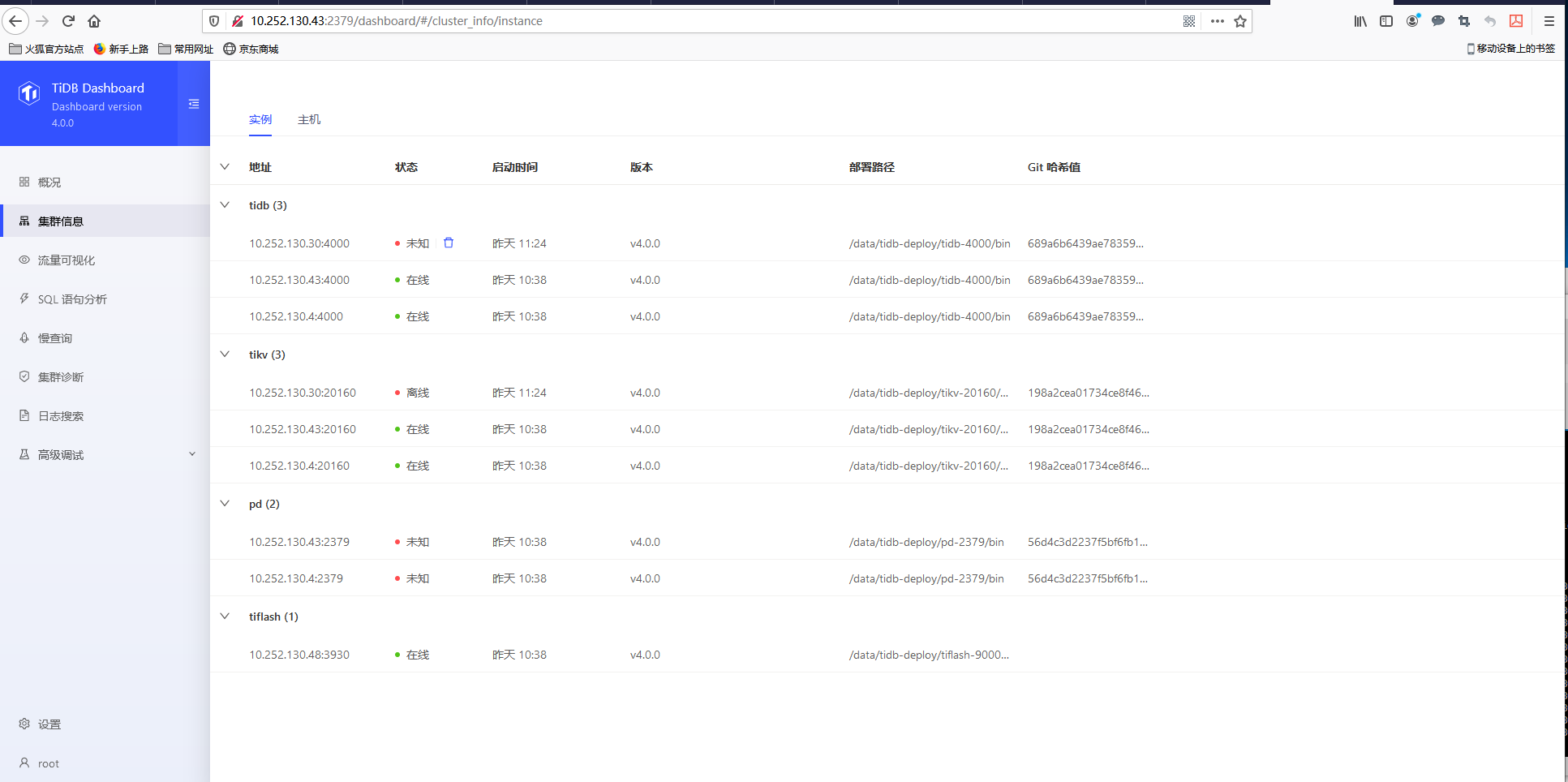
部署完毕后的集群状态

关闭其中一台pd机器10.252.130.30
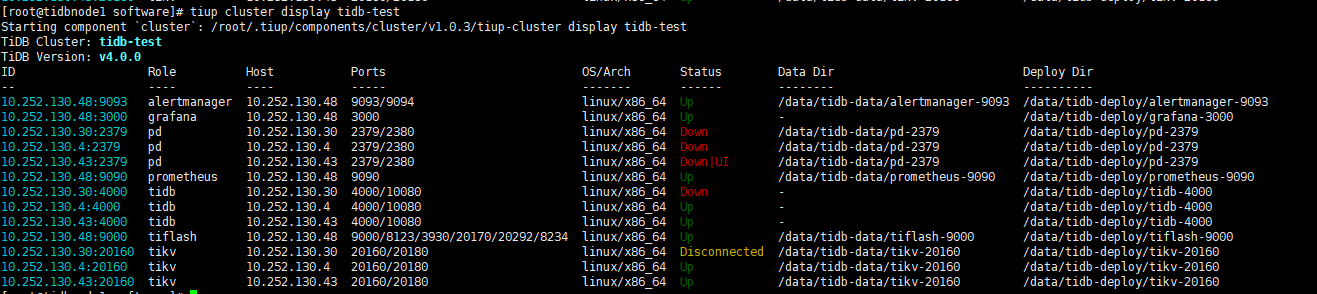
pd报错日志如下
pd.log (256.1 KB)
请问关闭 10.252.130.30 机器是直接关闭了服务器吗?
故障是在模拟服务器down机的情况下产生 直接把10.252.130.30这台服务器关闭了
10.252.130.30日志如下
10.252.130.30pd.zip (2.6 MB)
tidbdashbord显示 pd节点情况为未知
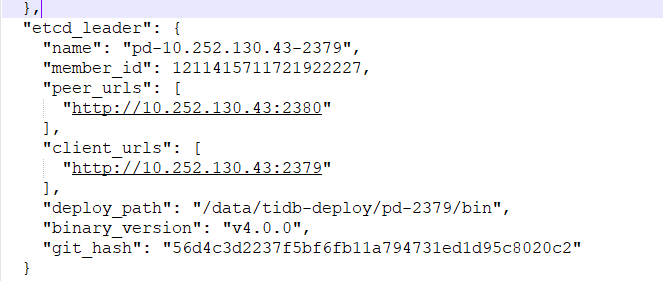
查看pd信息,看到member状态已经切换了leader, etcd 的leader是 pd-10.252.130.43-2379
能否尝试用命令行访问数据,是否正常,能否insert数据,判断下是tiup显示不正常,还是集群确实都不可用
请上传 pd 和 tikv 10.143 的 一部分日志,多谢。
可以正常插入数据,看上去是tiup显示不正常。13043pd.zip (4.1 MB)
之前的leader节点是10.252.130.43并未发生变化。我这里模拟下关闭leader节点时的情况。
又测试了几次发现,tiup显示不正常,但是pd工作应该是不受影响的,只是如果挂掉的节点正好是
带有UI的这个节点那么 tidb 的dashboard也将无法访问。似乎通过其他pd节点访问tidbdashboard也会跳转到tag为ui的那个pd节点。查看 pd 日志有报错 dropped internal Raft message since sending buffer is full (overloaded network) ,我们先查下,多谢。
dropped internal Raft message since sending buffer is full
这个错误一般是网络问题导致消息无法发出去而造成的堆积,可以检查一下 PD 之间的网络环境。 日志中这个消息都是发往 [remote-peer-id=2056ebc4dd0beae0] 的,如果这个是 down 掉的 PD 那这个日志就是符合预期的。
你好,麻烦在中控机(tiup 所在机器) 执行以下命令:
time curl 10.252.130.30:2379/pd/health
time curl 10.252.130.4:2379/pd/health
time curl 10.252.130.43:2379/pd/health
你好,PD那台设备是模拟关机。只是目前在其中一个pd down掉的情况下 tiup显示看上去不准确。
麻烦反馈下这些信息,多谢
curl 10.252.130.30:2379/pd/health
curl 10.252.130.4:2379/pd/health
curl 10.252.130.43:2379/pd/health