为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:V3.1.1
- 【问题描述】:在排查报警:TiKV_server_report_failure_msg_total时,发现监控中PD->Heartbeat->Region heartbeat repart面板(或OverView->PD->Region heartbeat repart面板)显示:有两个store节点 350+ opm,一个store节点小于10 opm, 请教是否显示集群TiKV和PD之间的通信出现了问题,TiKV和PD的负载都不高。
报警项的值:
Region heartbeat repart监控截图:
顺便问一下,这个面板监控数据的单位是:每秒TiKV和PD之间的心跳次数吗?
overview.pdf文档
xft-cluster-overview_2.pdf (4.7 MB)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
1 个赞
qizheng
(qizheng)
2
Region heartbeat report 统计的是一分钟 TiKV 向 PD 发送的心跳个数
由于上报有一定周期性,可能 current 当前值在不同的 store 之间存在一定差异,通过监控的 Store Status 看到三个 store 都是 Up 的正常状态,表示 TiKV 和 PD之 间的通信是正常的
另外需要关注 store 的状态变化,如果通信异常,监控会显示该 store 的状态为 disconnected
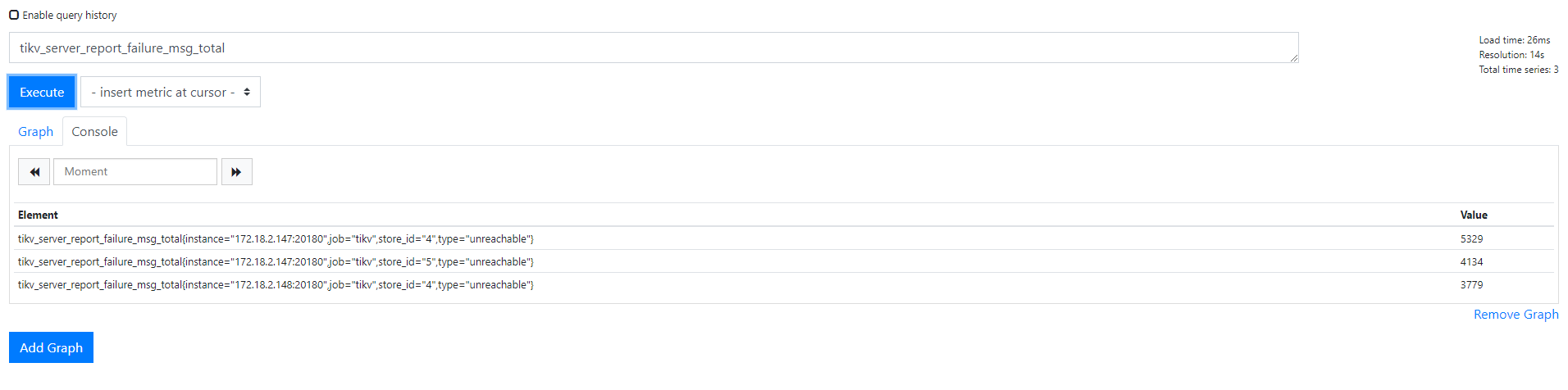
关于tikv_server_report_failure_msg_total
官方介绍:
重要级别报警项
对于重要级别的报警,需要密切关注异常指标。
TiKV_server_report_failure_msg_total
- 报警规则:
sum(rate(tikv_server_report_failure_msg_total{type="unreachable"}[10m])) BY (store_id) > 10
- 规则描述:表明无法连接远端的 TiKV。
- 处理方法:
- 检查网络是否通畅。
- 检查远端 TiKV 是否挂掉。
- 如果远端 TiKV 没有挂掉,检查压力是否太大,参考
TiKV_channel_full_total 处理方法。
目前,集群pd和tikv之间通信也正常,TiKV也没有挂掉,TiKV压力也不大,为什么会有这个报警呢?您好,有什么建议吗?指导排查一下问题。谢谢。
1 个赞
qizheng
(qizheng)
4
这个告警对应的 Grafana 监控是 TiKV-Details – Errors – Server report failures
查看监控面板确认哪些 tikv 之间存在 failure;可以选择更长的时间范围,查看过去是否经常出现,偶尔少量出现,可能是网络方面的原因,比如网络存在延迟抖动或者丢包错误,会导致 TiKV 之间的 grpc 连接中断
1 个赞
350+opm,其中opm是什么意思?是什么单词的缩写呢?谢谢!
system
(system)
关闭
8
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。