查了一些文档,没找到在4.0下部署tispark的相关文档,有没有详细的部署tispark的步骤?
- 请问,是使用 tiup 部署吗?
tispark可以用tiup部署吗?如果可以,该怎么做?
这个文档其实我看过很多遍了,不是很明白
我下载了spark-2.4.5-bin-hadoop2.7.tgz和 tispark-core-2.1.9-spark_2.4-jar-with-dependencies.jar,这样搭配对吧?
搭配方式可以看下文档中的描述,很清晰哈。
现有 TiSpark 2.x 版本支持 Spark 2.3.x 和 Spark 2.4.x。如果你希望使用 Spark 2.1.x 版本,需使用 TiSpark 1.x。
tiup 不支持部署 tispark,tispark 部署方式在文档中也是有体现的。如果部署中遇到什么具体问题,可以贴出来看下
已经部署了两个slave节点的spark,测试了spark-sql是能查询到数据的
疑问是:
spark.tispark.pd.addresses 192.168.1.100:2379
这行配置,我有多个pd的地址,在slave节点上,任意选一个pd地址,还是每个slave节点选不同的pd地址?


同样的sql查询语句,为什么执行时间差别这么大? 我有两个spark slave节点,两个tiflash节点。
需要指定所有的 pd 地址,并用逗号隔开。
至于不同的运行时间,应该是 tispark 的 plan 不如 tidb 所做的优化,可以通过 explain select … 语句来看一下 TiDB 和 TiSpark 分别选择了什么执行计划。
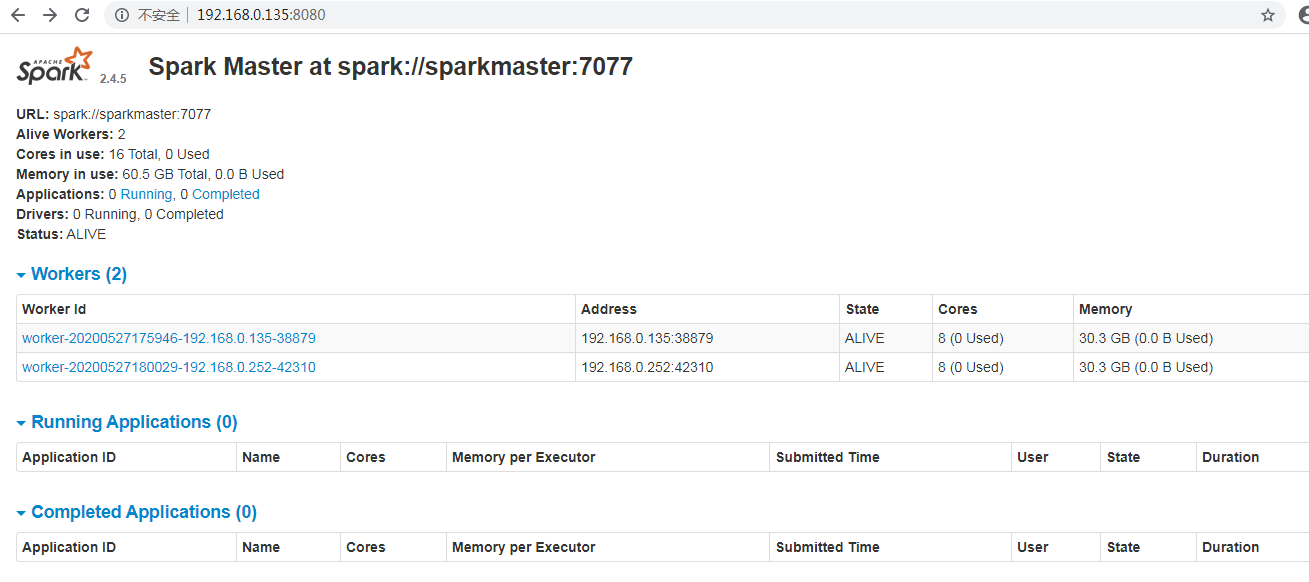
正常的
若使用 spark-shell/spark-sql,应该会在 running application 处看到对应的 spark-shell/spark-sql 应用。
若没有看到,可能你的 spark-shell 并没有连接到 spark 集群。请确认使用了 --master 参数指定了你的 spark master 地址。
谢谢,我不知道还要使用–master参数,所以没有看到running applications里有东西,经过您的指点,我使用了–master参数之后,可以在running applications处看到有东西在跑。 但是还有个疑问,我启动了一个spark-sql之后,看到它是running,再另一台机上启动了另一个spark-sql之后,看到它在waiting,只有前一个running的结束后,waiting的才会变成running,这个正常吗?也就是同时只能有一个running?