为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.13
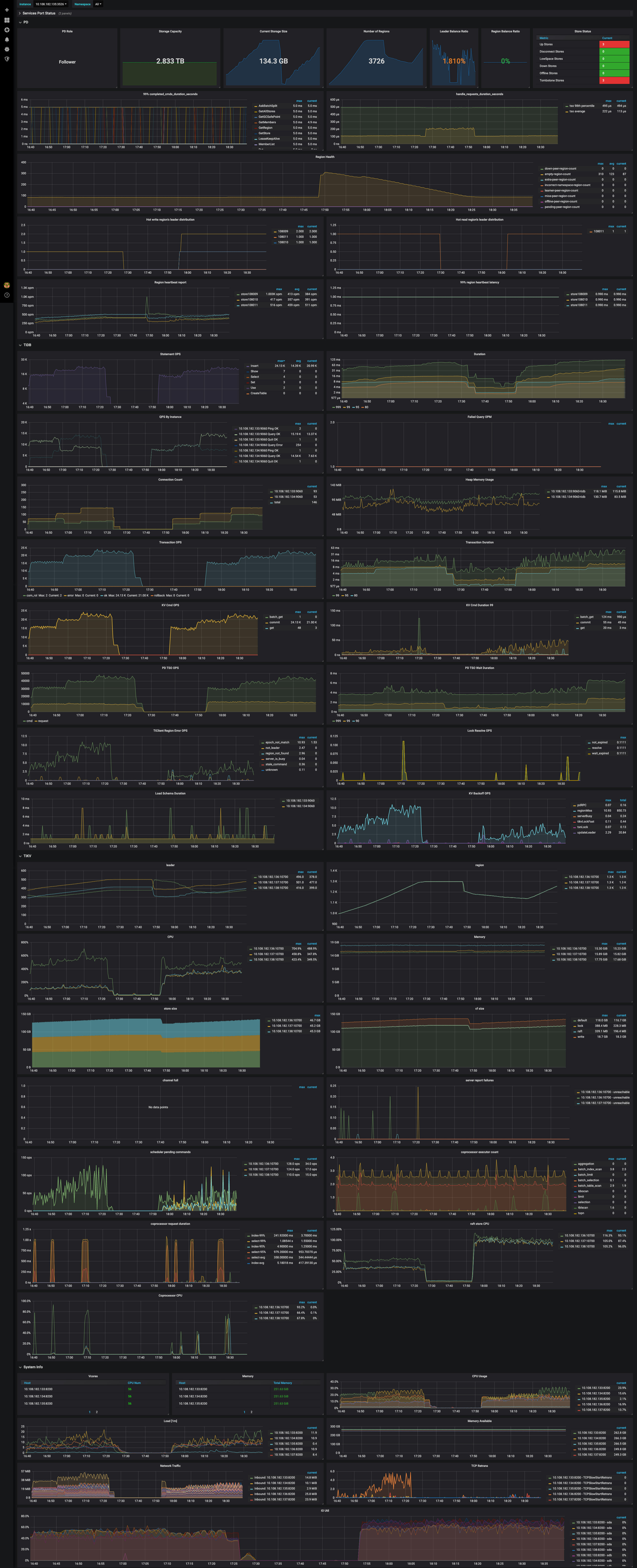
- 【问题描述】:使用自带row_id压测插入性能时,建表时使用shard_row_id_bits=2的插入性能要比不使用的差不少,表现为QPS降低,响应升高,并且shard后的raft store cpu和 Async apply cpu使用率都变得很高了。预期应该是,shard后的表的插入性能应该比未shard要好一些。
看了下Tikv-detail里的grpc,shard后的message batch size减小很多,会不会是不是这个原因导致了系统的吞吐量降低。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
表结构如下,只是多线程循环insert。监控里前的数据前半段未shard,后半段是shard_row_id_bits = 2。
建表语句如下
create.sql (455 字节)
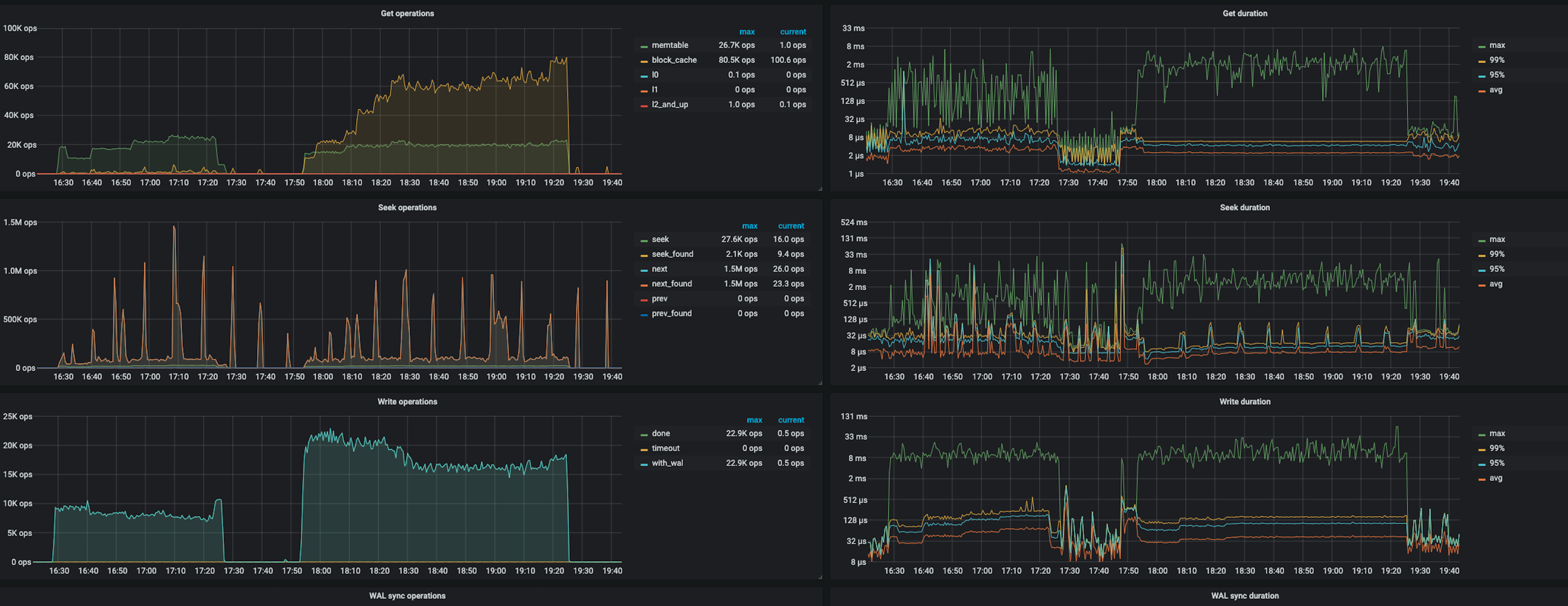
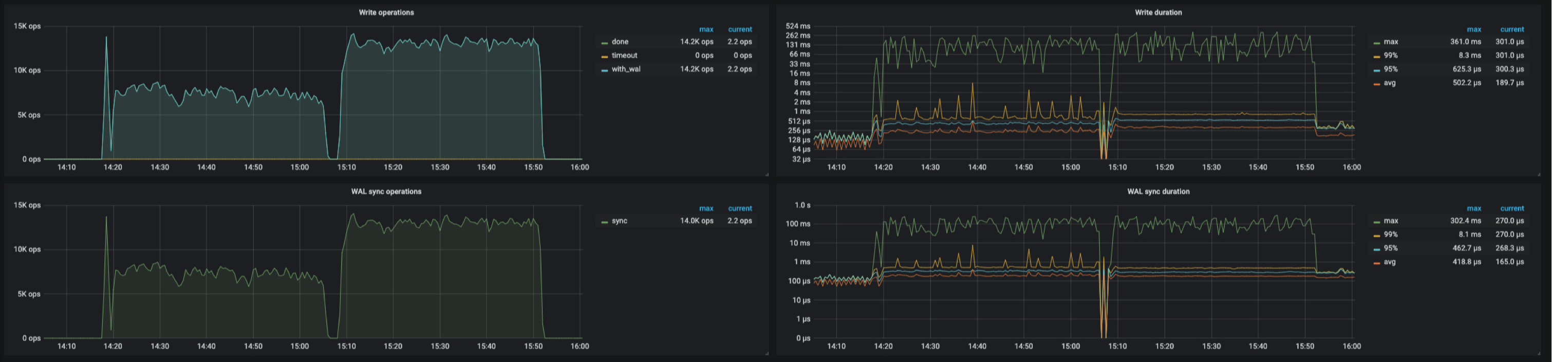
RocksDB-kv 面板里,使用shard以后有大量的get operation 来自 block-cache
从监控上看到,设置 shard_row_id_bits 之后,热点问题有一定的缓解
方便提供一下压测的表结构,以及 insert 语句吗?压测的模型是简单的 单条 inser 语句,还是一个事务中包含多条语句的压测方式?
表结构:create.sql (455 字节)
压测模型:一个事务只有一条插入语句。
insert into ${table} (v1, v2, v3, v4, v5, title, content, userId) values (#{testEntity.v1}, #{testEntity.v2}, {testEntity.v3}, #{testEntity.v4}, #{testEntity.v5}, #{testEntity.title}, #{testEntity.content}, #{testEntity.userId})
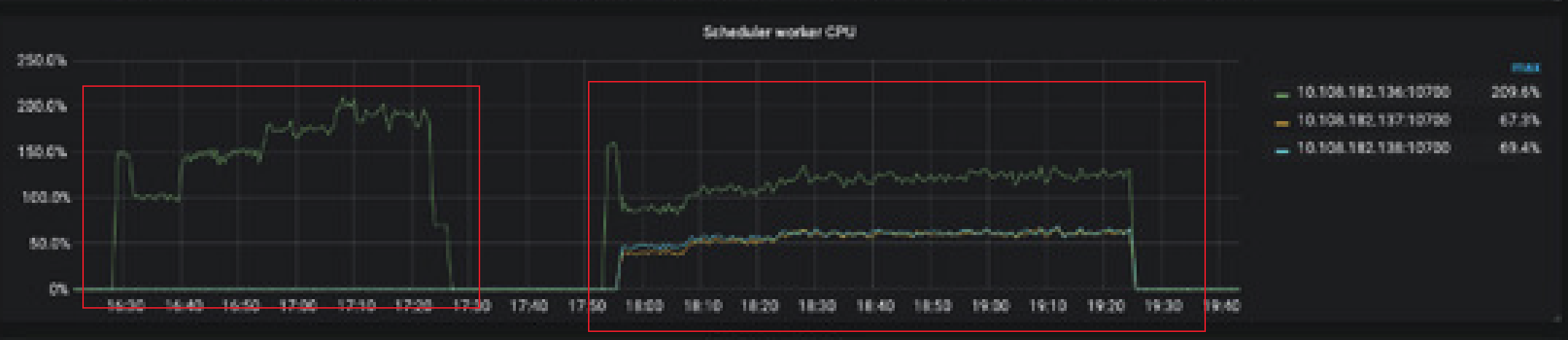
我关注的问题:从监控上,是可以看到热点被分布到不同的机器上,例如你给出的scheduler worker cpu或者是overview pd面板的数据,都可以看出来。
虽然热点分布到不同的机器上了,但是QPS没有上去、延迟也增加了,监控上的raft store cpu和 Async apply cpu都比未shard要高呢。
然后RocksDB-kv的监控数据似乎也表明,shard后的operation数增加很多。
看起来shard后,请求数被放大了,造成集群负载更高了。
对此,我的理解是:如果没有shard,所有请求都打到一个节点上,这时这个节点能够更好的batch处理请求,所以吞吐量会更高一些,依据是grpc msg batch size和raft msg batch size,未shard的情况下要远大于shard。
你截的图片似乎很模糊,不知道是不是我给的监控图片不对,如需重新上传,还请告知。
TiKV-Detail 的相关监控上传的图片比较模糊,可以的话麻烦重新上传一下,并且最好能展开所有的监控项导出
另外可以上传一下 TiDB/PD/touble-shooting 的监控,再看下
监控为 pdf 的方式:
1)使用 chrome 浏览器,安装“Full Page Screen Capture”插件:
https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
2)展开grafana 监控的 “cluster-name-overview” 的所有 dashboard (先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
3)使用插件导出 pdf
链接: https://pan.baidu.com/s/1pvbZihk9po6aydGbP4upCA 提取码: 9qkq
相关PDF大小超过限制,已经放入网盘,还麻烦查收一下。
目前问题:shard后的插入查询,延迟更高了,QPS也没有太大提升,想了解一下是什么导致的
我的观察到以下几个现象:
1、TIKV面板的Rocks-kv的get operation以及 write operation,shard比未shard明显要多出很多。其中get operation多了许多block-cache操作。
2、TIKV面板的Thread cpu显示,Raft store cpu和 Async apply cpu的负载,shard比未shard明显要高很多。
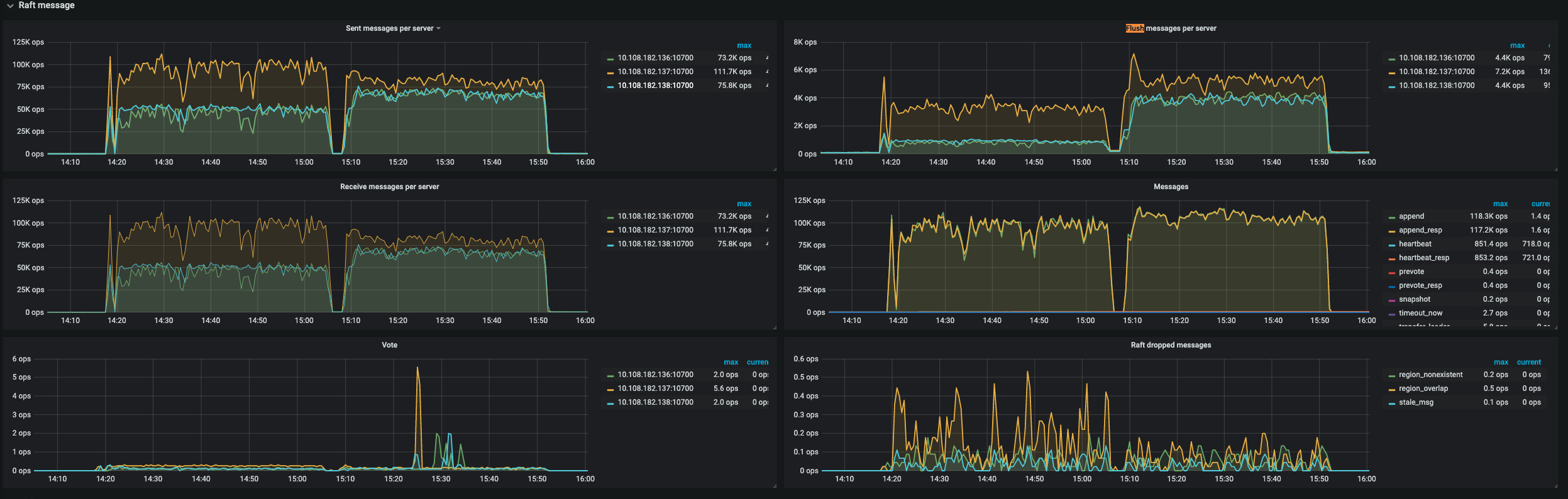
3、TIKV面板的Raft message显示,Flush message的数量,shard比未shard明显要大很多。
除此之外,我观察到TIKV面板的grpc里,grpc batch size和raft batch size,shard比未shard的明显要小。所以我在想是不是因为没有shard,所有请求都打到一个节点上,这时这个节点能够更好以batch的方式处理请求,所以吞吐量会更高一些。
谢谢 辛苦
-
gRPC batch size 和 raft message batch size 下降了,这个可以像你这样理解,所有请求都打到一个节点上,这时这个节点能够更好以batch的方式处理请求,当使用了 shard 之后,请求被分散到各个节点上,batch size 会减小
-
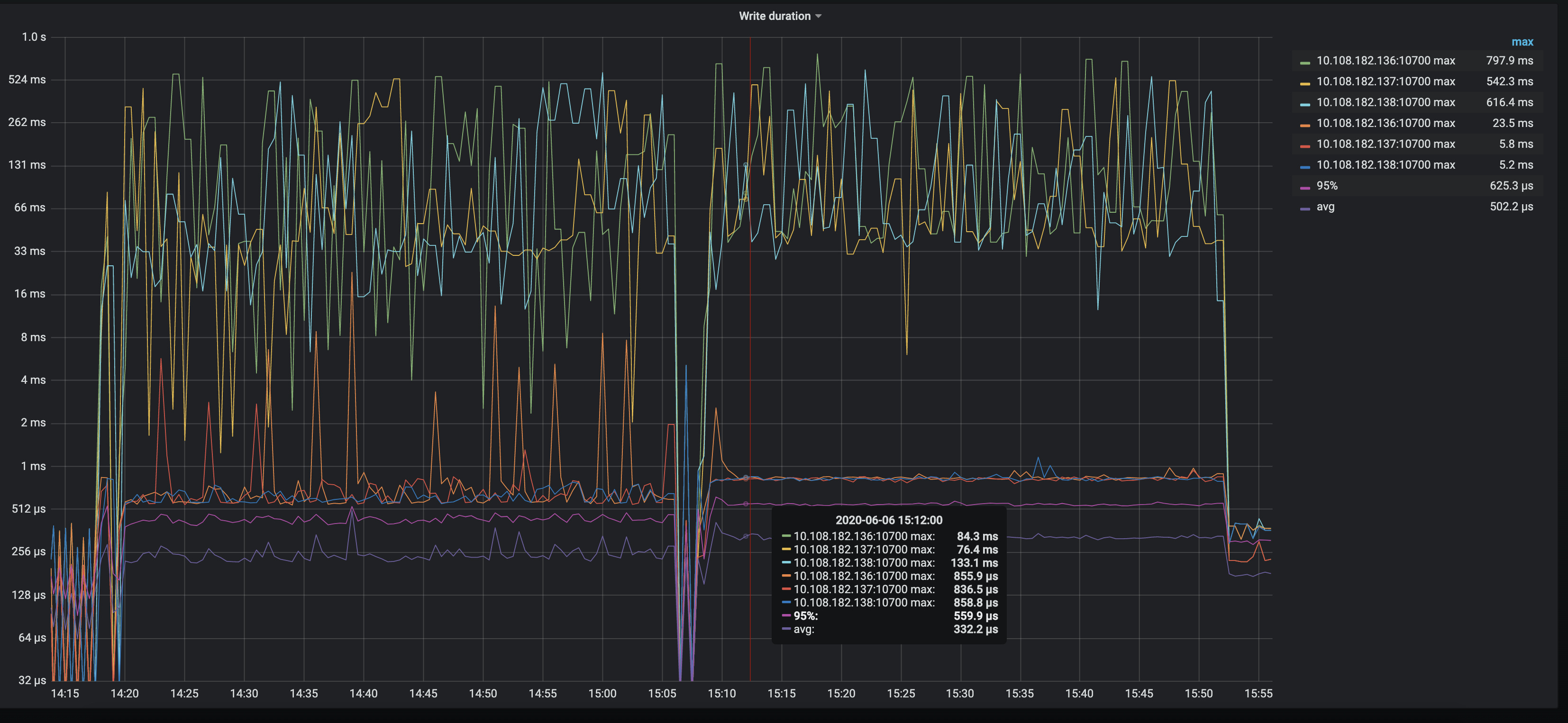
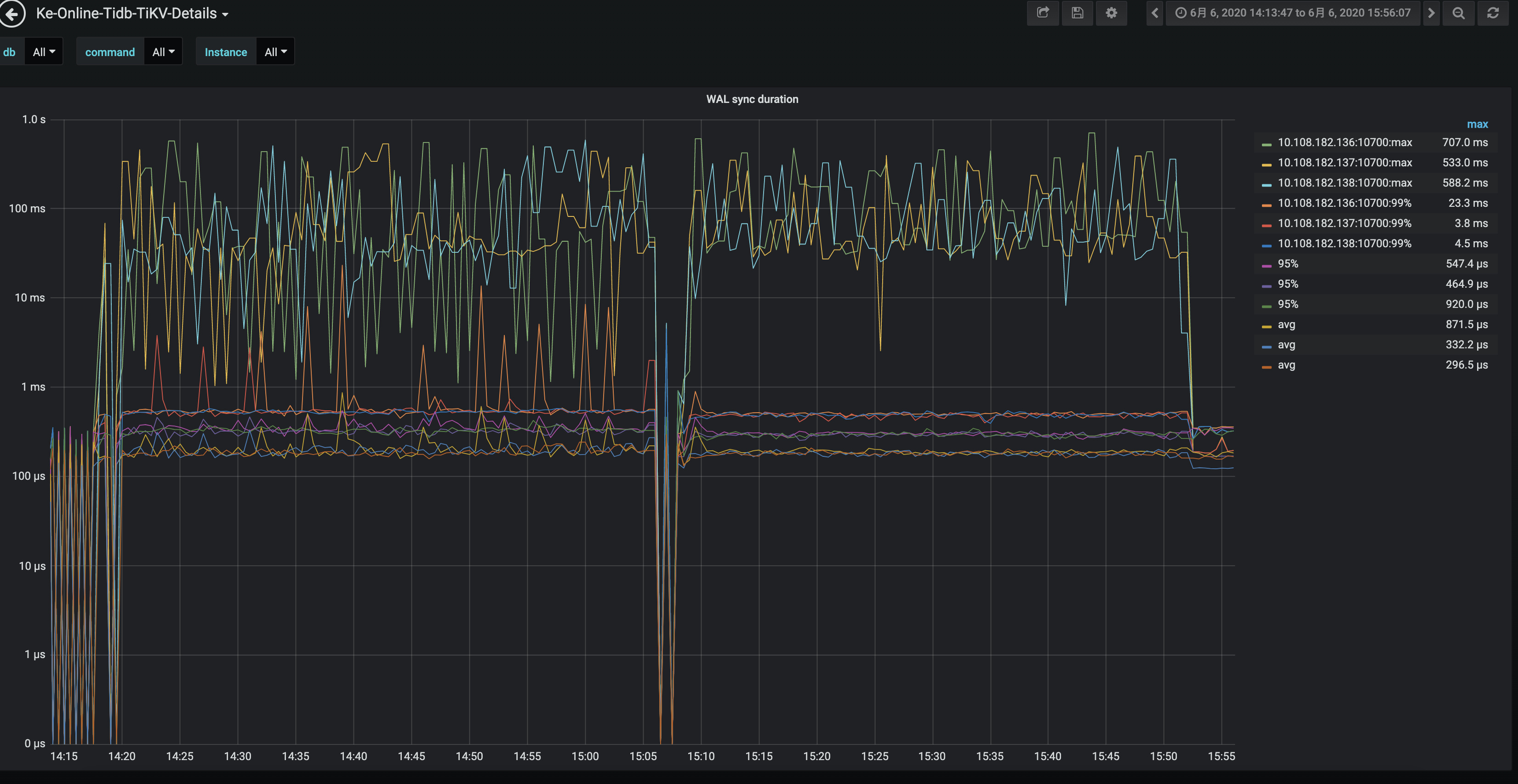
关于 使用 shard 之后写入性能还是没有提升的问题,判断可能是达到了 WAL 瓶颈的原因,WAL 是 RocksDB 的写日志操作
从 TiKV-Detail → RocksDB kv 和 RocksDB raft 的监控中看到,使用 shard 之后 Write operation 以及 WAL sync operation 都是上升了的,但是 WAL sync duration 比较高,达到了几十毫秒
可以默认为目前的 tikv 最佳适配 CPU 为 16c ~ 24c。只要 CPU 大小超过这个数量就需要增加 tikv 的实例以提高写吞吐,这是由于 tikv 负责同步与复制的 raftstore 线程池共用一个 rocksdb 实例,在底层只允许一个线程进行写 WAL 操作,因此会受制于单线程 IO 模型而成为瓶颈
从操作系统资源看,CPU/IO 还有一定的性能剩余,请问你们的 TiKV 是单机单实例部署的吗?从监控看你们的机器配置应该是 56C 256G 内存的配置,如果是单机单实例方式部署 TiKV 的,可以考虑将扩容称为单机双实例部署方式,在 3 台机器上部署 6 个 tikv 实例,性能上应该还会有一定的提升。
嗯嗯 十分感谢你的回复 目前是单机单实例部署的,这边之后会看下单机多实例的部署方式
不好意思,还有一个问题需要请教一下。
我看了下v3.0文档里的单机多实例部署方式,上面说到 :
默认情况下,建议在每个 TiKV 节点上仅部署一个 TiKV 实例,以提高性能。但是,如果你的 TiKV 部署机器的 CPU 和内存配置是部署建议的两倍或以上,并且一个节点拥有两块 SSD 硬盘或者单块 SSD 硬盘的容量大于 2 TB,则可以考虑部署两实例,但不建议部署两个以上实例。
目前生产集群一个节点只有一块900GB的SSD,这种情况下单机双实例是否可行呢。从压测的监控图来看,SSD盘的IO Util约50%到60%这样,感觉硬盘的IO并不是瓶颈。但是由于SSD容量较小,需考虑空间效率的问题,不知道部署多个TIKV实例,会造成空间上的浪费吗?我的理解是如果部署时,只维护3个副本,然后指定label(副本会根据label分配到三个不同的节点),单实例和双实例占用的空间应该没有太大区别。 但是不清楚,为什么提议上会要求单块SSD容量大于2TB。
yilong
(yi888long)
16
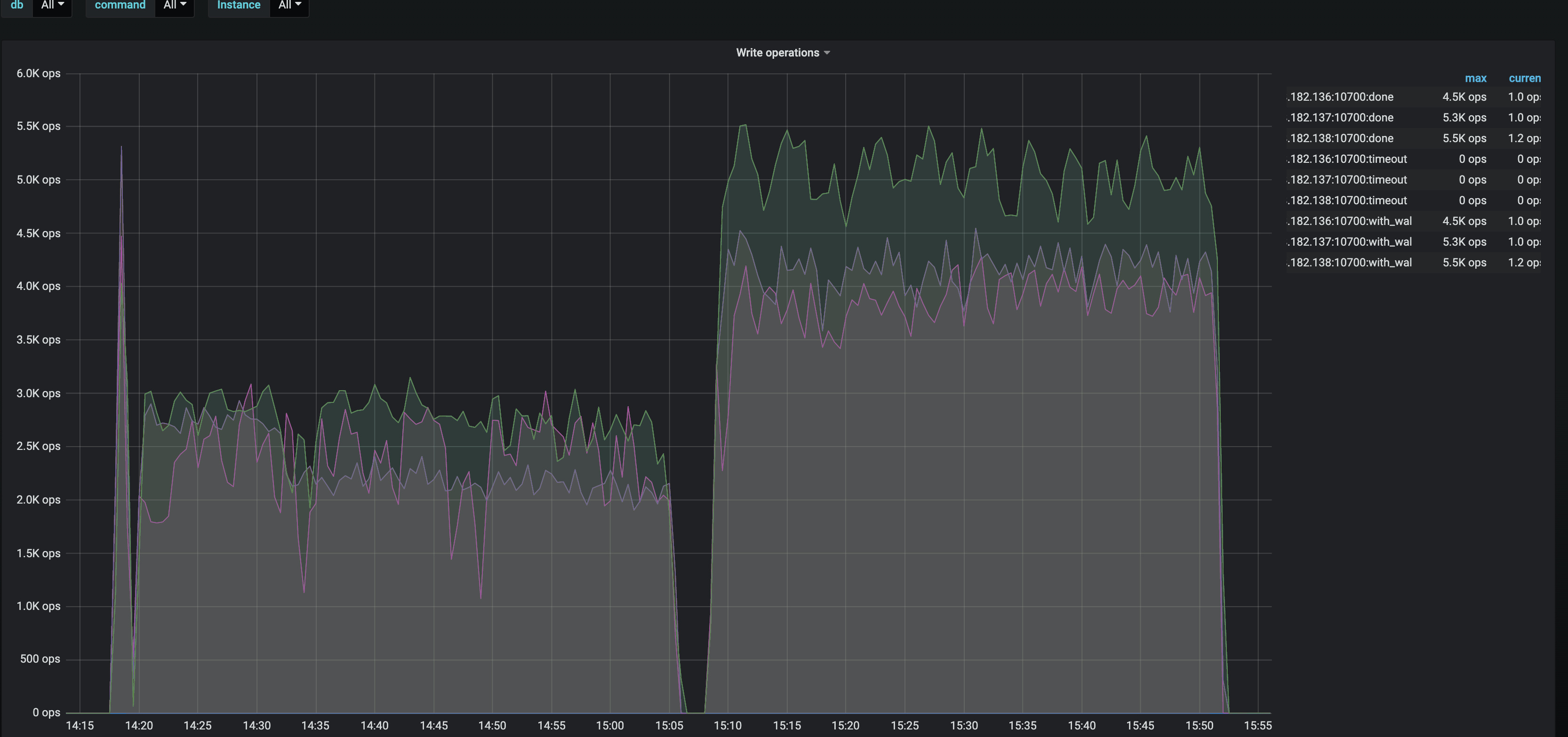
您好,这个问题可以继续帮忙反馈下信息吗? detail-tikv---->rocksdb-raft 找到以下参数---->edit编辑—>修改为 by instance,查看下每个实例的信息
举例:
sum(rate(tikv_engine_write_served{instance=~“$instance”, db=“$db”, type=~“write_done_by_self|write_done_by_other”}[1m]))
修改为
sum(rate(tikv_engine_write_served{instance=~“$instance”, db=“$db”, type=~“write_done_by_self|write_done_by_other”}[1m])) by (instance)