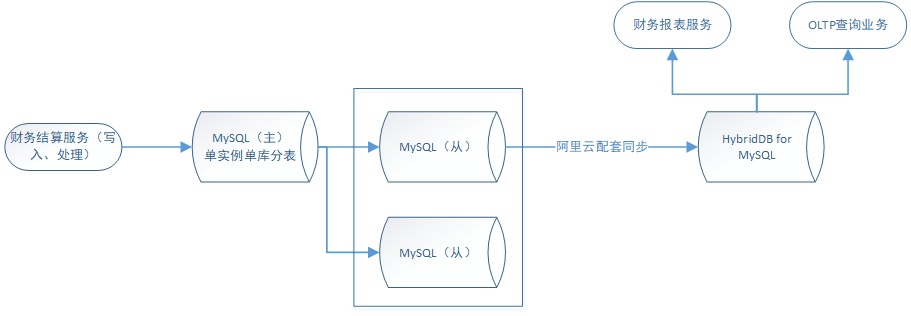
经过两个月的线上使用HDB,解决了很多现有的业务场景,同时也遇到了很多新的问题:
- HDB的同步压力过大,不是单独HDB配套单独的同步服务,用的阿里公用的同步服务,导致数据同步压力过大延迟过高
- HDB各种未知原因会漏同步SQL,寻求阿里解决都很积极但是最终无法定位到问题
- 二级分区键update会导致脏数据存在(阿里已经发补丁解决但是依旧有性能瓶颈)
总之由于HDB的闭源性,导致很多问题无法跟踪定位,只能依赖阿里响应,虽然阿里的响应非常迅速,但是确有很多不便,同时公司在考虑切换到腾讯云。基于以上种种原因,我们业务架构师建议我们尝试调研开源的分布式数据库项目TiDB。
测试对比(时间为19年5月)
报告探究目标
- 探测TiDB当前配置下的性能瓶颈
- 对比HDB、TiDB的OLTP、OLAP支持能力
- 初步探究TiDB的适用场景
服务器配置

通过阅读TiDB的开源文档。可以了解到,在TiDB架构中,TiDB和TiKV均会影响TiDB的OLAP性能。TiDB采用的是MPP模式的架构(虽然在MPP模式下做了些优化,不过依然属于MPP模式)
通过HDB计算资源的参数,可以了解到,HDB是MPP和DAG混合架构的方式实现的SQL计算。
这一环节的对比,可以预测到HDB对于复杂OLAP能力会略优于TiDB
分析
测试数据放在附件内,感兴趣的同学可以自行查看,这里直接提出基于测试数据的分析结论。
工具压测数据分析( TiDB自带工具场景压测 均为单表多线程的场景,分只读、只写、读写比等5种场景)
- 可以看到单表只读场景下,TiDB当前配置的负载能力29000 QPS,2000 TPS,为峰值性能。再增加线程并发QPS、TPS的提升并不大反而降低了整体响应时间。
- 在读写比的场景下,TIDB当前的峰值性能为2w3 QPS
、1300 tps - 写场景的压测情况,和DBA了解后较为单一,表结构较为简单,并发冲突不大,参考意义有限。
各种业务查询场景分析
- select one场景:
- HDB:由于一直是采用阿里推荐的全索引的方式建立的,未测试非索引条件。通过数据可以看到亿级的数据量对HDB的性能影响并不大。
- TiDB:测试了主键索引、非主键索引、非索引三种情况,在几个数据量级的情况下,有索引的查询条件对亿级的数据量也没有压力。但是对非索引条件从少数据量级的查询场景就能看到很大的的性能差距。
- select range场景:
- HDB:未测试非索引条件,可以看到我专门挑了相同条件不同响应数据量的范围查询来测,因为猜测HDB的查询其实响应能力很快的,但是他是一次性返回的,所以整个响应时间和数据量的大小有很大的关系
- TiDB:
- 在百万级别的数据场景下,即使是非索引列的条件响应时间也在秒级虽然和索引列差距巨大,但是也展示了TiDB分布式数据库的优势,同级别的数据MySQL下的非索引列查询时间达到了20秒。
- 可以看到同数据量的表,稍大数据量返回的场景,性能上比HDB要快了非常多,OLTP场景的查询性能上TiDB更为优秀。
- select limit场景
- HDB:对分页的支持非常不友好,即使数据量少,也会严重的影响HDB的响应时间,甚至不如原先的不带分页的SQL
- TiDB: TiDB对分页查询的支持非常快,带索引条件的查询,对于千万级数据表的响应时间依旧维持在毫秒级
- count 场景
- HDB:count的表现在hdb基本没有见到瓶颈,亿级的数据量也是毫秒级的响应时间
- TiDB:count的表现在TiDB和条件是否为索引列关系很大,同时表数量过大的情况下,全表的count也在千万级的数据量上性能有非常大的降低。
- TiDB order by场景
- 从上面数据可以看到对于order by条件的查询,对比同条件下不带orde by的查询有约8%左右的性能损失
- OLAP 场景
- 跑的是当前线上的月结SQL报表SQL,有一定的复杂度但是复杂度不算太高,没有嵌套子查询和join,可以看到这个场景下TiDB和HDB性能方面不相伯仲。
HDB对比TiDB总结
- HDB VS TiDB
- HDB底层为行列混合,count和sum等计算更为高效,亿级数据量也是毫秒级的响应时间,而TiDB行式存储对于过5000W级别的数据量开始出现明显的性能瓶颈。
- TiDB对于简单的OLTP查询(select one、select range、limit)支持能力更强,而HDB由于列式存储最终返回数据需要做一层数据聚合的动作,在OLTP的业务查询场景的表现下弱于TiDB
- MPP&DAG(HDB) vs MPP(TiDB)
- HDB采用的MPP&DAG的混合架构,在更加复杂的OLAP查询中,表现优于TiDB。不过TiDB也已经满足了80%的OLAP查询场景,同时提供了TiSpark组件针对剩下非常复杂的OLAP查询场景
测试结果TiDB适用场景
在线OLTP+少量的OLAP
TiDB分Region(区域)存储数据,连续的一个Key范围存储在一个Region内,Region又存储在节点上,又有组件保证每个节点上的区域数量差不多。该设计目的:
- 1.数据存储均匀、方便水平扩容,扩节点时有组件会自动调度节点过去
- 2.负载均衡,不至于像key hash那样,会有数据偏移
- 3.热点数据负载均衡,通过PD会自动调度分配热点Leader数量
TiDB避坑:
- 前期建表语句和索引的建立需要非常慎重,经过文档了解,TiDB的在线DDL语句是有两个个全局队列去处理的(AddIndex Job 队列、General 队列),Add index 会涉及搬运重组数据,大表的Add index操作非常的耗时。本地测试结果一亿数据的表add index 操作耗时十几分钟以上。虽然不会影响DML语句,但是如果有大量Add index要做的时候,比如发包前新增索引,会非常痛苦,而且如果线上出现慢SQL,也会非常危险临时加索引可能来不及。
- 少用order by提高查询效率;order by的查询,会改变TiDB Service的SelectResult,会将channel的方式改为slice,只有当order by前面的数据返回到了,才会往上返回。
- 不要应用在高冲突写的场景,TiDB为了提升并发能力采用的乐观锁的机制实现的事务,高冲突写会造成TiDB的压力,影响性能。
- 目前采用的方案是canal同步,TiDB的不支持单SQL内多DDL的情况,所以如果不可避免的DDL,请提前单条执行到TiDB上,为了避免同步任务中断,canal同步将不会开启DDL语句。
- where、order by、 group by、OLAP等的使用务必一定要建立索引,索引对TiDB的性能影响非常的大。
上线过程
初步测试结果中发现,HDB和TiDB都是满足我们业务需求的,但是鉴于公司计划在8月(19年)进行阿里云到腾讯云的迁移计划,所以HDB迁移到TiDB是势在必行的操作了。
我们在使用HDB的时候,为了降低使用风险,只利用HDB做了OLTP查询+OLAP业务,没有在上面操作insert、update,像把HDB作为MySQL只读查询库的方式在使用,即使HDB出现数据丢失,也不会影响我们的正常业务。
TiDB的使用同HDB一样,我们先打算先采用最保守的方式,把TiDB当MySQL的只读查询库来使用,尝试把TiDB跑到线上。
MySQL数据同步/迁移
- 同步方案:
- 在原来使用HDB的时候,考虑风险因素,为了保证线上稳定不受影响,我们只利用HDB做了OLTP查询+OLAP业务,没有在上面操作insert、update,保持着增量同步任务把HDB作为MySQL查询从库的方式来使用。并且阿里云有配套完整的数据迁移工具,直接界面化操作即可完成整个数据的全量同步+实时同步,接入业务的成本非常低。
- 这此切换TiDB,也打算使用同样的方式低风险的接入,将MySQL上的源数据同步到TiDB上以查询从库的方式先应用到业务。
- 问题: 但是由于TiDB并非阿里云这种商业支持的,数据同步需要自己想办法,在TiBD官网可以发现几种数据同步的方案,但是经过本人和DBA的测试,几个方案各有各的缺点,暂时没有办法支持我们这种全量+实时多表同步到单表的操作。
- 解决: 经过调研探索之后,最终的解决方案是自研一份基于数据的同步工具fmsdump,再加上开源项目otter实现MySQL-TiDB的全量同步+增量同步。otter的同步可以实现多表合并到同表并且自定义合并的规则,负载能力可以通过加机器进行扩容,加上可视化的界面操作,使用成本较低。
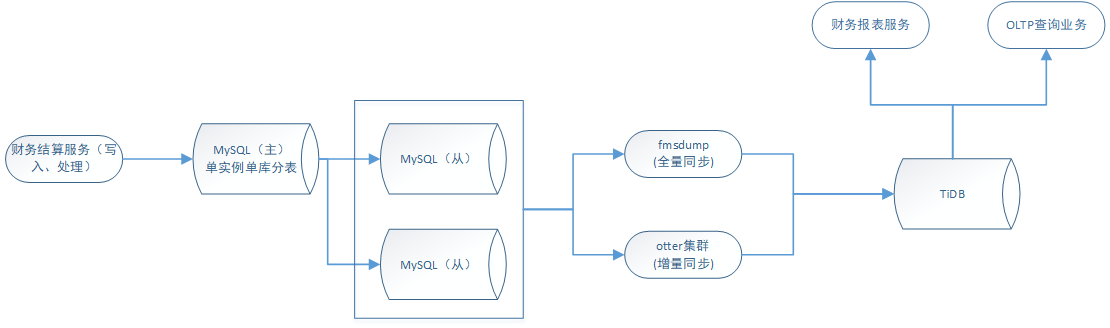
毕竟是通过数据写入的方式导入,没有把导入的并发线程调的很高,5个并发10个小时导入总量4亿的数据。上线接入的表,在两三天内接入完成。
上线结果
-
监控情况
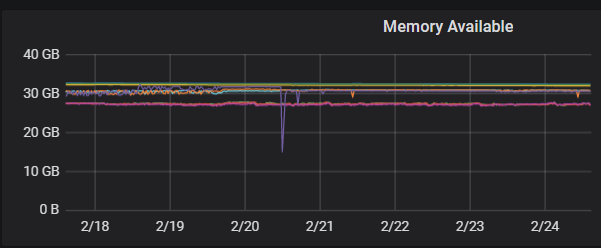
-
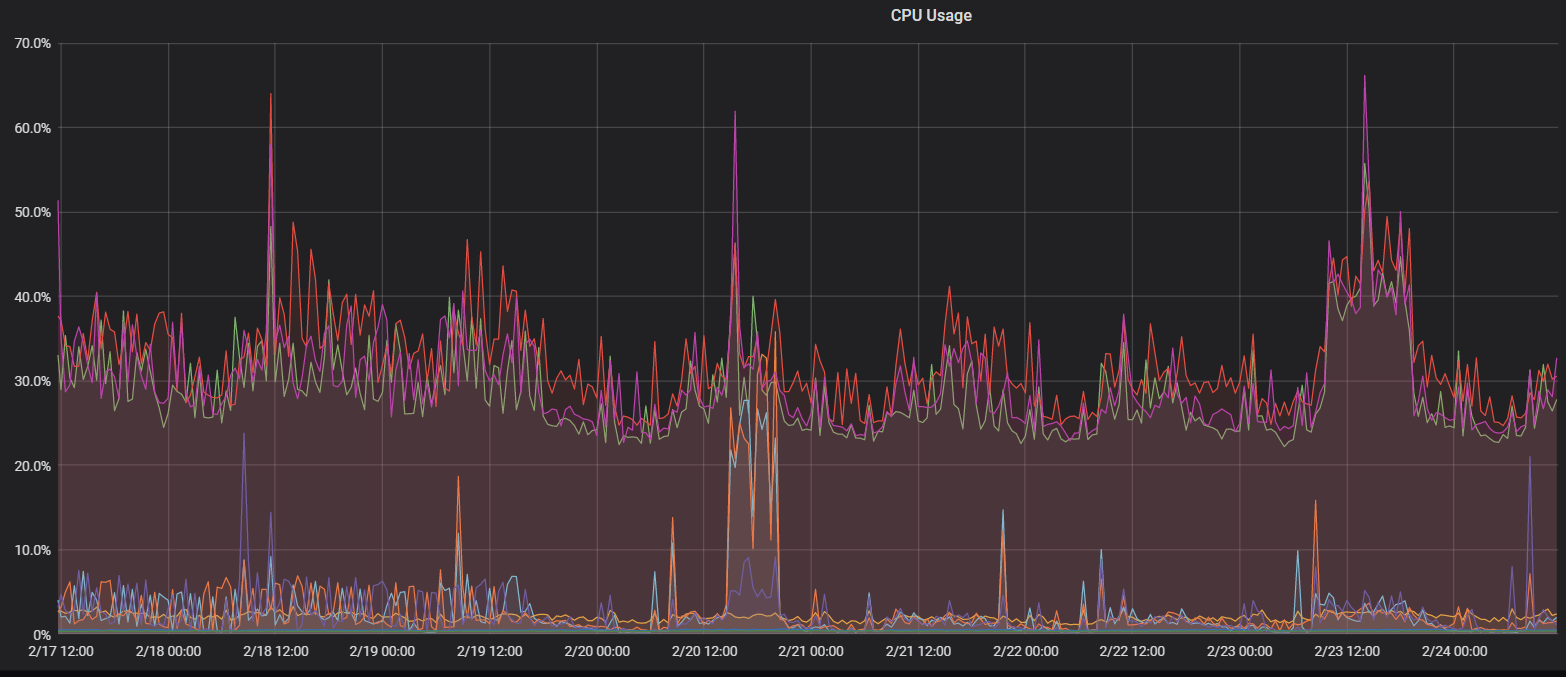
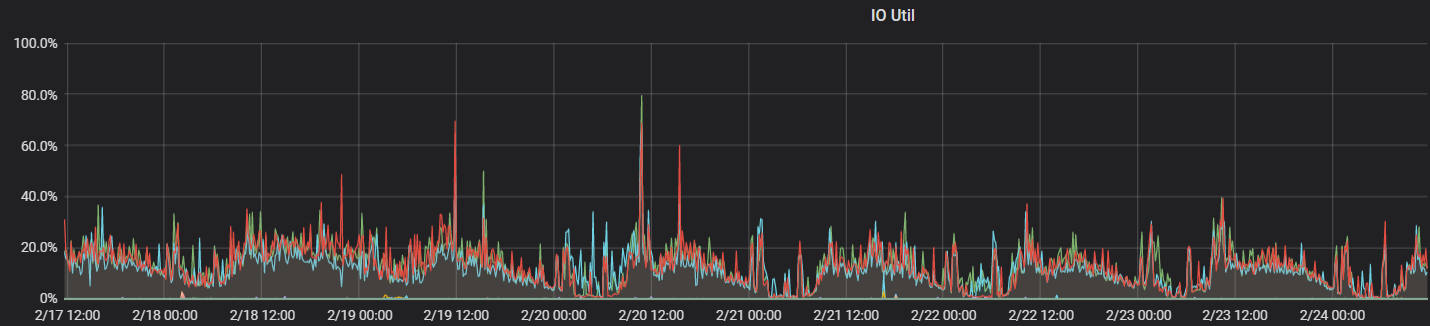
上线效果 由于我们应用在财务场景,没有太多的并发,主要观测日常业务和报表类SQL时系统的负载,发现除了在执行报表类SQL时会把系统负载打的比较高,日常指标还是比较稳定。解决了我们MySQL千万级单表查询瓶颈的问题,低成本的接入了更多的月报、年报等OLAP的业务。
-
数据规模 截止到文章撰写财务业务TiDB实例单表最大3.8亿数据、3台TiKV,单机数据量1.75T
-
业务情况
截止到文章撰写已接入的有:
- 只读的财务结算OLTP
- 只读财务库存OLTP
- 财务月报、年报OLAP
- 读写的新类型结算业务(单表5千万数据量,预期增长月均1000万)
- 对账平台(新的TiDB实例集群,和业务TiDB隔离的,专门承接公司所有业务的数据对账,数据量已远超过财务业务TiDB实例)
后续计划
- 目前痛点
- 由于MySQL和TiDB的DDL并不是完全兼容,TiDB没有办法像MySQL一样在一句SQL里进行多个字段的变更,所以导致otter的DDL同步会报错。我们尝试过用DM进行单表的同步,可以解决DDL的问题,但是在12月份爆发过一个由于DM同步表过多将TiDB连接池占满导致业务系统连接不上产生同步数据缺漏的问题。
- TiDB目前的版本非行列混合存储,虽然相较于MySQL上跑SQL性能提升巨大,和之前我们使用HDB相比,在OLAP方面还是有比较多的瓶颈。
- 我们的支付团队之前使用的是HDB事务版,现在由于切换到腾讯云也调研使用TiDB,但是在压测阶段一直压不到我们需求的并发性能
- 解决探索
- DDL的问题,由于我们TiDB作为主从使用主要是应用在AP场景,所以很多字段也不是全部都需要,我们目前放弃了DM同步,通过otter选择固定字段同步+跳过DDL同步,新增的字段暂时不接入了,在后期AP需求有需要的时候再将新字段维护进去。
- TiDB的AP场景,在测试环境搭建了TiSpark进行尝试,但是发现对我们的提升并不大,主要还是底层存储模式的限制,行式存储导致每次需要提取所有的数据,在网络传输数据量这部分占了整个SQL大部分的时间,即使用TiSpark也没有办法解决,目前在等待TiDB 3月中旬的GA版本上TiFlash列式存储,看会不会有比较大的提高。
- 请教了TiDB的相关同学,TiDB的同学积极的协助了我们排查,最终定位是存在的热点问题,但是尝试了TiDB同学提出的各种方法之后还是没有解决热点问题,支付的高并发场景一直压不上去,目前暂时还是用高配的MySQL分表+冷热分离来解决。
总结
经过长达一年的发展,从MySQL分表到HDB到TiDB,让我们对分布式数据库有了更深刻的认识。在不断深入使用的过程中,也从TiDB的设计思路得到很多启发。同时也遇到很多问题,期望TiDB团队能有更好的解决方案。
- DM同步工具:使用难度较高,DM同步规则不够灵活多表合并规则不够灵活,实时同步任务多的情况DM会占满TiDB连接池
- DDL语句:支持和MySQL一样的一个语句内多个变更。
- 慢SQL日志:需要DBA命令行去查询底层文件导出
- 表信息:没有表数据量大小的统计信息,只能查看TiKV磁盘大小观测总体数据量
TiDB活跃的社区、丰富的文档以及积极配合解决问题的TiDB同学,非常看好TiDB未来的趋势。同时根据我们自身的规划,2020年部门将会有两个个重点项目也会启用TiDB做为底层的存储,深化更多的使用场景。