Whm412
2020 年6 月 11 日 03:03
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:TiDB 4.0 TiUP部署
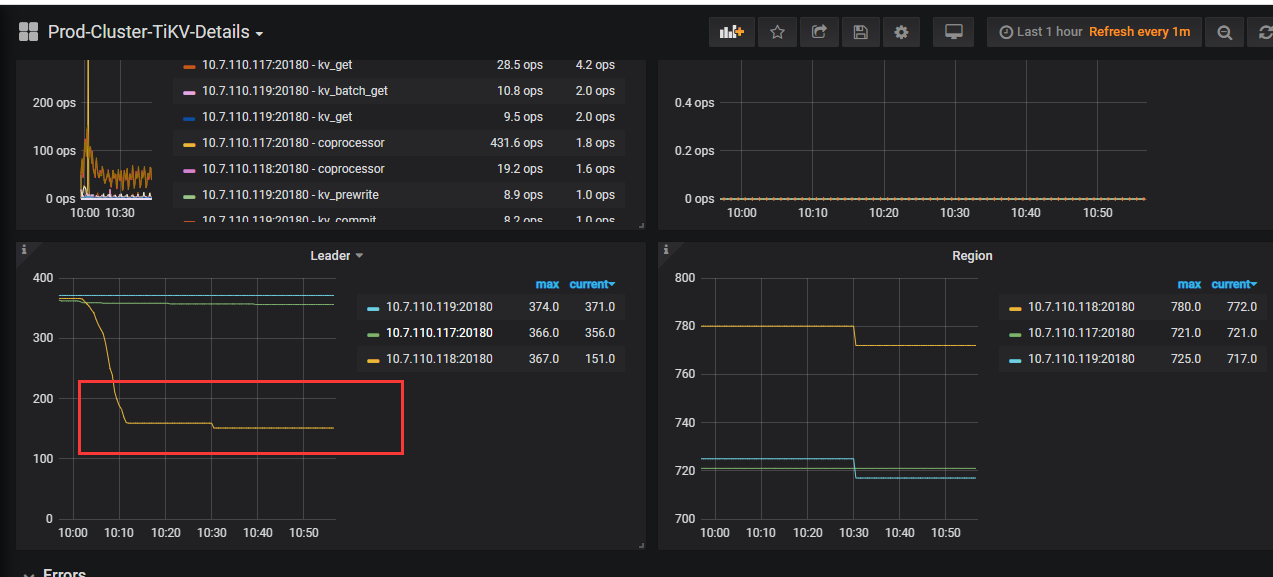
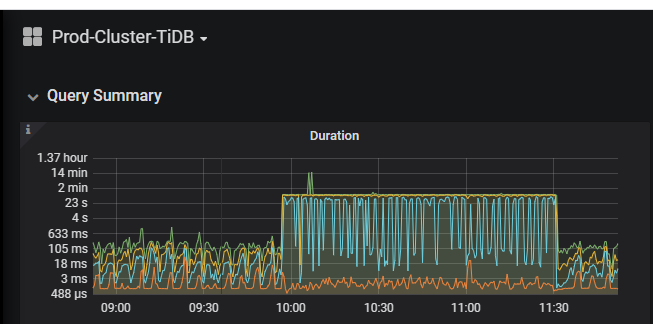
【问题描述】:今天9:56突然间,响应时间就变慢了。通过下面两个截图可以看出tikv中118机器有问题。找到了相应的日志。tidb.log (4.0 MB)tikv.log2020-06-11-10_14_00.204392970 (4.8 MB)
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
来了老弟
2020 年6 月 11 日 03:38
2
你好,
当前集群是否恢复正常,此问题是周期性的还是第一次出现。
tikv 日志中出现 [2020/06/11 10:10:10.868 +08:00] [WARN] [endpoint.rs:536] [error-response] [err="Region error (will back off and retry) message: \"peer is not leader for region 3486005, leader may None\" not_leader { region_id: 3486005 }"] 并且监控图中 leader 数量也掉了许多。
需要反馈下信息,便于排查:
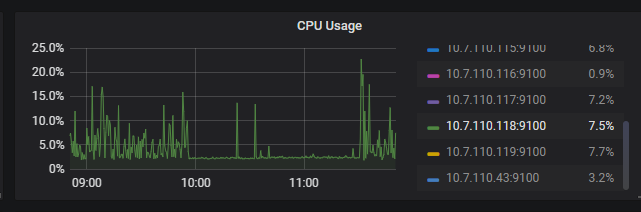
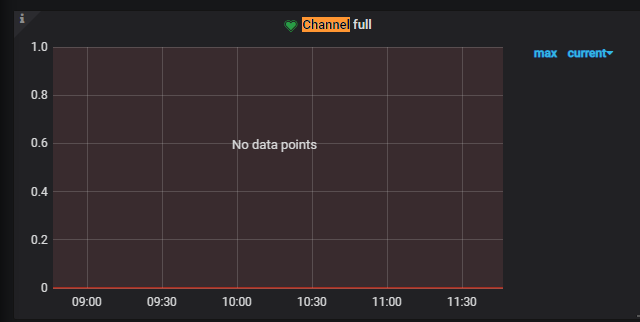
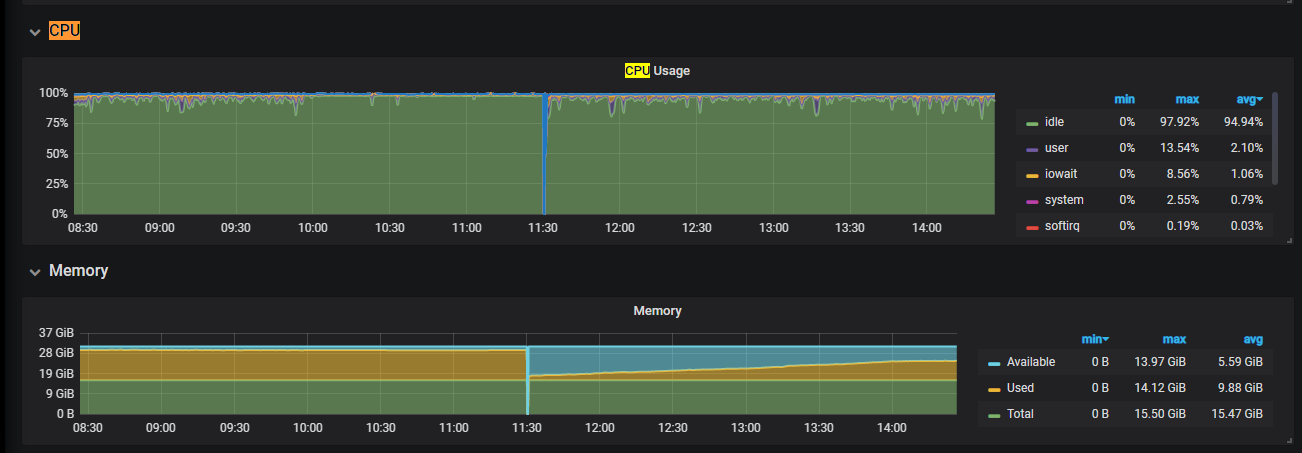
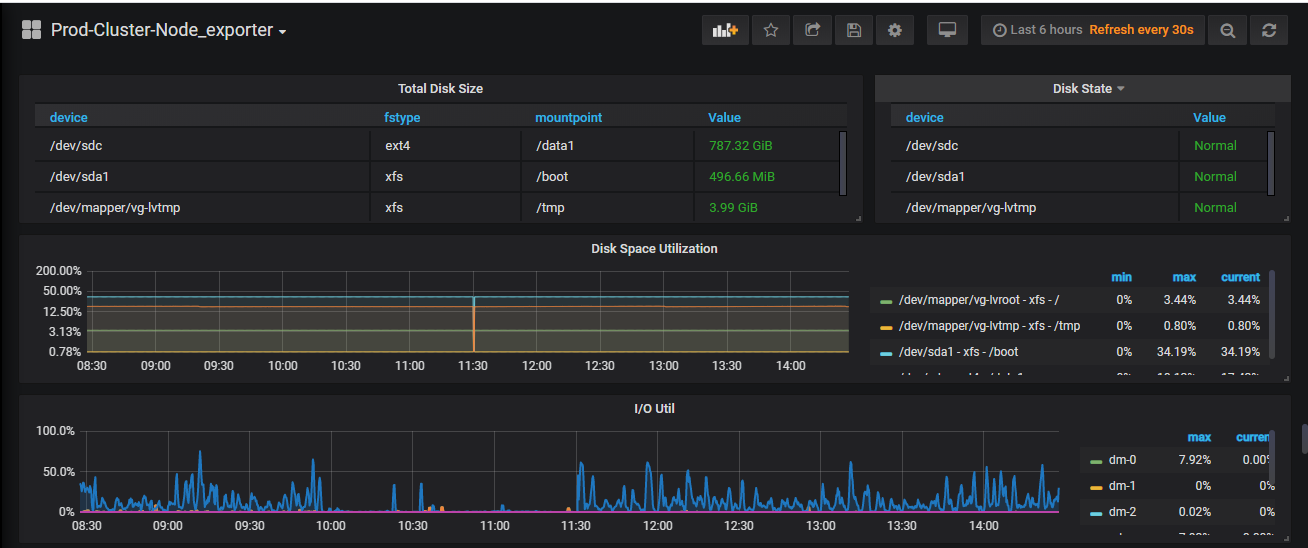
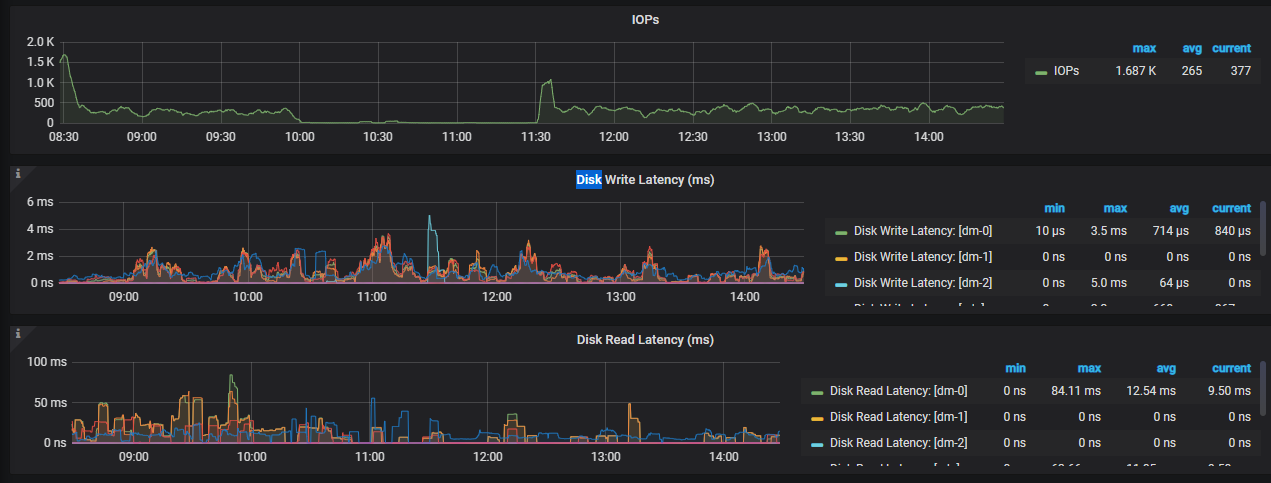
反馈下 tikv-details - Server - channel full 和 node_exporter - CPU 和 Disk 信息
Whm412
2020 年6 月 11 日 03:52
3
来了老弟
2020 年6 月 11 日 06:21
4
你好,故障时间点 node_exporter - CPU 和 Disk 信息,麻烦反馈下,确认下是否由于磁盘 io 较高导致的。
来了老弟
2020 年6 月 11 日 10:11
6
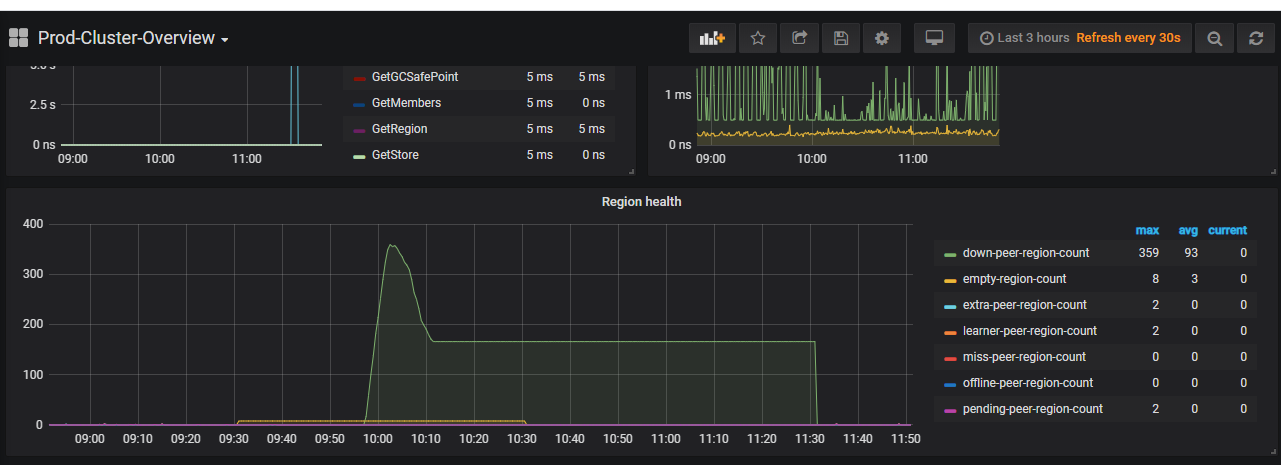
辛苦上传下 tikv detail 和 tidb 面板,这边看磁盘 io没有问题,并且在 duration 高时间点,没有上涨,可能是,还需要排查一下
Whm412
2020 年6 月 12 日 01:57
7
这个问题暂时先不排查了,可能是偶然现象,也可能和这边的虚拟机部署有关,后期再观察一下,如果有类似现象,再仔细排查一下。
小王同学
2020 年6 月 12 日 02:14
8
Whm412
2020 年6 月 12 日 02:24
9
典型case案例,看着是那么回事,但由于没发生在自已负责的项目当中,所以不会有那么深刻的体会,只是看过了,但离真正用还有一段距离。也是一个方向,会去看的。