
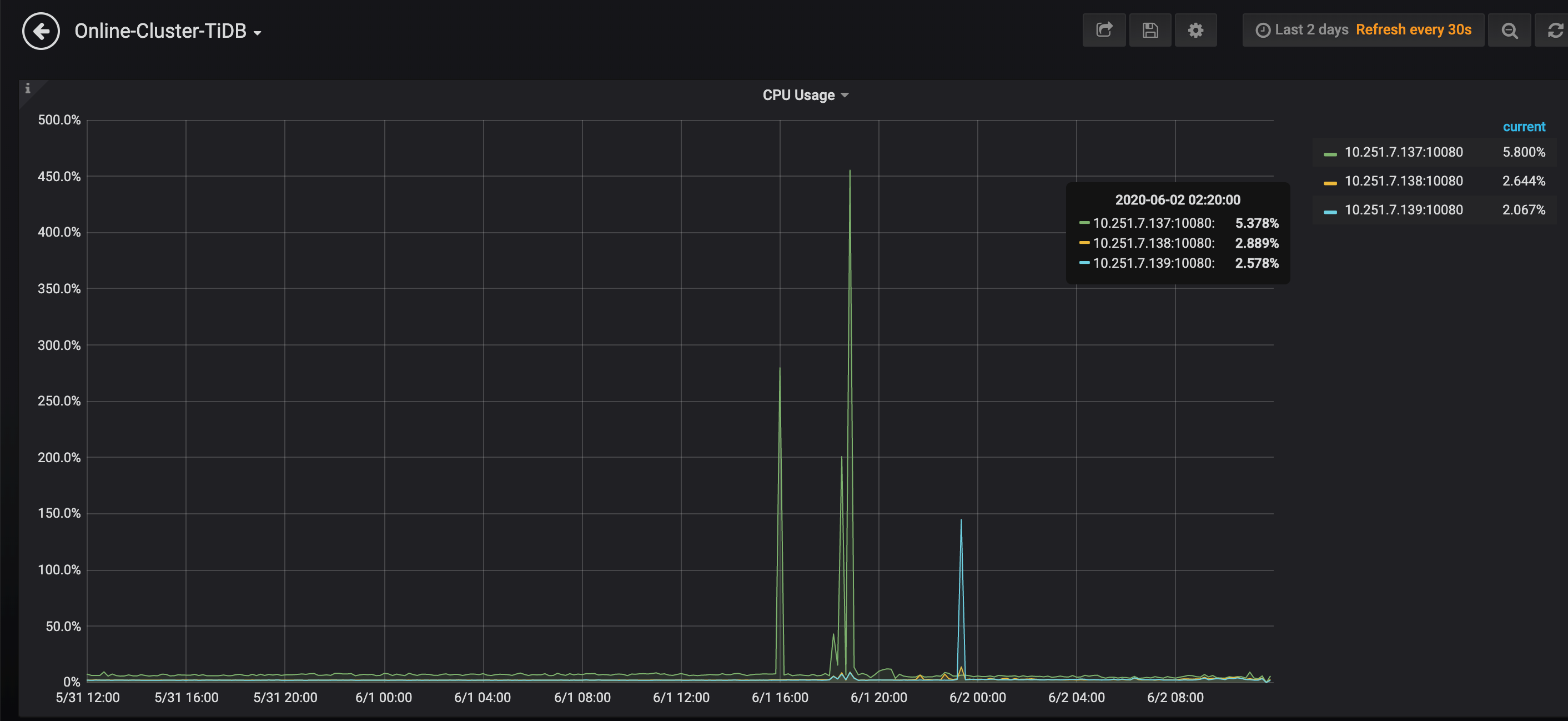

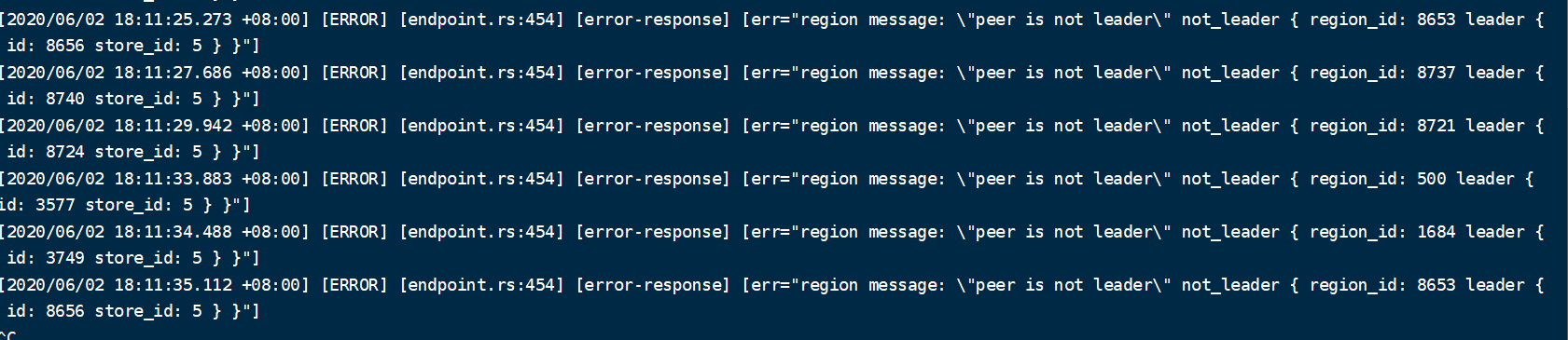
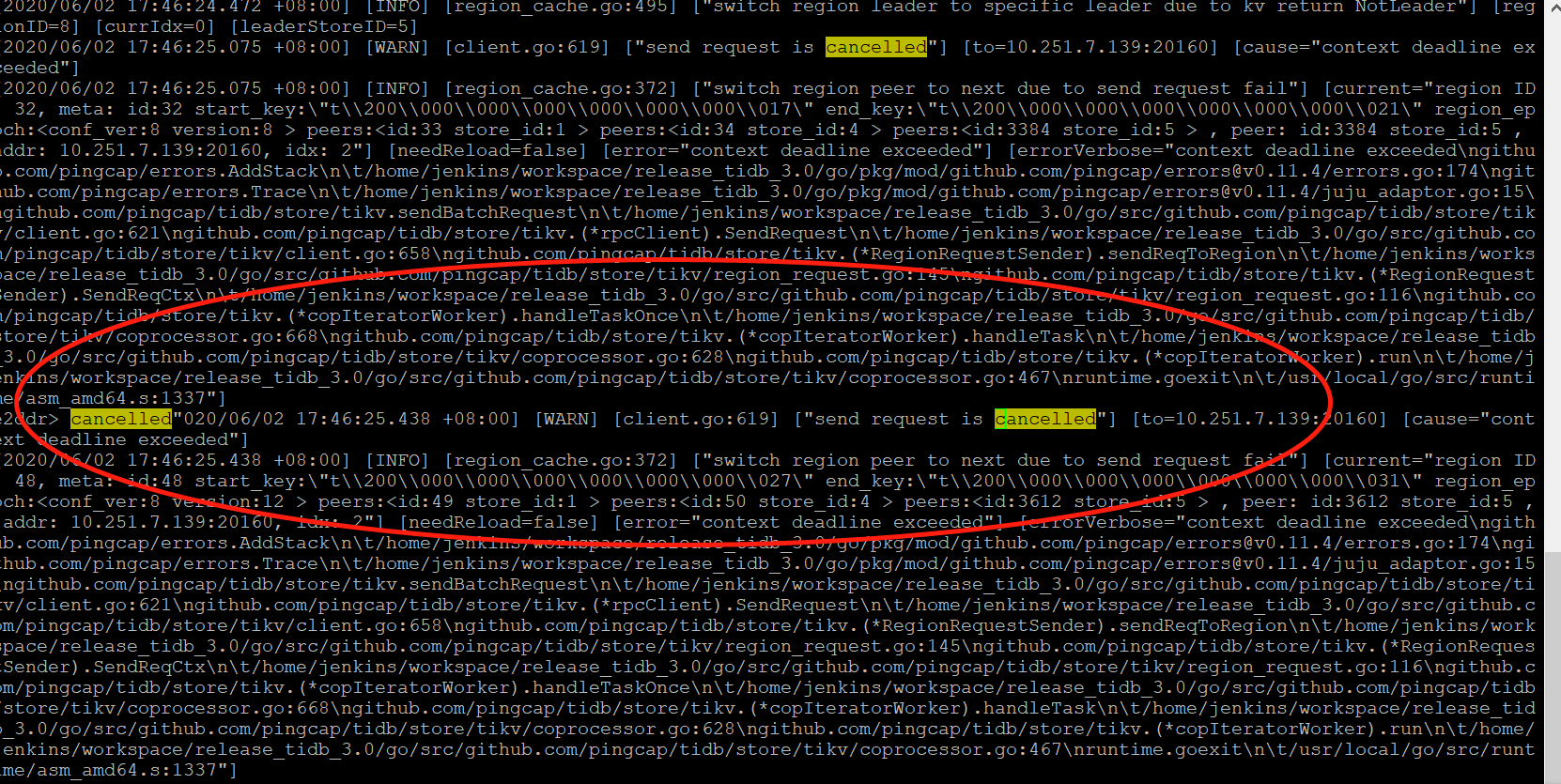
我这边使用的是v3.1.0版本
集群配置:8core-32G-100G
你好,
- 辛苦上传下 overview 面板的所有监控项
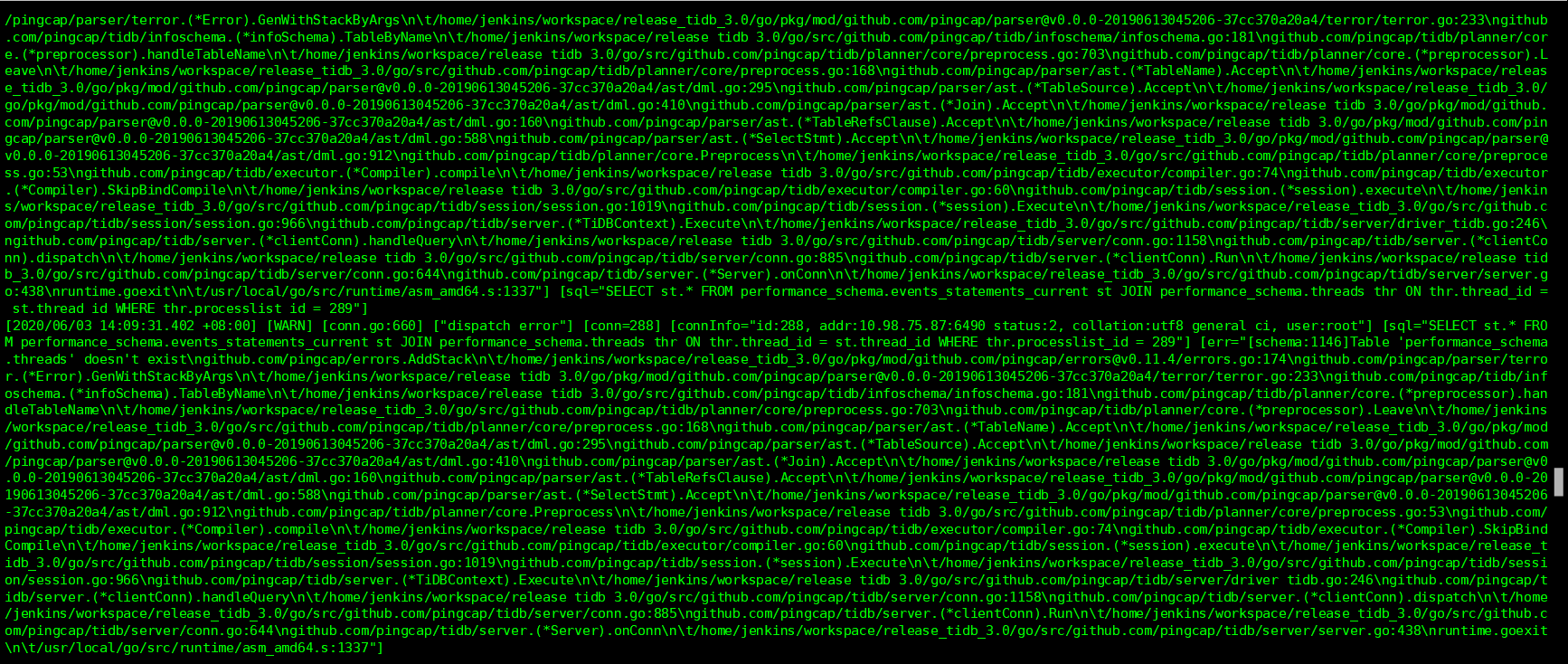
- 上传下 7.137:2379 pd 服务是否正常,图 1 应该是 tikv 的 log,访问该端口失败。
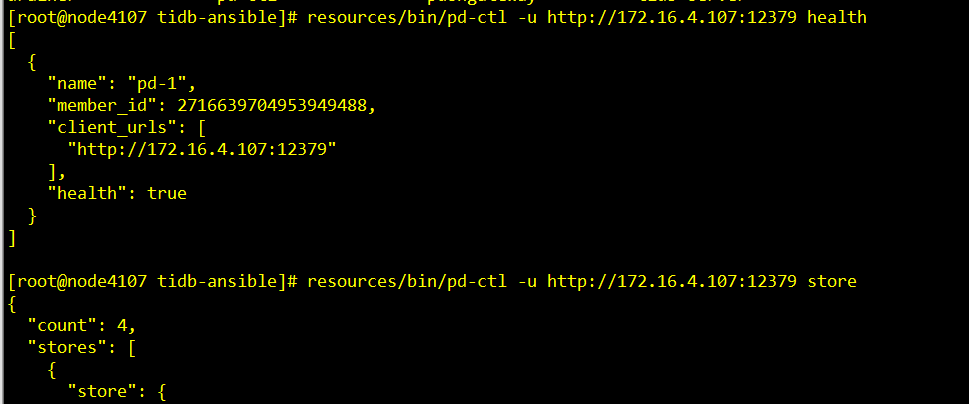
- 反馈下 pd-ctl stor / member /health 的信息
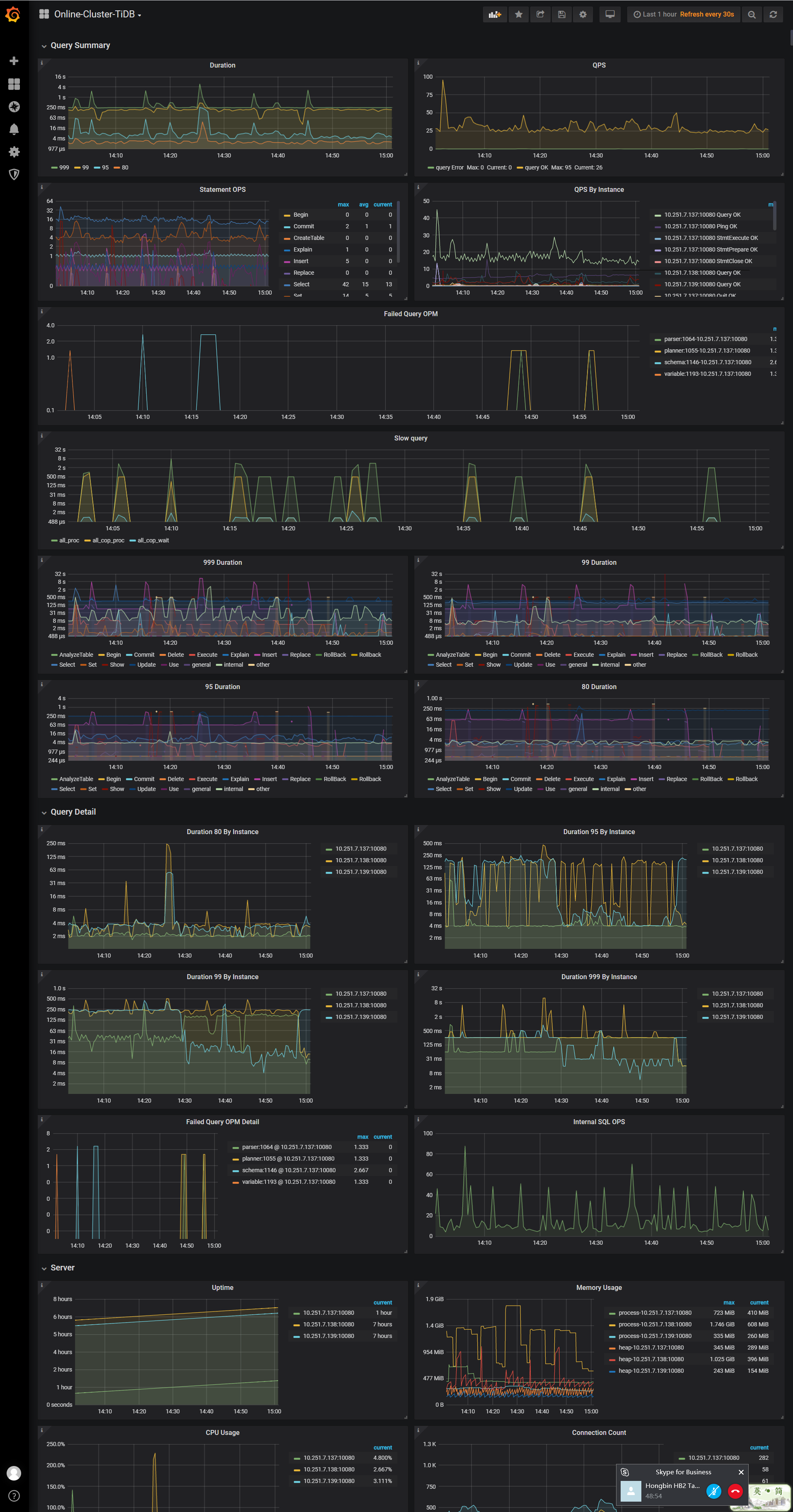
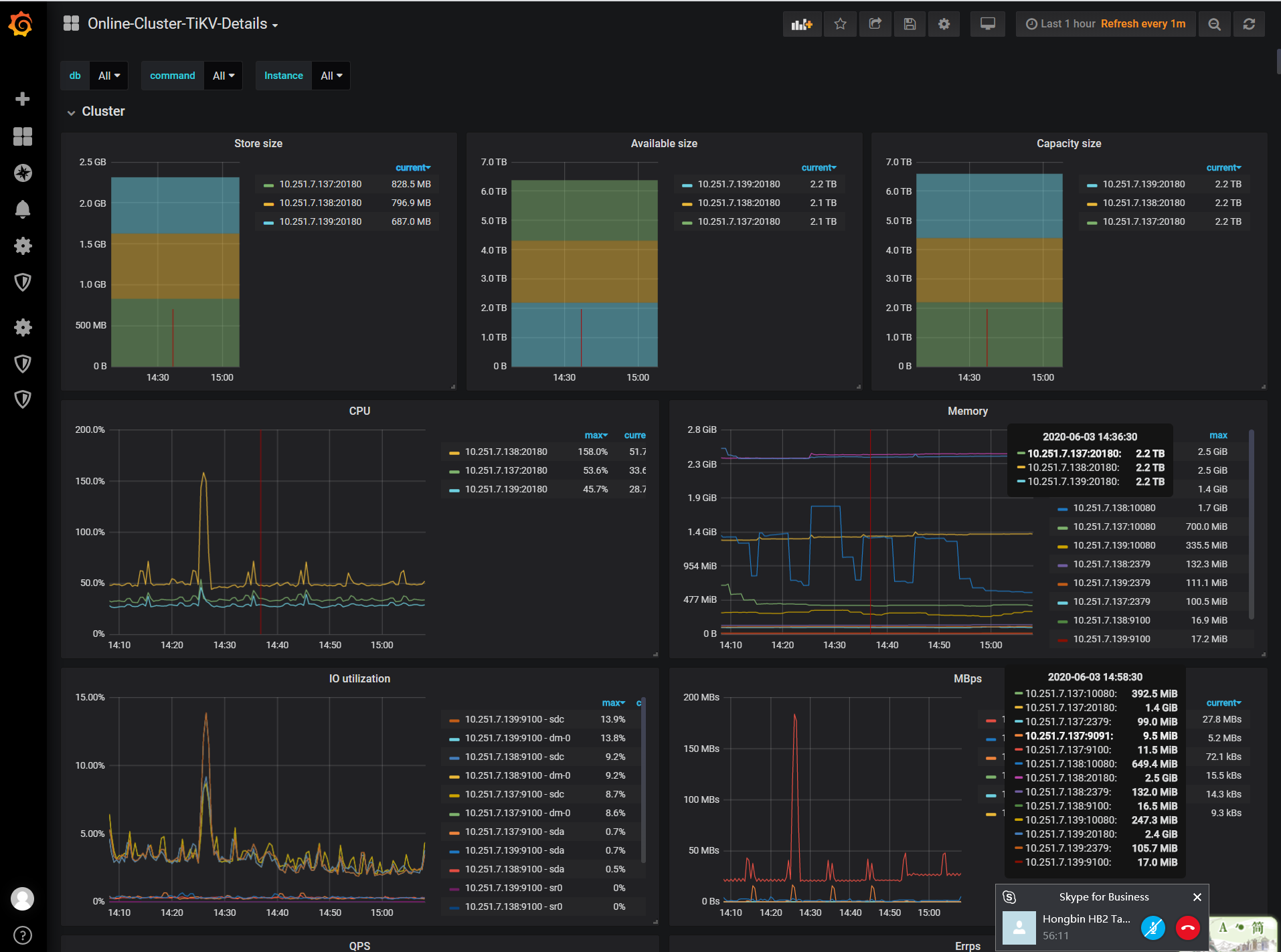
- 请上传问题发生时的监控信息 over-view,tidb。detail-tikv,多谢。 可以使用以下方法截取长图
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
-
麻烦上传问题发生前后这段时间的 tidb.log , tikv.log ,pd.log 日志多谢。
-
请问是什么版本? 在什么环境安装的? 比如物理机,虚拟机或者dociker环境?


看监控,tidb 节点 down 了,请上传down 前后的 tidb.log 日志,多谢。
-
查看 tidb 在问题发生时 重启
-
查看 /var/log/message日志,问题发生时,tidb,tikv,pd都重启
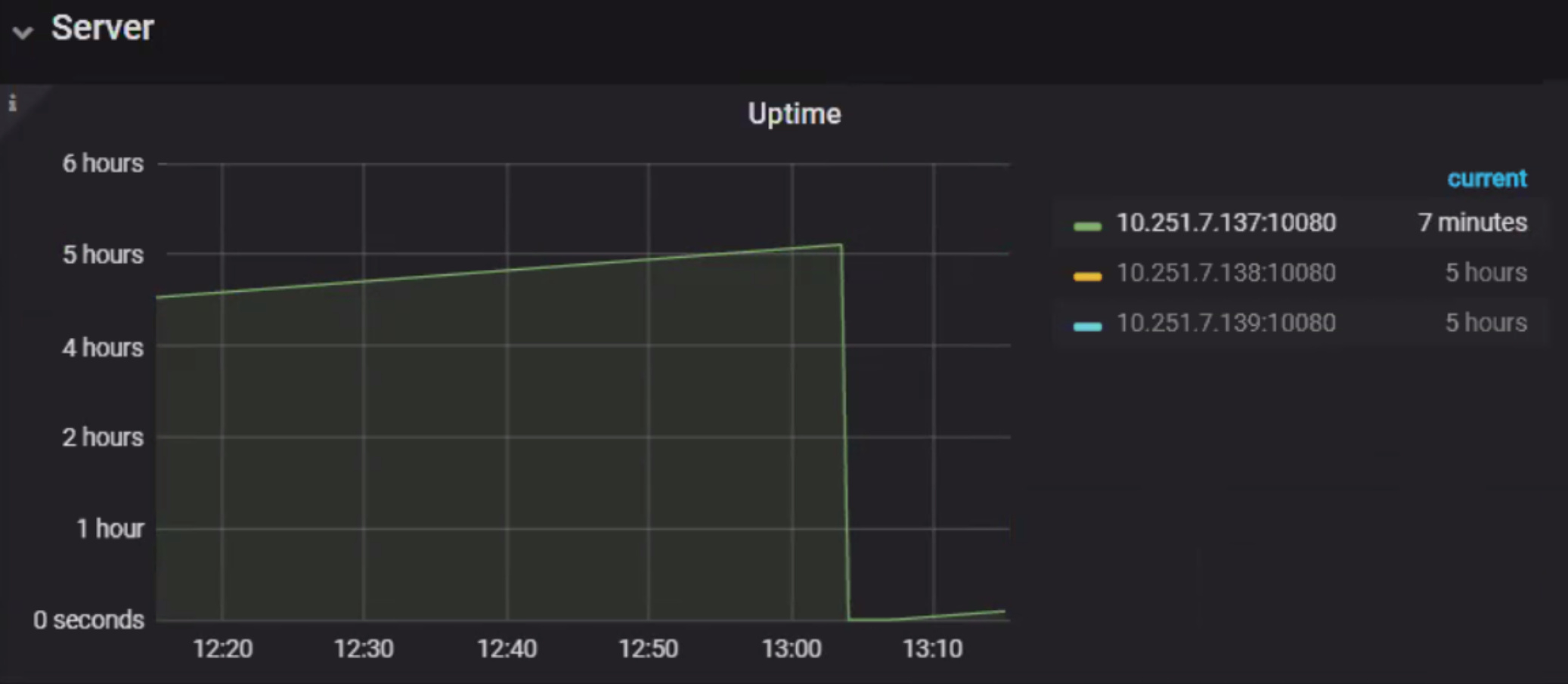
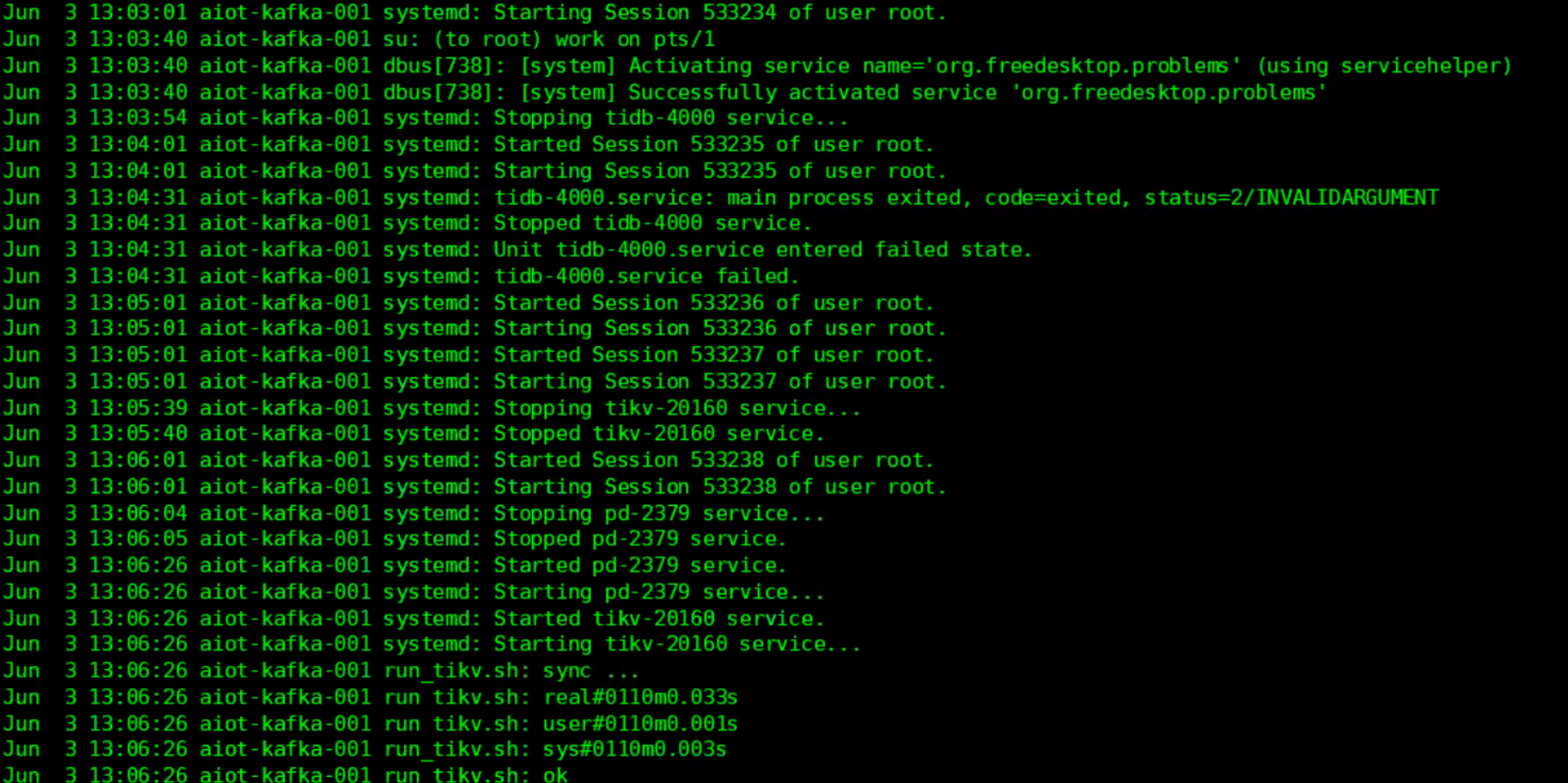
- 当前没有系统的监控,请配置服务器监控,查看问题发生时,系统资源是否有使用满的情况,多谢。
希望PingCAP能将这些报错信息进行分析,以便遇到同样问题时立即定位问题,处理问题。
没明白你的意思,上面的分析不行吗? 你想要什么样的分析?
就是要根据报出来的错,直接能定位问题,才能解决问题呀
这个报错是一个通用的报错,您可以多了解下。另外,我们也会不断收集案例,来考虑完善,多谢您的建议。
hi, peer is not leader 是一个比较正常的输出,一般情况下 tidb 遇到这个“错误”会自动重试,不会带来业务层问题。