Santer
2020 年6 月 8 日 09:41
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:5.7.25-TiDB-v4.0.0
【问题描述】:
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出打印结果,请务必全选 并复制粘贴上传。
Santer
2020 年6 月 8 日 10:48
3
SELECT count(0) FROM A a WHERE a.ISDELETE = 0 AND a.cid IN (‘11111’,‘22222’,‘33333’,‘44444’,‘55555’,);ana.xlsx (15.2 KB)
yilong
2020 年6 月 8 日 12:45
4
麻烦发送下问题发生时的 over-view,tidb,detail-tikv 日志,可以使用如下方法,采取长图
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
麻烦您再发送一个执行时间快时的 执行计划,多谢。
请问这个索引 table:a, index:INDEX_DESIGNMATERIAL_CID(categoryid) 具体是哪些列组成的?
Santer
2020 年6 月 10 日 03:00
5
【TiDB 版本】3.0.6
/
2、执行快的执行计划:
3、执行慢的执行计划:
/
4、慢查询结果:查询越查越慢,单独查询只需要一百毫秒左右
5、走的索引是:idx_designmaterial_organid_cid
Santer
2020 年6 月 10 日 06:07
7
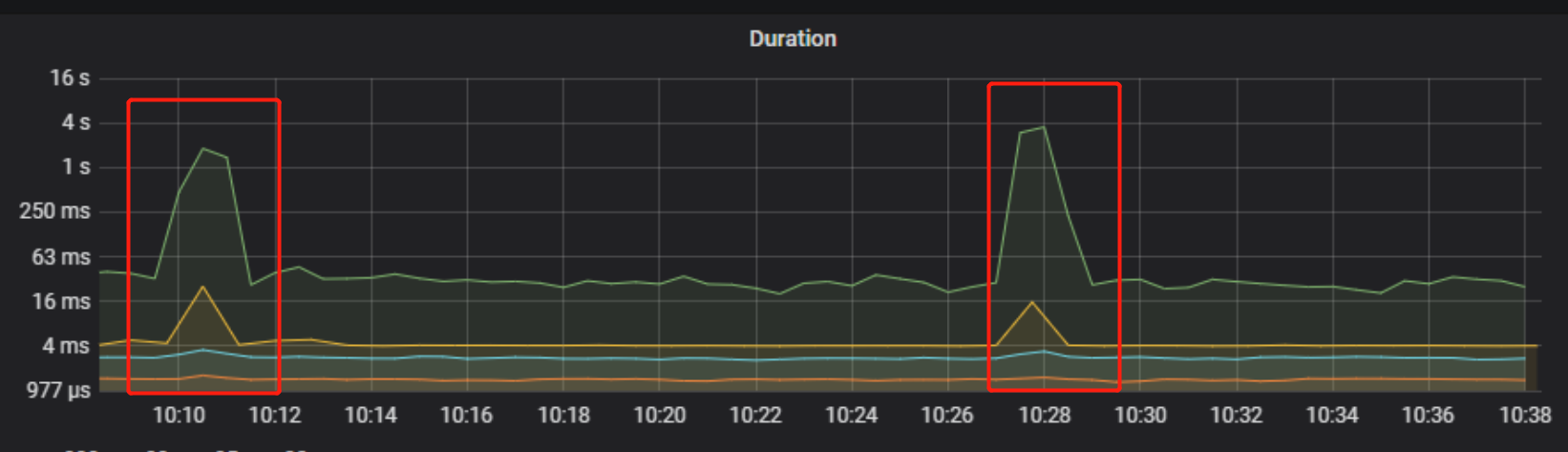
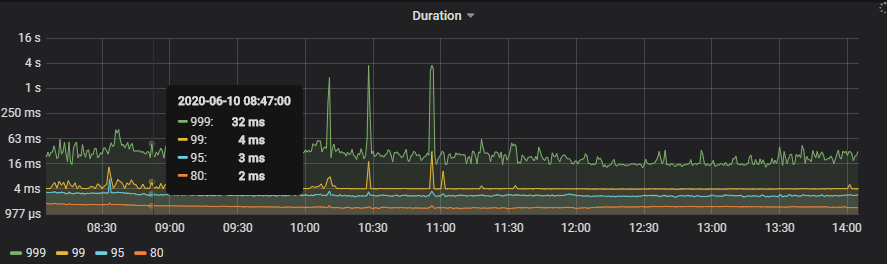
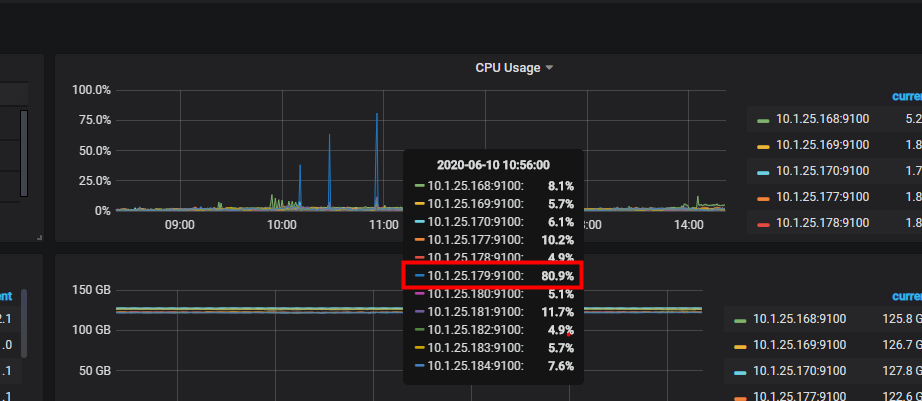
今天一共压测了3次,每次duration都会上升,其中一个是我每秒并发10个用户持续30秒造成,一个是我每秒并发20持续30秒造成
Santer
2020 年6 月 10 日 06:26
8
后面换过环境的tidb的版本是3.0.6。