[2020/06/01 06:38:06.120 +00:00] [ERROR] [transport.rs:137] [“resolve store address failed”] [err=“Other(”[src/server/resolve.rs:72]: store is tombstone [\“id](file:///%22id): 20847616 address: [\\\“10.121.93.145:20160\\\](file:///%2210.121.93.145:20160/)” state: Tombstone version: [\\\“4.0.0\\\](file:///%224.0.0/)” status_address: [\\\“10.121.93.145:20180\\\](file:///%2210.121.93.145:20180/)” git_hash: [\\\“198a2cea01734ce8f46d55a29708f123f9133944\\\](file:///%22198a2cea01734ce8f46d55a29708f123f9133944/)” start_timestamp: 1590741278 last_heartbeat: 1590897345796583001\”")"] [store_id=20847616]
[2020/06/01 06:56:21.246 +00:00] [ERROR] [util.rs:327] [“request failed”] [err=“Grpc(RpcFailure(RpcStatus { status: 2-UNKNOWN, details: Some(“invalid store ID 20847616, not found”) }))”]
[2020/06/01 09:36:33.687 +00:00] [WARN] [endpoint.rs:527] [error-response] [err=“Region error (will back off and retry) message: “to store id 20847616, mine 22290001” store_not_match { request_store_id: 20847616 actual_store_id: 22290001 }”]
尝试重启pd和db,结果pd正常,db重启失败
[2020/06/01 10:11:45.899 +00:00] [WARN] [backoff.go:304] [“pdRPC backoffer.maxSleep 40000ms is exceeded, errors:\
loadStore from PD failed, id: 20847616, err: rpc error: code = Unknown desc = invalid store ID 20847616, not found at 2020-06-01T10:11:41.311154285Z\
loadStore from PD failed, id: 20847616, err: rpc error: code = Unknown desc = invalid store ID 20847616, not found at 2020-06-01T10:11:44.034784863Z\
loadStore from PD failed, id: 20847616, err: rpc error: code = Unknown desc = invalid store ID 20847616, not found at 2020-06-01T10:11:45.899357952Z”]
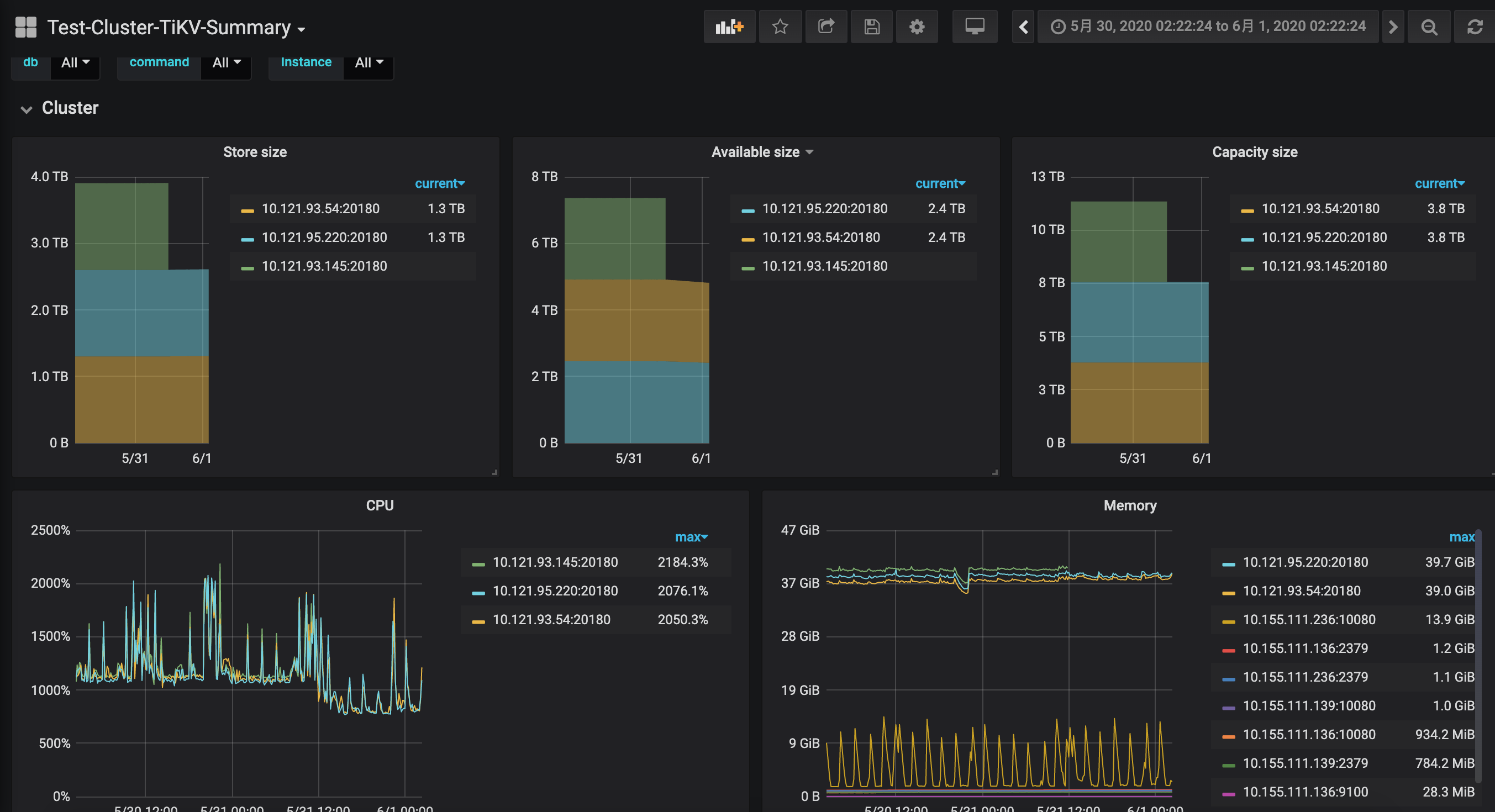
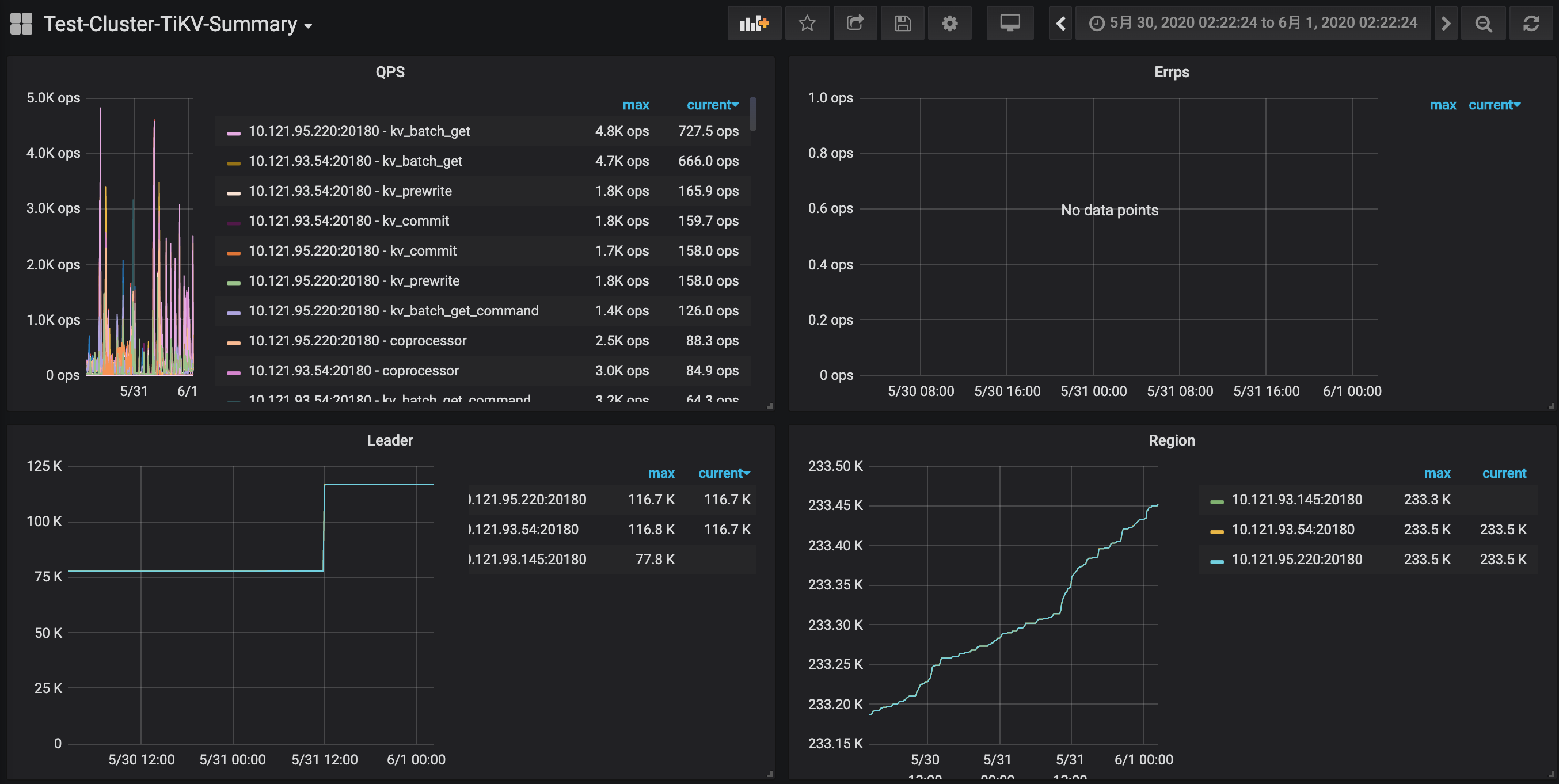
缩容调用delete store id以后,节点的region size没有正常降低,于是用了强制下线api,看到变成tombstone以后,在原ip上扩容,启动起来看到日志中有大量store is tombstone错误,于是执行了remove tomb,然后就出现大量ip校验错误,集群压力变大无法访问
在之后做了很多操作,停掉扩容的kv节点,重启pd,重启db失败,挂了一个,剩余两个没动,报loadStore from PD failed, id: 20847616, err: rpc error: code = Unknown desc = invalid store ID 20847616, not found,重启kv,tikv-ctl修复,这一系列操作以后中间挂掉的db节点还是启动失败,接着查各种资料接近半个小时以后突然发现挂掉的db节点可以访问了,然后再把扩容的kv节点启动起来,发现就正常了