通过第三方工具,执行下面三个语句都没问题。可能是这个工具有每次显示1000条的限制,导致没有内存溢出的。
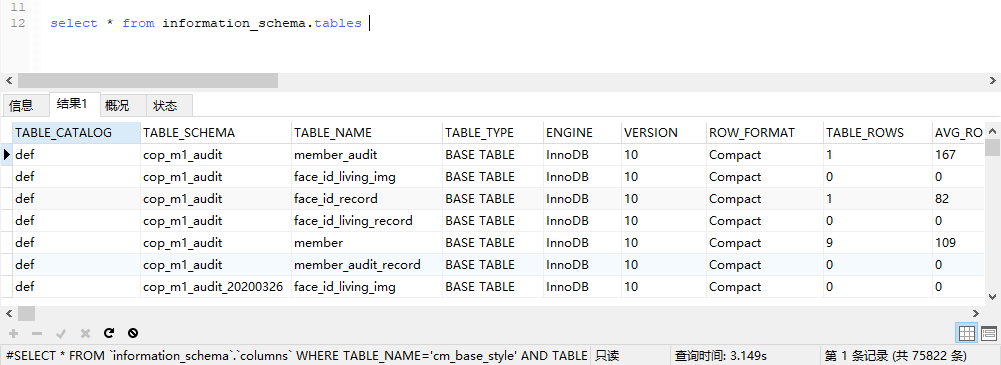
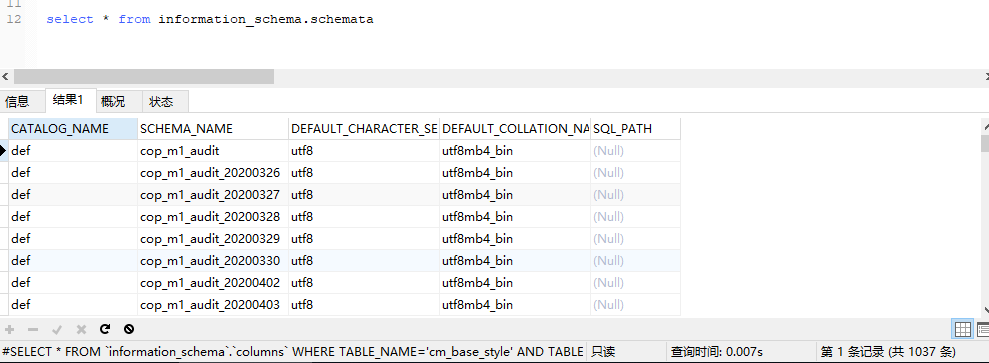
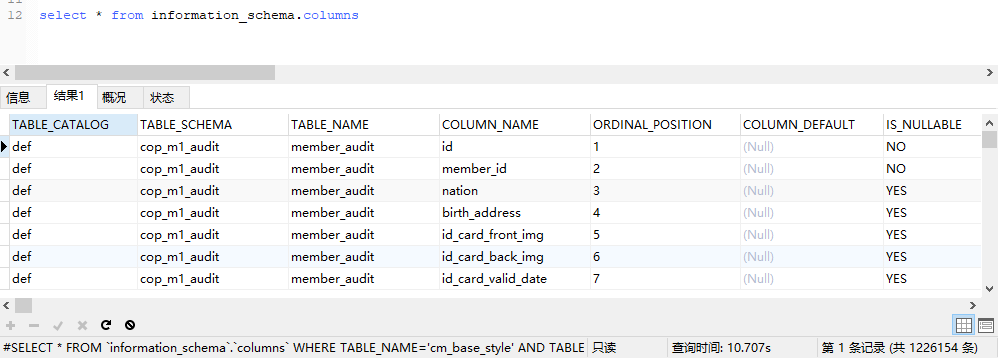
这几个表很特殊是内存表,机制是要吧整个结果算出来都放到内存里,才向外返回数据,其实 limit 是没用的。。
可以帮观察下 执行 select * from information_schema.columns 时的实例内存上涨情况?
目前初步看大概率和这个有关,其实理想情况应该也和正常表一样流式有部分结果就先返回一部分。。而不是都算出来才返回。。。(刚好您这个 case 分区很多并且表的也比较多列这个问题比较明显)
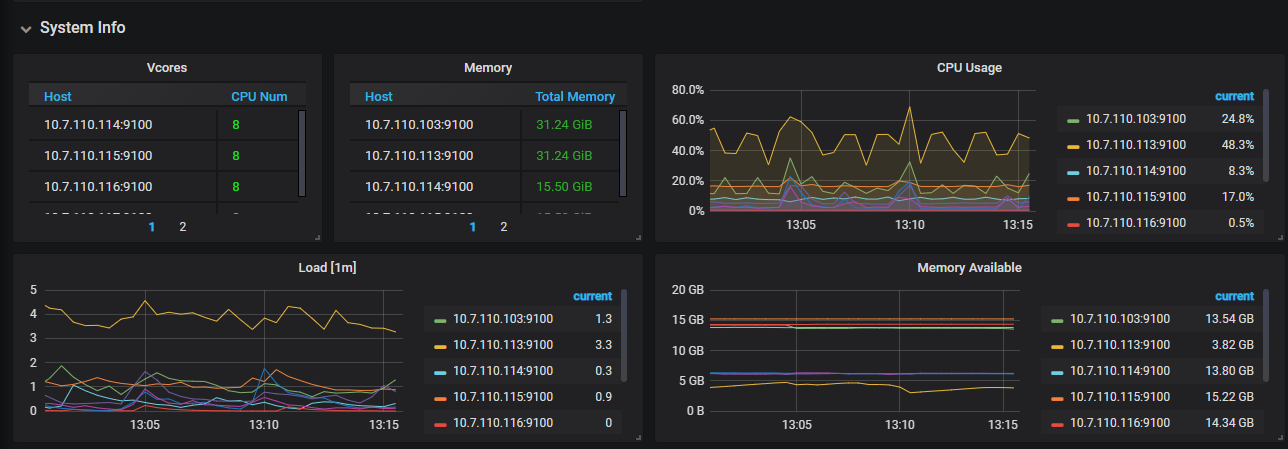
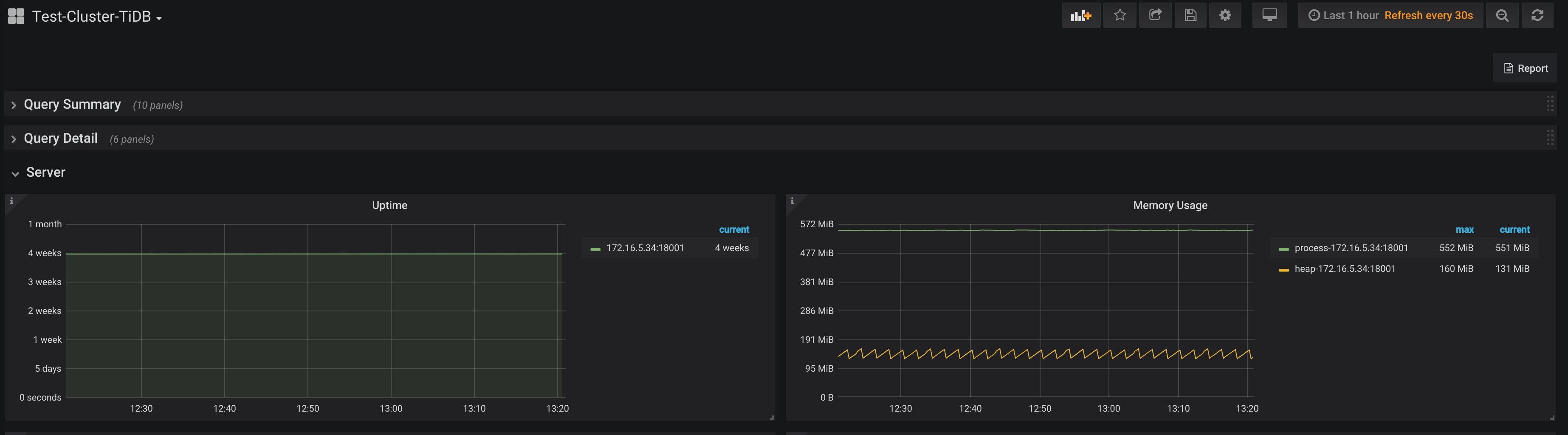
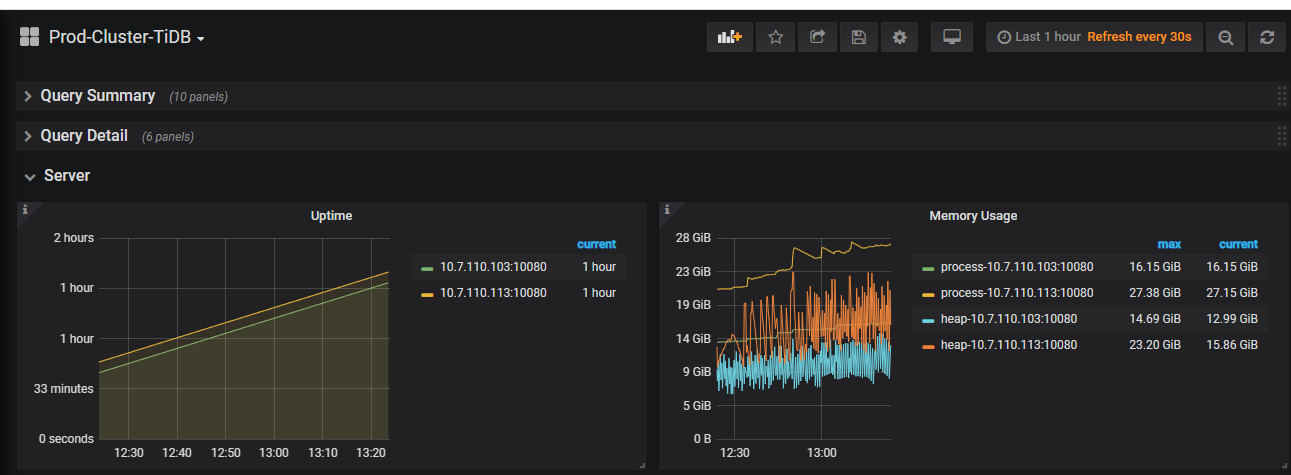
这个 select * from information_schema.columns 执行的是 10.7.110.113 那机器吗?看上去一直有 10G 左右的抖动
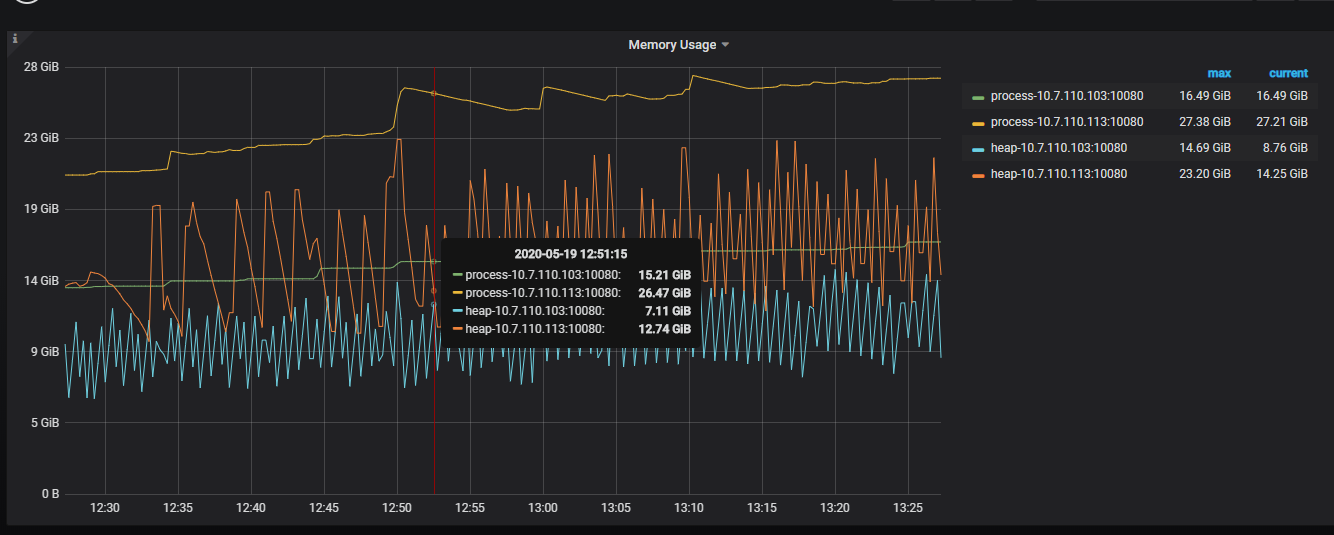
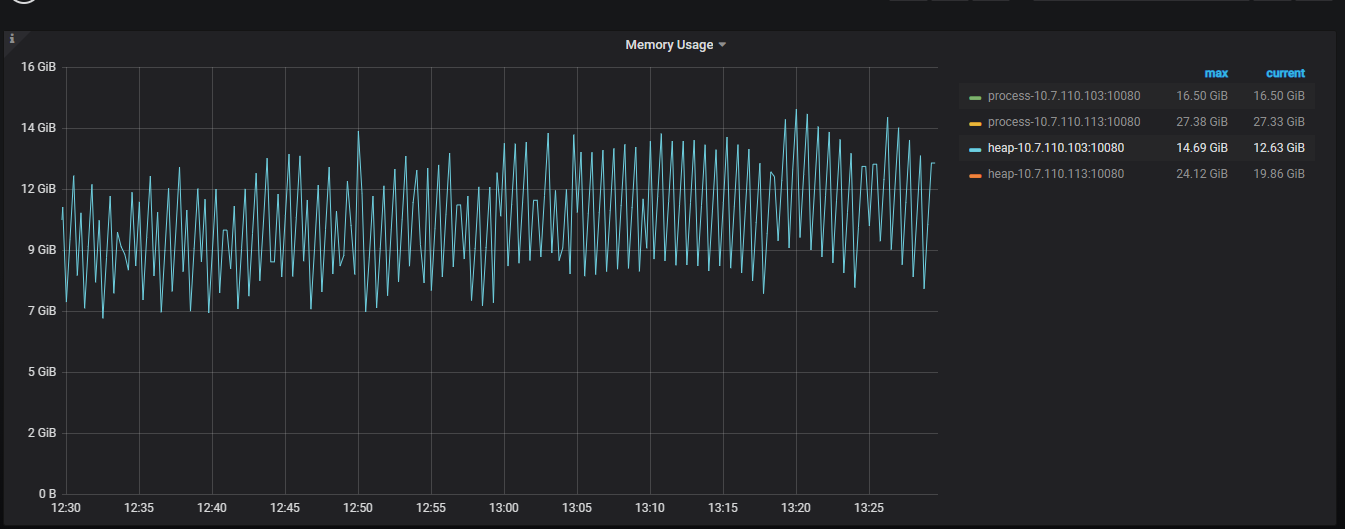
那基本确定就是 information_schema.columns 需要后续改进避免在超大结果时持续占用内存了,这个问题同样存在与 tables 等其他表, navicate 链接时一起执行就比较容易 oom。
这个我们需要设计下看下怎么改进,抱歉给您带来的不便
主要看 heap-113
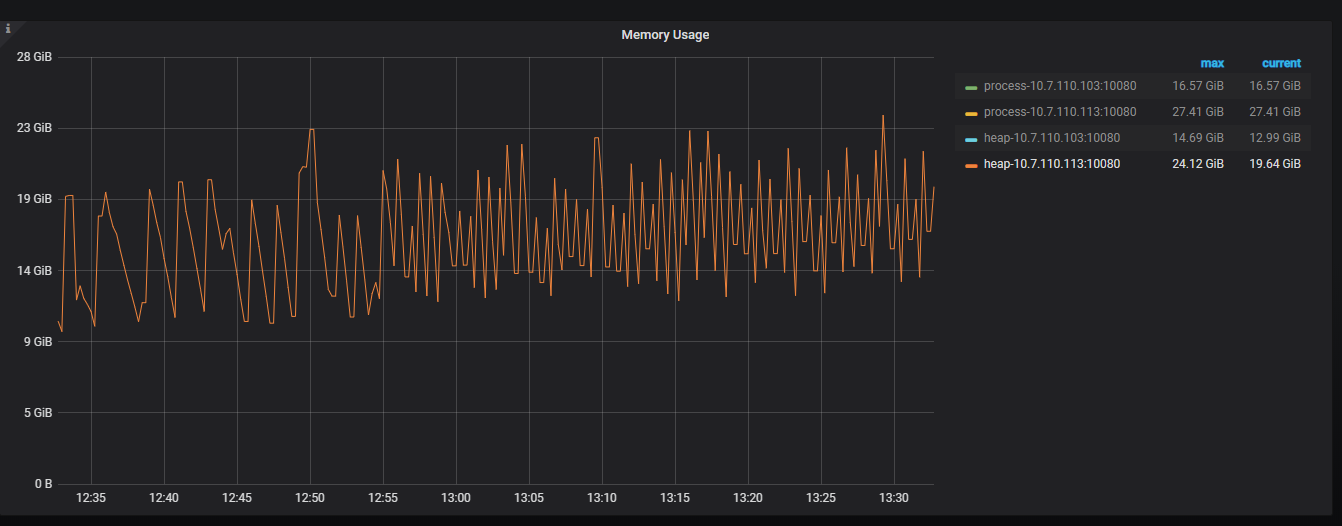
如果有任务也会撑到19G 那如果干好同时遇上上面 heap 上的 columns 12G 是会比较容易 oom 的。。
因为您表和分区太多,如果是人工查询建议可以使用
show tables 来查看表名称列表
show create table <table> 来查看表结构
information_schema 返回结果比较结构化,方便类似工具类或框架读取,但目前内存表实现在表特别多时不太高效需要要我们后续改进
收到,我们这边也想办法改进一下方案,看看是否真的需要采用这个方案,看下能不能采用备份再还原的方式来查找历史数据,而不是每天都建一个副本,毕竟这些数据采集过来也不一定什么时候能用上。
感谢回复,期待你们的改进!
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。