为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.11
- 【问题描述】:
表有48个字段,索引12个,一半是组合索引,记录数7500W+,语句用到的字段及索引截取信息如下:
CREATE TABLE `a` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
... ...
`created_at` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `userId` (`user_id`),
KEY `idx_to_createdat` (`created_at`),
... ...
) ENGINE=InnoDB DEFAULT CHARSET=utf8
以下两个SQL是等价的,一个使用in,一个使用exists,in里面的记录数在100条左右,子查询中的表 t 与 原表 a 是同一张表,起的不同别名
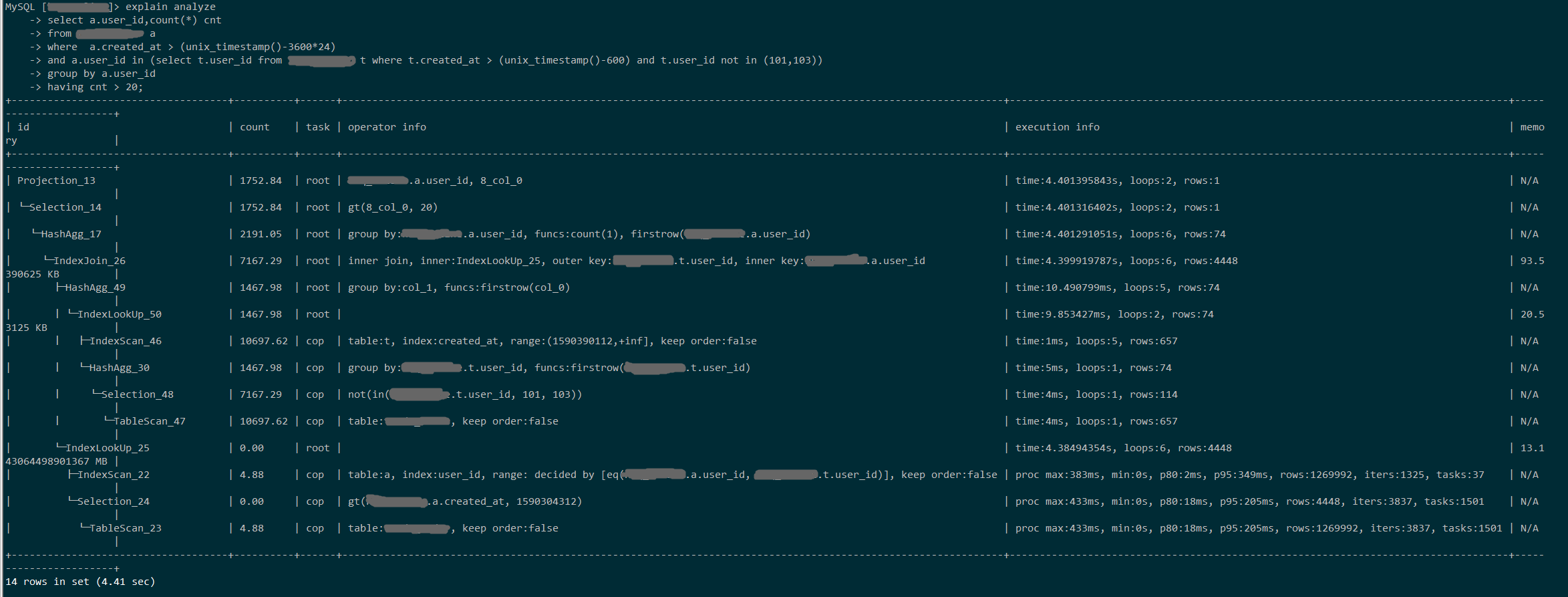
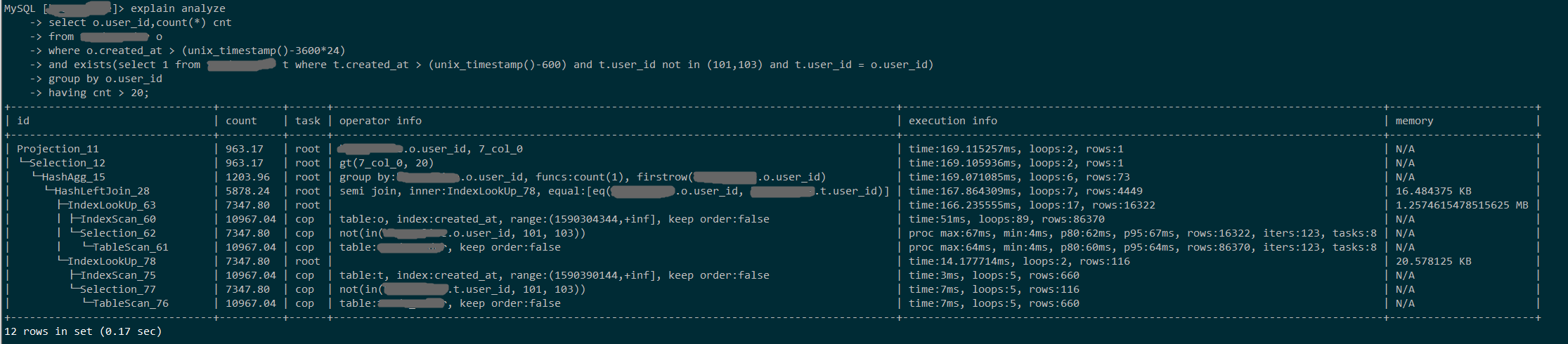
表 a 也手工执行过analyze table,统计信息应该没问题。是不是tidb对in的优化有点问题啊?